







LLM 是利用深度学习和大数据训练的人工智能系统,专门设计来理解、生成和回应自然语言。这些模型通过分析大量的文本数据来学习语言的结构和用法,从而能够执行各种语言相关任务。以 GPT 系列为代表,LLM 以其在自然语言处理领域的卓越表现,成为推动语言理解、生成和应用的引擎。 LLM 在多个领域都取得了令人瞩目的成就。在自然语言处理领域,GPT 系列模型在文本生成、问答系统和对话生成 等任务中展现出色的性能。在知识图谱构建、智能助手开发等方面,LLM 技术也发挥了关键作用。此外,它还在代码生成、文本摘要、翻译等任务中展现了强大的通用性。
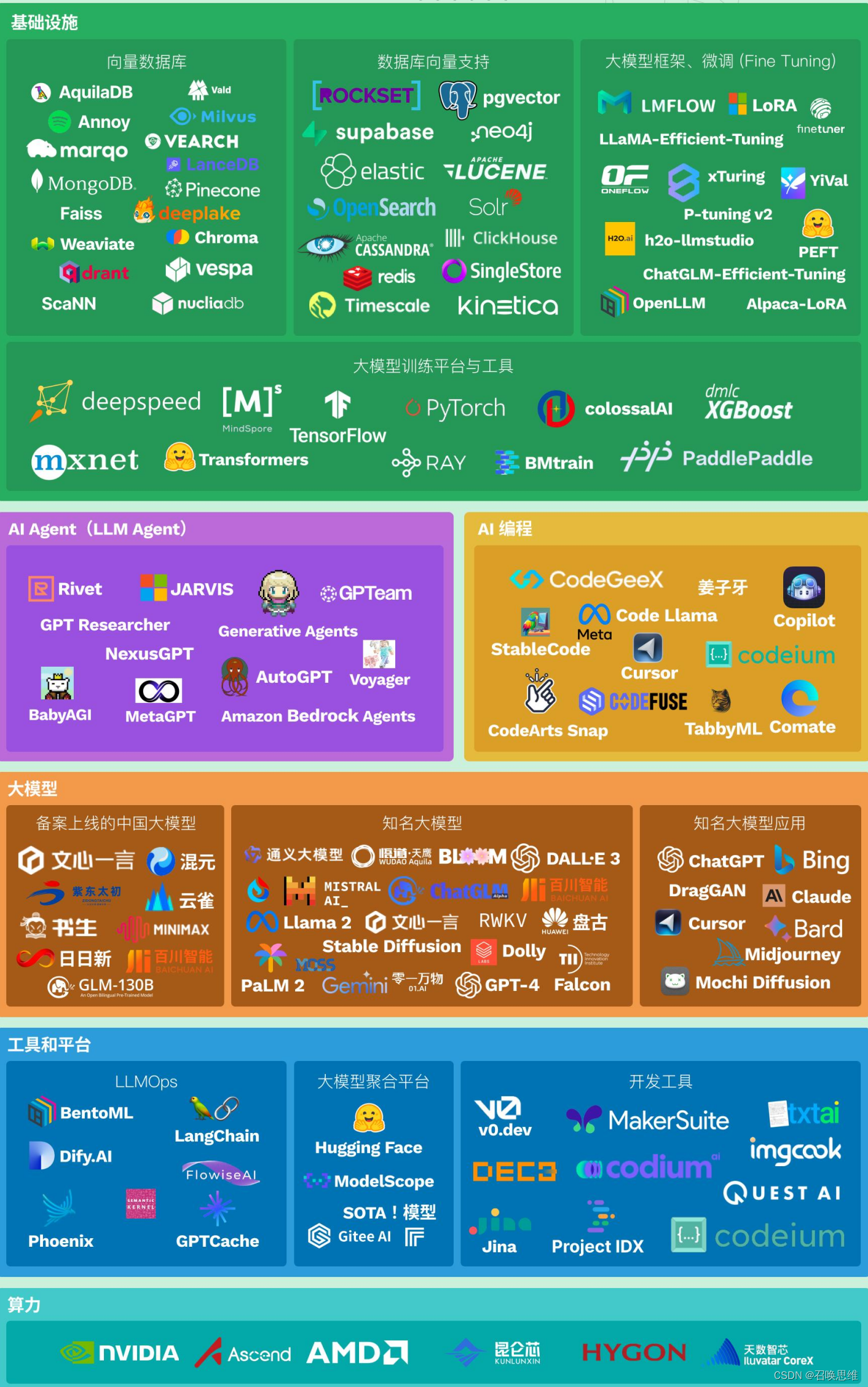
1)大模型图谱
2)LLM 技术背景
Transformer 架构和预训练与微调策略是 LLM 技术的核心,随着大规模语言数据集的可用性和计算能 力的提升,研究者们开始设计更大规模的神经网络,以提高对语言复杂性的理解。
GPT (Generative Pre-trained Transformer) 的提出标志着 LLM 技术的飞速发展,其预训练和微调的 方法为语言任务提供了前所未有的性能,以此为基础,多模态融合的应用使得 LLM 更全面地处理各种信息,支持更广泛的应用领域。
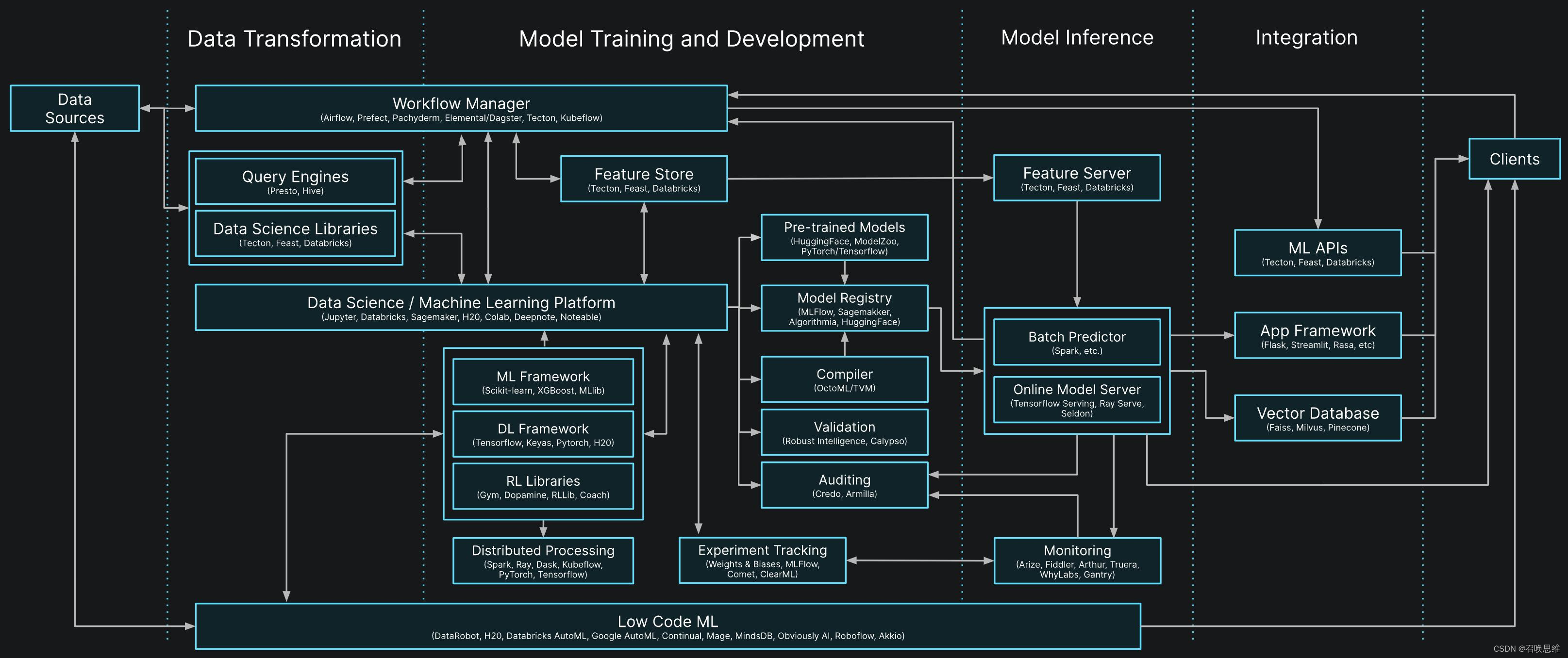
3)LLM 基础设施

3.1)LLM 基础设施:向量数据库/数据库向量支持
向量数据库是专门用于存储和检索向量数据的数据库,它可以为 LLM 提供高效的存储和检索能力。通过数据向量化,实现了 在向量数据库中进行高效的相似性计算和查询。 根据向量数据库的的实现方式,可以将向量数据库大致分为两类:
1、原生向量数据库
原生的向量数据库专门为存储和检索向量而设计, 所管理的数据是基于对象或数据点的向量表示进行组织和索引。 包括等均属于原生向量数据库。

2、添加向量支持的传统数据库
除了选择专业的向量数据库,对传统数据库添加 “向量支持”也是主流方案。比如等传统数据库均已支持向量检索。

3.2)LLM 基础设施:大模型框架及微调 (Fine Tuning)
大模型框架指专门设计用于构建、训练和部署大型机器学习模型和深度学习模型的软件框架。这些框架提供了必要的工具和库,使开发者能够更容易地处理大量的数据、管理巨大的网络参数量,并有效地利用硬件资源。
微调(Fine Tuning)是在大模型框架基础上进行的一个关键步骤。在模型经过初步的大规模预训练后,微调是用较小、特定领域的数据集对模型进行后续训练,以使其更好地适应特定的任务或应用场景。这一步骤使得通 用的大型模型能够在特定任务上表现出更高的精度和更好的效果。
大模型框架提供了 LLM 的基本能力和普适性,而微调则是实现特定应用和优化性能的关键环节。两者相结合, 使得 LLM 在广泛的应用场景中都能发挥出色的性能。

大模型框架有哪些特点:
抽象和简化:大模型开发框架通过提供高 层次的 API 简化了复杂模型的构建过程。这些 API 抽象掉了许多底层细节,使开发者能 够专注于模型的设计和训练策略。
性能优化:这些框架经过优化,以充分利用 GPU、TPU 等高性能计算硬件,以加速模型的训练和推理过程。
易于扩展:为了处理大型数据集和大规模参数网络,这些框架通常设计得易于水平扩展, 支持在多个处理器或多个服务器上并行处理。
支持大数据集:它们提供工具来有效地加载、处理和迭代大型数据集,这对于训练大型模型尤为重要。
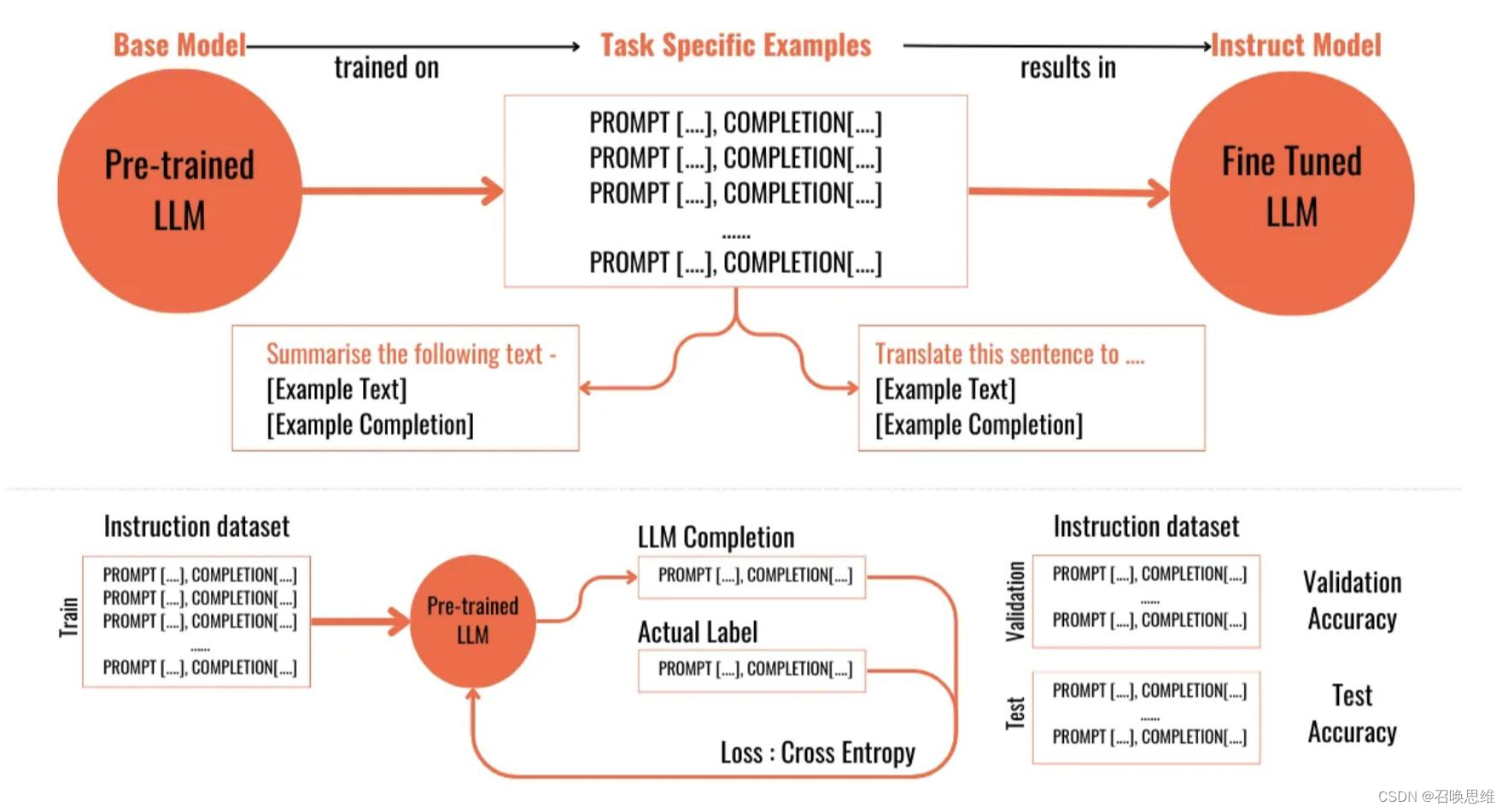
想要微调一个模型,一般包含以下关键步骤:
1.选择预训练模型:选取一个已经在大量数据上进 行过预训练的模型作为起点;
2.准备任务特定数据:收集与目标任务直接相关的 数据集,这些数据将用于微调模型;
3.微调训练:在任务特定数据上训练预训练的模型, 调整模型参数以适应特定任务;
4.评估:在验证集上评估模型性能,确保模型对新 数据有良好的泛化能力;
5.部署:将性能经验证的模型部署到实际应用中去。
3.3)LLM 基础设施:大模型训练平台与工具
大模型训练平台和工具提供了强大且灵活的基础设施,使得开发和训练复杂的语言模型变得可行且高 效。
这些工具提供了先进的算法、预训练模型和优化技术,极大地简化了模型开发过程,加速了实验周期, 并使得模型能够更好地适应各种不同的应用场景。此外,它们还促进了学术界和工业界之间的合作与 知识共享,推动了自然语言处理技术的快速发展和广泛应用。
相比前边的大模型框架和微调,一言以蔽之:平台化、灵活化

大模型训练平台与工具根据其性质不同,可分为以下几类:
1、云服务和商业平台
这些平台提供了从模型开发到部署的综合解决方案,包括计算资源、 数据存储、模型训练和部署服务。它们通常提供易于使用的界面,支 持快速迭代和大规模部署。Amazon SageMaker、Google Cloud AI Platform 和 Microsoft Azure Machine Learning 都是提供端到 端机器学习服务的云平台。
2、专业硬件和加速工具
这些工具和库专门为加速机器学习模型的训练和推理而设计,通常利 用 GPU 或 TPU 等硬件。这类工具可以显著提高训练和推理的速度, 使得处理大规模数据集和复杂模型变得可行。NVIDIA CUDA 和 Google Cloud TPU 均是此类工具。
3、开源框架和库
这类工具通常由开源社区支持和维护,提供了灵活、可扩展的工具和 库来构建和训练大型机器学习模型,如 TensorFlow 和 PyTorch 和 Hugging Face Transformers 等。
3.4)LLM 基础设施:编程语言
LLM 的训练和应用通常使用多种编程语言,取决于任务的需求和团队的偏好。
Python是LLM开发中最常用的编程语言。它的广泛使用得 益于其简洁的语法、强大的库支持(如 )和深度学习框架(如 )。
此外, AI开发领域也有新崛起的新秀语言Mojo ,C++ 有时 用于优化计算密集型任务,而 Java 在企业环境中处理模型部署和系 统集成方面常见。JavaScript 适用于 Web 环境的 LLM 应用。

4)大模型应用现状
2022 年底大模型应用 ChatGPT 发布后,点燃了世界范 围内对于大模型技术及其应用的关注和热情。2023 年, 国内外各大厂商均投身于大模型的浪潮当中,涌现了诸多 知名的大模型及应用,它们结合了文本、图片、视频、音频多种介质,在文本生成、图片生成、AI 编程等方向均 有出色的表现。
在全球范围内,已经发布了多款知名大模型,这些大模 型在各个领域都取得了突破性的进展。 处理文本数据的 GPT-4,能同时处理和理解多种类型数据的多模态模型 DALL-E 3,以及开源大模型的代表 Lllama 2 都在短时间内获得了大量关注和用户,构成了大模型领域的「第一梯队」。

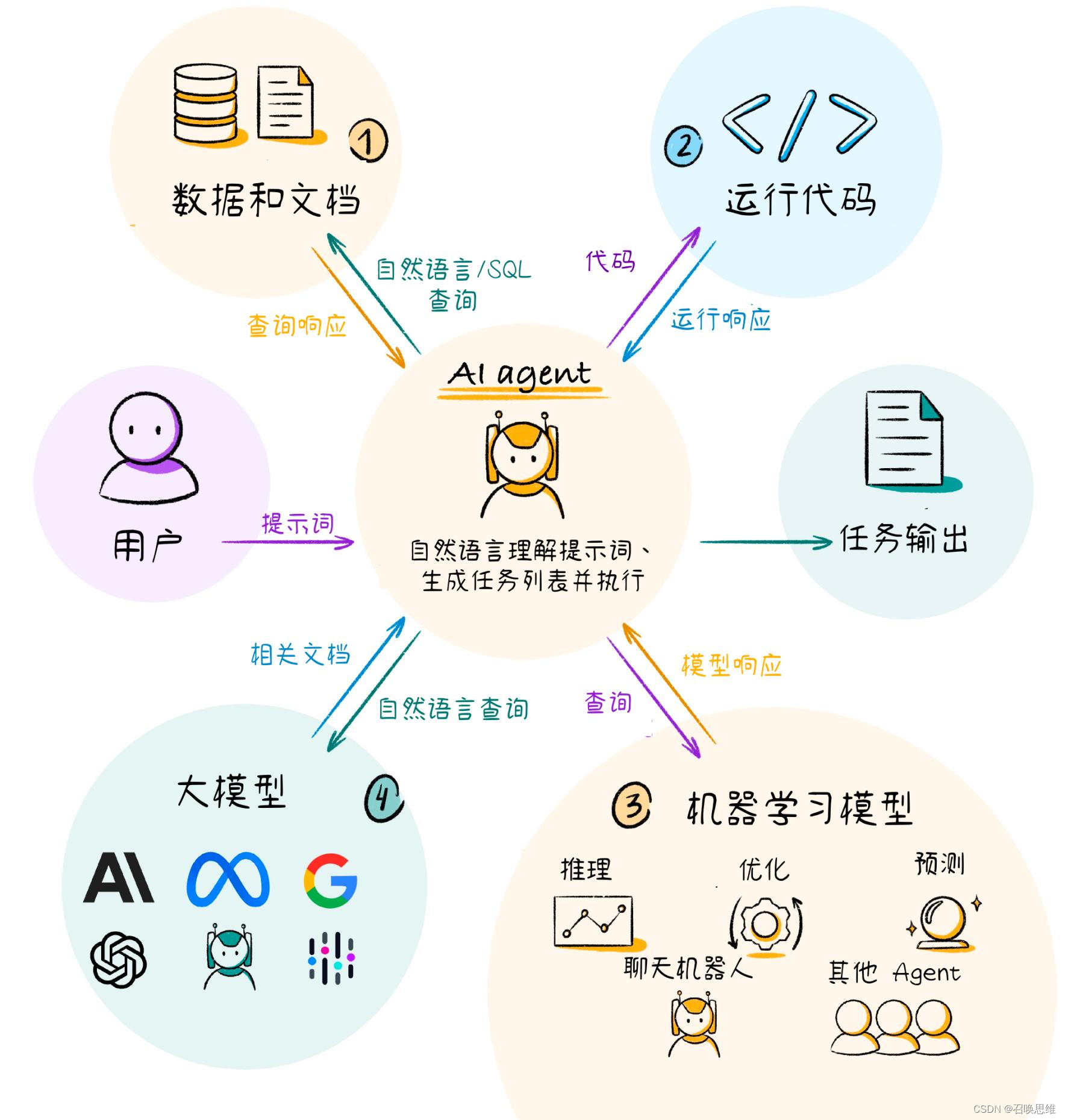
5)LLM Agent(AI Agent)
LLM Agent 是一种基于 LLM 的智能代理,它能够自主学习和执行任务, 具有一定的“认知能力和决策能力”。LLM Agent 的出现,标志着 LLM 从传统的模型训练和应用模式,转向以 Agent 为中心的智能化模 式。
LLM Agent 打破了传统 LLM 的被动性,使 LLM 能够主动学习和执行 任务,从而提高了 LLM 的应用范围和价值;它为 LLM 的智能化发展提 供了新的方向,使 LLM 能够更加接近于人类智能。
AutoGPT 就是一个典型的 LLM Agent。在给定 AutoGPT 一个自然语言目标后,它会尝试将其分解为多个子任务,并在自动循环中使用互联网和其他工具来实现该目标。它使用的是 OpenAI 的 GPT-4 或 GPT-3.5 API,是首个使用 GPT-4 执行自主任务的应用程序实例。
AutoGPT 最大的特点在于能根据任务指令自主分析和执行,当收到一个需求或任务时,它会开始分析这个问题,并且给出执行目标和具 体任务,然后开始执行。
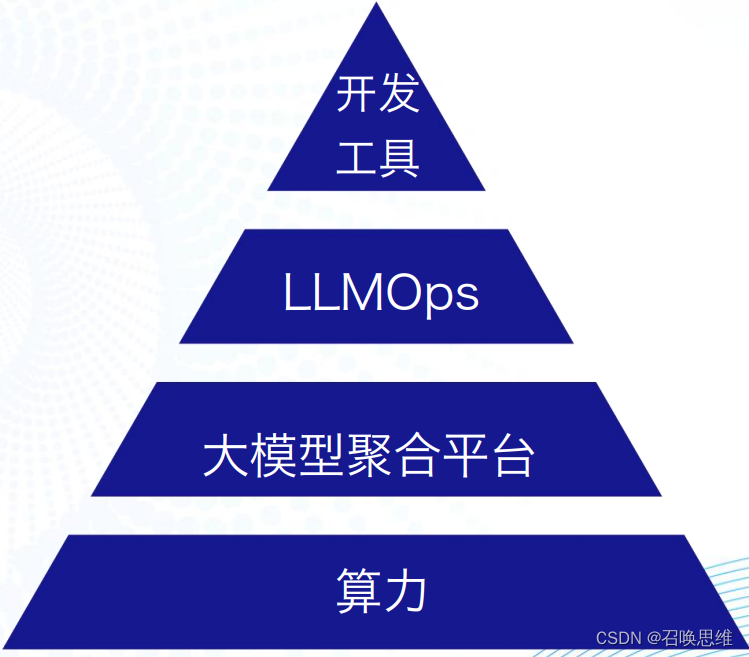
6)LLM 的工具和平台
LLMOps :LLMOps 平台专注于提供大模型的部署、运维和优化服务,旨在帮助企业和开发者更高效地管理和使用这些先进的 AI 模型, 快速完成从模型到应用的跨越,如Dify 、LangChain 等。
大模型聚合平台:主要用于整合和管理多个大型机器学习模型,在聚合平台之上,衍生出 MaaS(Model-as-a- Service,大模型即服务)的服务模式——通过提供统一的接口和框架,以更高效地部署、运行和优化这些模型,Hugging Face、Replicate 以及Gitee AI均为Maas平台 。
开发工具:其它开发相关的 LLM 工具,如云原生构建多模态AI应用的工具 Jina,嵌入式数据库 txtai 等。

















 9529
9529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









