







原文:http://www.studyai.com/article/73a1d3b70458410e
下面我们贴出使用AdamOptimizer优化器时不同的学习率下网络的性能曲线(关于详细分析,请大家到课程中心去听对应的分析)
- lr=0.0001

- lr=0.001

- lr=0.01

- lr=0.1(我们在这个学习率下运行四遍学习过程,由于网络每次的随机起始状态都不一样,所以会得到非常不一样的结果:有时收敛,有时不收敛)

- lr=0.5(一次都没收敛)

对前面的实验做一个总结

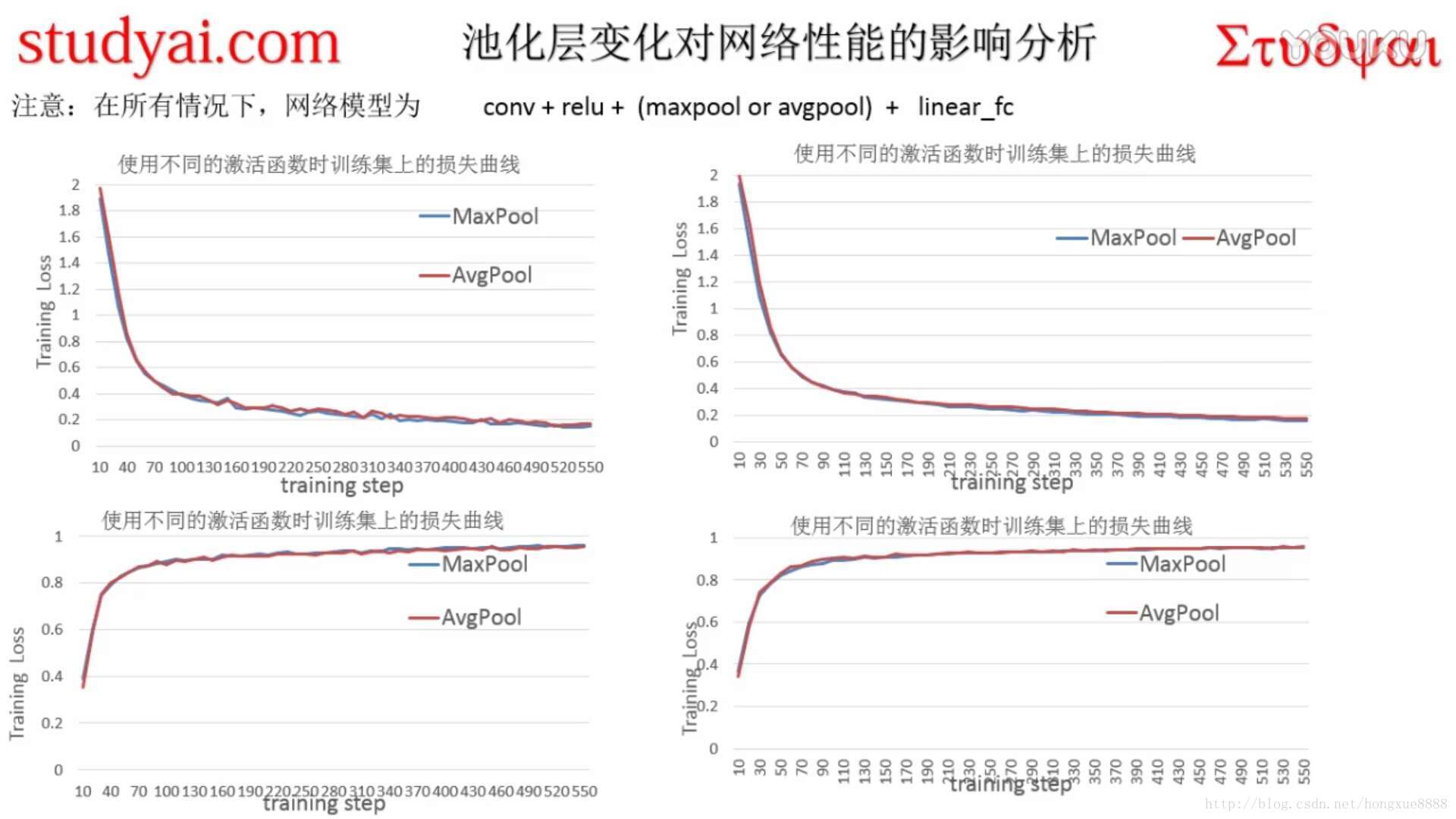
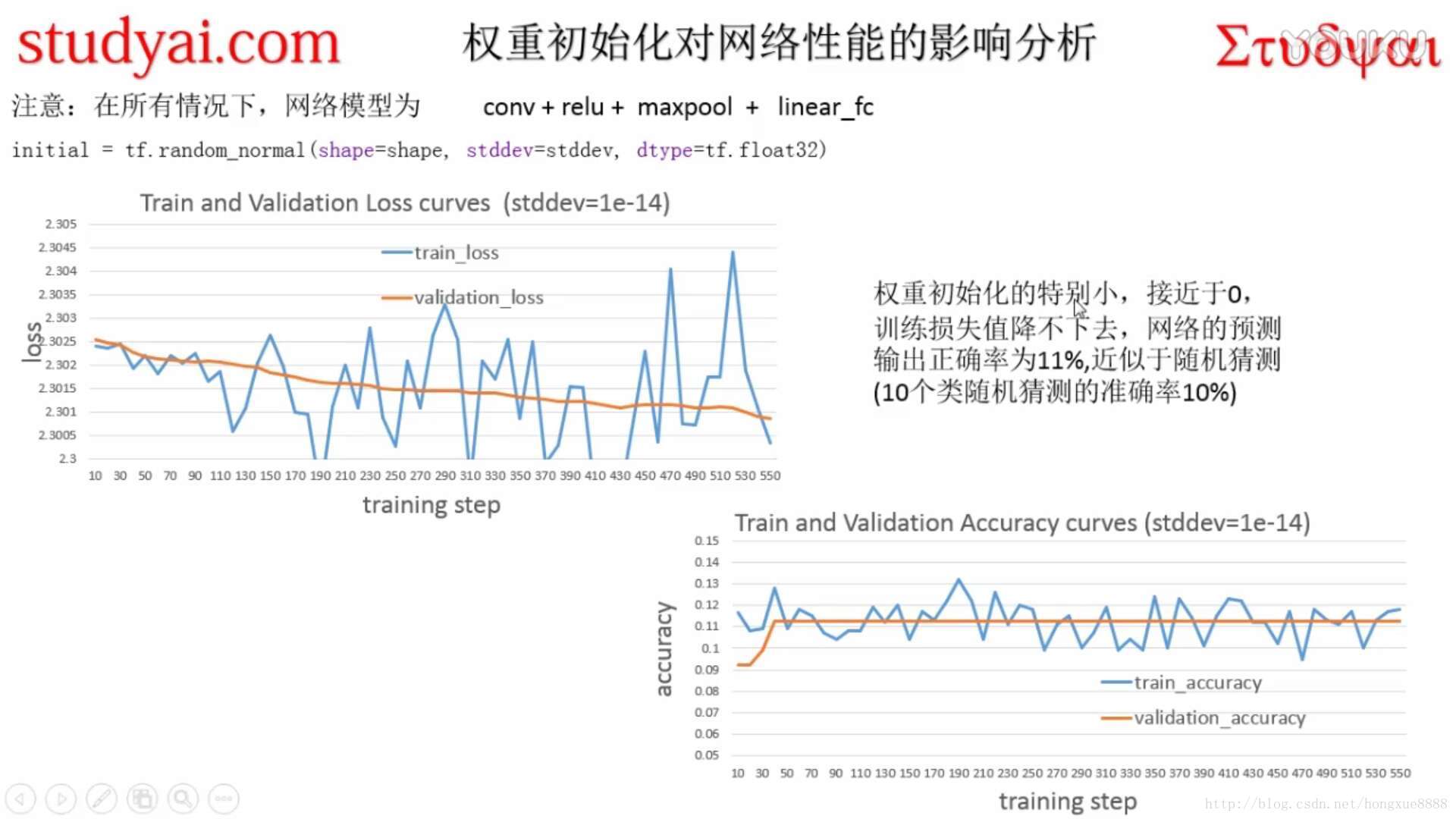
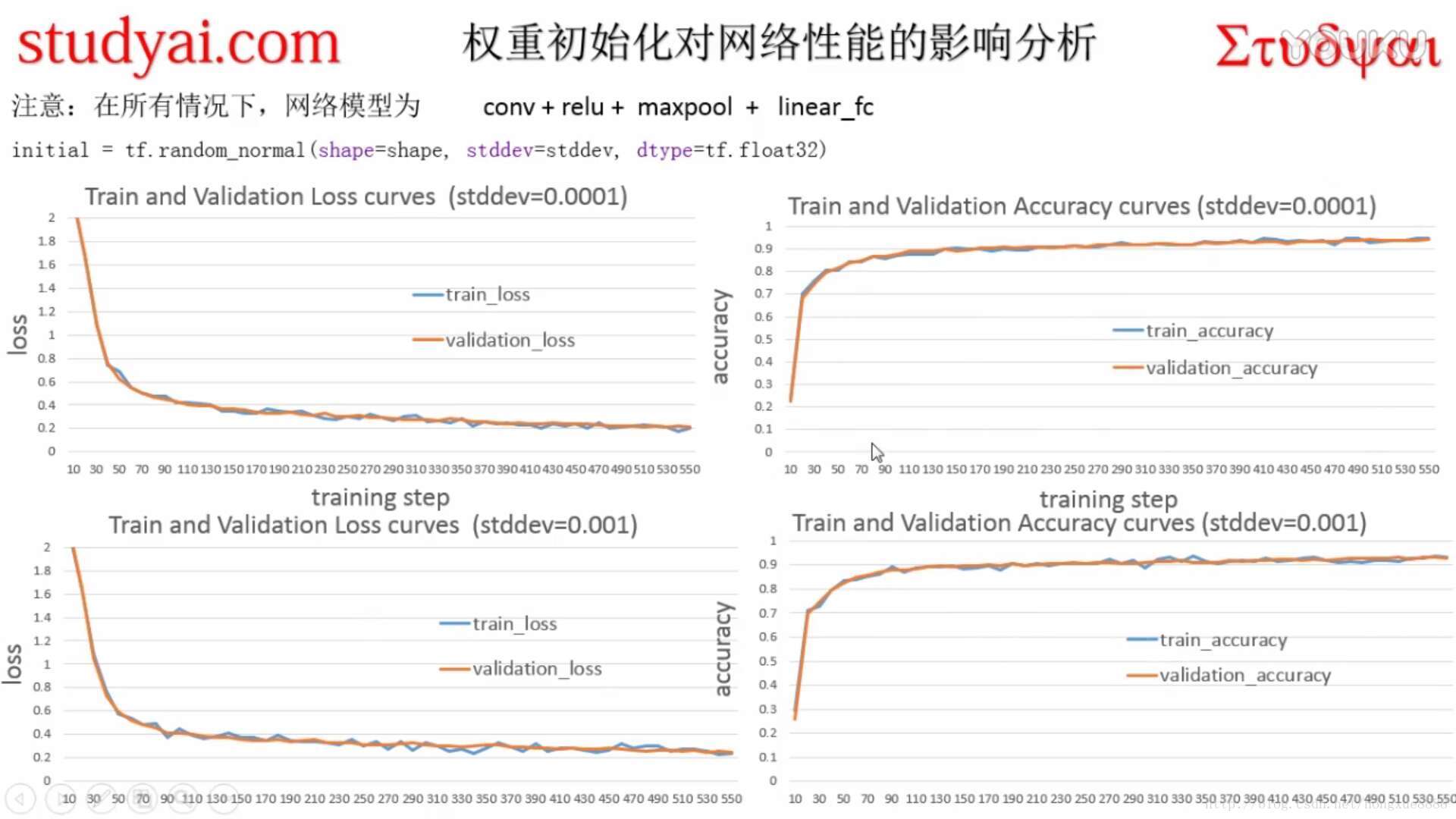
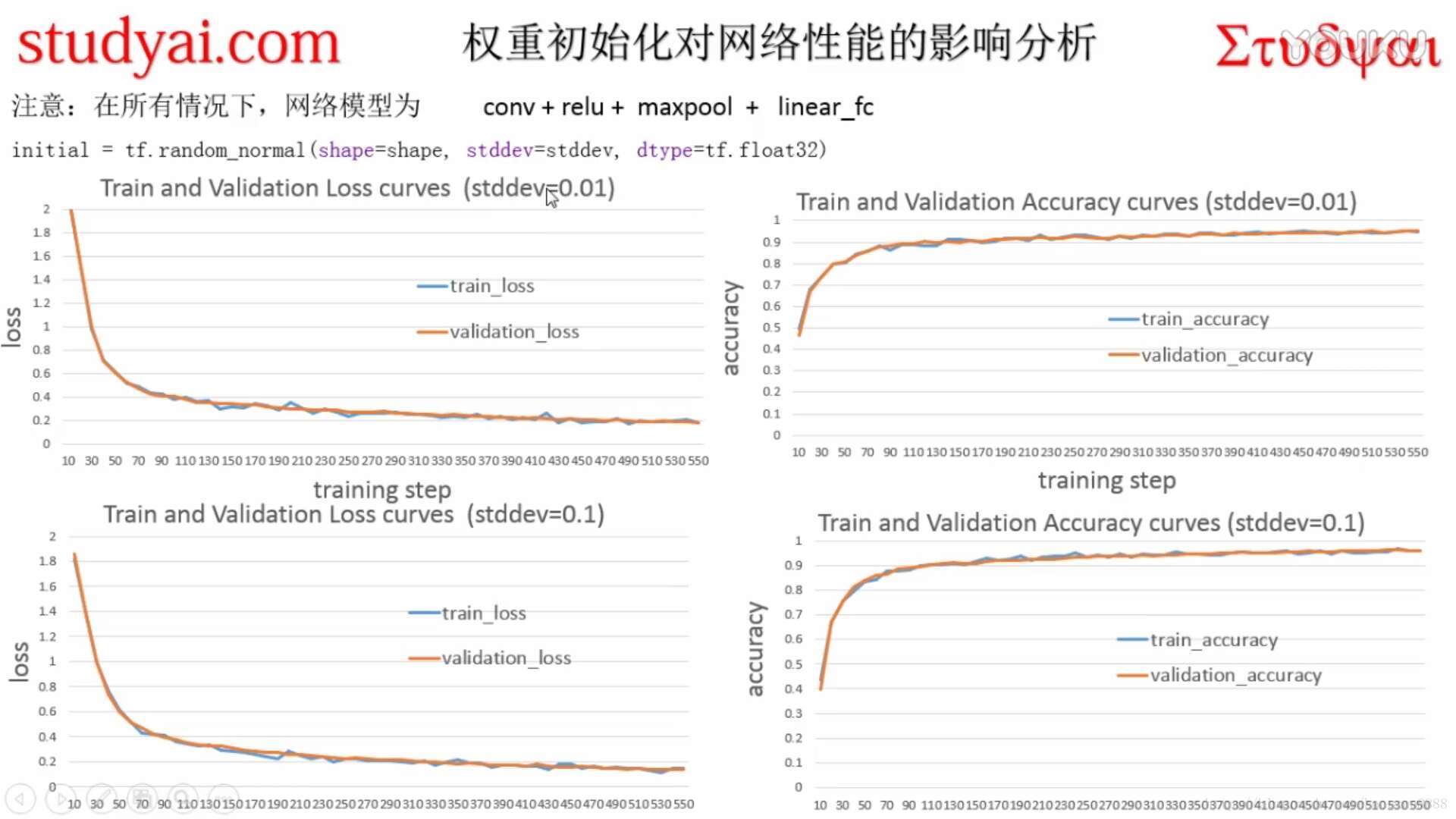

原代码如下,网络结构不变,只要修改学习率参数就可以了
#-*- coding:utf-8 -*-
#实现简单卷积神经网络对MNIST数据集进行分类:conv2d + activation + pool + fc
import csv
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 设置算法超参数
learning_rate_init = 0.001
training_epochs = 1
batch_size = 100
display_step = 10
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
#根据指定的维数返回初始化好的指定名称的权重 Variable
def WeightsVariable(shape, name_str, stddev=0.1):
initial = tf.random_normal(shape=shape, stddev=stddev, dtype=tf.float32)
# initial = tf.truncated_normal(shape=shape, stddev=stddev, dtype=tf.float32)
return tf.Variable(initial, dtype=tf.float32, name=name_str)
#根据指定的维数返回初始化好的指定名称的偏置 studyai.com
def BiasesVariable(shape, name_str, stddev=0.00001):
initial = tf.random_normal(shape=shape, stddev=stddev, dtype=tf.float32)
# initial = tf.constant(stddev, shape=shape)
return tf.Variable(initial, dtype=tf.float32, name=name_str)
# 2维卷积层(conv2d+bias)的封装
def Conv2d(x, W, b, stride=1, padding='SAME'):
with tf.name_scope('Wx_b'):
y = tf.nn.conv2d(x, W, strides=[1, stride, stride, 1], padding=padding)
y = tf.nn.bias_add(y, b)
return y
#非线性激活层的封装studyai.com
def Activation(x, activation=tf.nn.relu, name = 'relu'):
with tf.name_scope(name):
y = activation(x)
return y
# 2维池化层pool的封装
def Pool2d(x, pool= tf.nn.max_pool, k=2, stride=2):
return pool(x, ksize=[1, k, k, 1], strides=[1, stride, stride, 1], padding='VALID')
# 全连接层activate(wx+b)的封装studyai.com
def FullyConnected(x, W, b, activate=tf.nn.relu, act_name='relu'):
with tf.name_scope('Wx_b'):
y = tf.matmul(x, W)
y = tf.add(y, b)
with tf.name_scope(act_name):
y = activate(y)
return y
#通用的评估函数,用来评估模型在给定的数据集上的损失和准确率
def EvaluateModelOnDataset(sess, images, labels):
n_samples = images.shape[0]
per_batch_size = 100
loss = 0
acc = 0
# 样本量比较少的时候,一次性评估完毕;否则拆成若干个批次评估,主要是防止内存不够用
if (n_samples <= per_batch_size):
batch_count = 1
loss, acc = sess.run([cross_entropy_loss, accuracy],
feed_dict={X_origin: images,
Y_true: labels,
learning_rate: learning_rate_init})
else:
batch_count = int(n_samples / per_batch_size)
batch_start = 0
for idx in range(batch_count):
batch_loss, batch_acc = sess.run([cross_entropy_loss, accuracy],
feed_dict={X_origin: images[batch_start:batch_start + per_batch_size, :],
Y_true: labels[batch_start:batch_start + per_batch_size, :],
learning_rate: learning_rate_init})
batch_start += per_batch_size
# 累计所有批次上的损失和准确率
loss += batch_loss
acc += batch_acc
# 返回平均值studyai.com
return loss / batch_count, acc / batch_count
#调用上面写的函数构造计算图
with tf.Graph().as_default():
# 计算图输入
with tf.name_scope('Inputs'):
X_origin = tf.placeholder(tf.float32, [None, n_input], name='X_origin')
Y_true = tf.placeholder(tf.float32, [None, n_classes], name='Y_true')
#把图像数据从N*784的张量转换为N*28*28*1的张量
X_image = tf.reshape(X_origin, [-1, 28, 28, 1])
# 计算图前向推断过程studyai.com
with tf.name_scope('Inference'):
# 第一个卷积层(conv2d + biase)
with tf.name_scope('Conv2d'):
conv1_kernels_num = 5
weights = WeightsVariable(shape=[5, 5, 1, conv1_kernels_num], name_str='weights')
biases = BiasesVariable(shape=[conv1_kernels_num], name_str='biases')
conv_out = Conv2d(X_image, weights, biases, stride=1, padding='VALID')
#非线性激活层studyai.com
with tf.name_scope('Activate'):
activate_out = Activation(conv_out, activation=tf.nn.relu, name='relu')
# 第一个池化层(max pool 2d)
with tf.name_scope('Pool2d'):
pool_out = Pool2d(activate_out, pool=tf.nn.max_pool, k=2, stride=2)
#将二维特征图变换为一维特征向量studyai.com
with tf.name_scope('FeatsReshape'):
features = tf.reshape(pool_out, [-1, 12 * 12 * conv1_kernels_num])
# 第一个全连接层(fully connected layer)
with tf.name_scope('FC_Linear'):
weights = WeightsVariable(shape=[12 * 12 * conv1_kernels_num, n_classes], name_str='weights')
biases = BiasesVariable(shape=[n_classes], name_str='biases')
Ypred_logits = FullyConnected(features, weights, biases,
activate=tf.identity, act_name='identity')
# 定义损失层(loss layer)
with tf.name_scope('Loss'):
cross_entropy_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=Y_true, logits=Ypred_logits))
# 定义优化训练层(train layer)studyai.com
with tf.name_scope('Train'):
learning_rate = tf.placeholder(tf.float32)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
trainer = optimizer.minimize(cross_entropy_loss)
# 定义模型评估层(evaluate layer)
with tf.name_scope('Evaluate'):
correct_pred = tf.equal(tf.argmax(Ypred_logits, 1), tf.argmax(Y_true, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 添加所有变量的初始化节点studyai.com
init = tf.global_variables_initializer()
print('把计算图写入事件文件,在TensorBoard里面查看')
summary_writer = tf.summary.FileWriter(logdir='logs/excise313/', graph=tf.get_default_graph())
summary_writer.close()
# 导入 MNIST data
mnist = input_data.read_data_sets("../MNIST_data/", one_hot=True)
#将评估结果保存到文件
results_list = list()
# 写入参数配置
results_list.append(['learning_rate', learning_rate_init,
'training_epochs', training_epochs,
'batch_size', batch_size,
'display_step', display_step,
'conv1_kernels_num',conv1_kernels_num])
results_list.append(['train_step', 'train_loss', 'validation_loss',
'train_step', 'train_accuracy', 'validation_accuracy'])
# 启动计算图
with tf.Session() as sess:
sess.run(init)
total_batches = int(mnist.train.num_examples / batch_size)
print("Per batch Size: ", batch_size)
print("Train sample Count: ", mnist.train.num_examples)
print("Total batch Count: ", total_batches)
training_step = 0 #记录模型被训练的步数
# 训练指定轮数,每一轮所有训练样本都要过一遍
for epoch in range(training_epochs):
# 每一轮都要把所有的batch跑一边
for batch_idx in range(total_batches):
# 取出数据
batch_x, batch_y = mnist.train.next_batch(batch_size)
# 运行优化器训练节点 (backprop)
sess.run(trainer, feed_dict={X_origin: batch_x,
Y_true: batch_y,
learning_rate: learning_rate_init})
# 每调用一次训练节点,training_step就加1,最终==training_epochs*total_batch
training_step += 1
#每训练display_step次,计算当前模型的损失和分类准确率
if training_step % display_step == 0:
# 计算当前模型在目前(最近)见过的display_step个batchsize的训练集上的损失和分类准确率
start_idx = max(0, (batch_idx-display_step)*batch_size)
end_idx = batch_idx*batch_size
train_loss, train_acc = EvaluateModelOnDataset(sess,
mnist.train.images[start_idx:end_idx, :],
mnist.train.labels[start_idx:end_idx, :])
print("Training Step: " + str(training_step) +
", Training Loss= " + "{:.6f}".format(train_loss) +
", Training Accuracy= " + "{:.5f}".format(train_acc))
# 计算当前模型在验证集的损失和分类准确率
validation_loss, validation_acc = EvaluateModelOnDataset(sess,
mnist.validation.images,
mnist.validation.labels)
print("Training Step: " + str(training_step) +
", Validation Loss= " + "{:.6f}".format(validation_loss) +
", Validation Accuracy= " + "{:.5f}".format(validation_acc))
# 将评估结果保存到文件
results_list.append([training_step, train_loss, validation_loss,
training_step, train_acc, validation_acc])
print("训练完毕!")
#计算指定数量的测试集上的准确率
test_samples_count = mnist.test.num_examples
test_loss, test_accuracy = EvaluateModelOnDataset(sess, mnist.test.images, mnist.test.labels)
print("Testing Samples Count:", test_samples_count)
print("Testing Loss:", test_loss)
print("Testing Accuracy:", test_accuracy)
results_list.append(['test step', 'loss', test_loss, 'accuracy', test_accuracy])
# 将评估结果保存到文件
results_file = open('evaluate_results/evaluate_results.csv', 'w', newline='')
csv_writer = csv.writer(results_file, dialect='excel')
for row in results_list:
csv_writer.writerow(row)














 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









