







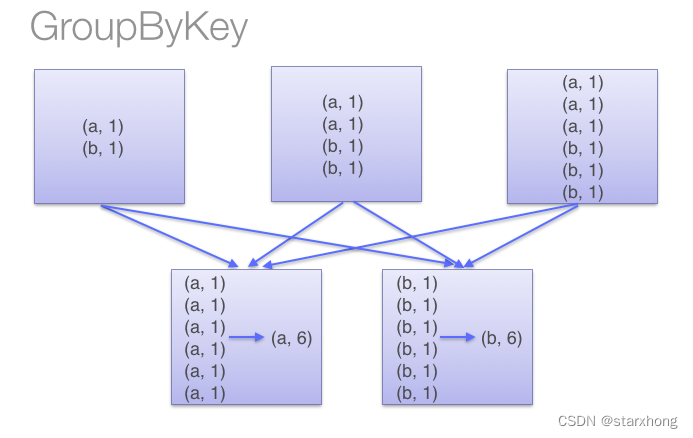
1. groupByKey Vs. groupBy
/**
* 用于对pairRDD按照key进行排序
* @author starxhong.
*/
object Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName(this.getClass.getSimpleName)
SparkSession sparkSession = SparkSession.builder().getOrCreate();
val list = List(("Tom", 8),("Bob",5),("Wade",9),("John",5),("Tom",7),("John",7))
val rdd = ss.sparkContext.parallelize(list)
pairRdd.groupByKey().mapValues(_).collect.foreach(println)
println()
pairRdd.groupByKey().mapValues(_.toList).collect.foreach(println)
println()
pairRdd.groupBy(_._1).mapValues(_).collect.foreach(println)
println()
pairRdd.groupBy(_._1).mapValues(_.toList).collect.foreach(println)
println()
pairRdd.groupBy(x => {x.toString().length}).mapValues(_.toList).collect.foreach(println)
}
}
结果:
(Tom,CompactBuffer(8, 7))
(Wade,CompactBuffer(9))
(John,CompactBuffer(5, 7))
(Bob,CompactBuffer(5))
(Tom,List(8, 7))
(Wade,List(9))
(John,List(5, 7))
(Bob,List(5))
(Tom,CompactBuffer((Tom,8), (Tom,7)))
(Wade,CompactBuffer((Wade,9)))
(John,CompactBuffer((John,5), (John,7)))
(Bob,CompactBuffer((Bob,5)))
(Tom,List((Tom,8), (Tom,7)))
(Wade,List((Wade,9)))
(John,List((John,5), (John,7)))
(Bob,List((Bob,5)))
(7,List((Tom,8), (Bob,5), (Tom,7)))
(8,List((Wade,9), (John,5), (John,7)))
groupByKey()和Groupby(),都是返回CompactBuffer,这是一个类似ArrayBuffer的结构(An append-only buffer similar to ArrayBuffer, but more memory-efficient for small buffers),区别是groupByKey()的返回(key,CompactBuffer(value1, value2, …)),groupBy()返回(key,CompactBuffer((key,value1), (key,value2), …)结构。
groupByKey是按Key进行分组,所以作用对象必须是PairRDD型的。而GroupBy分组规则需要我们自己设定,groupBy的参数可以是一个函数,该函数的返回值将作为Key。
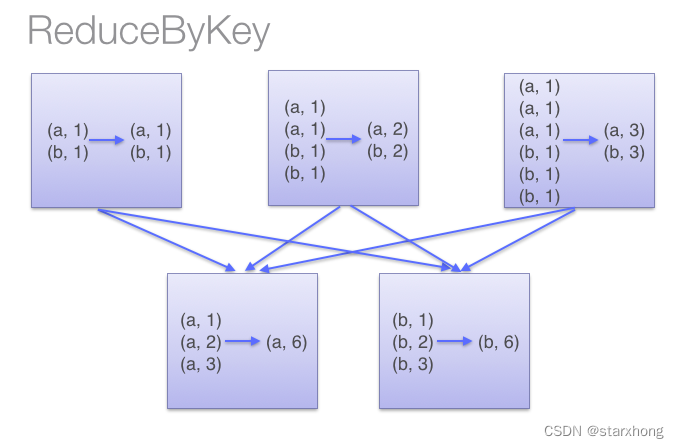
2. groupByKey Vs. reduceByKey
reduceByKey比groupBykey效率更高,主要方式是reduceByKey先worker内reduce一次,再按key进行group,而groupByKey是先group,再reduce。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









