







一,面试知识类
1.python2和pyton3的区别?
- 1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print(‘hi’) Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print ‘hi’
- 2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
- 3、python2中使用ascii编码,python中使用utf-8编码
- 4、python2中unicode表示字符串序列,str表示字节序列python3中str表示字符串序列,byte表示字节序列
- 5、python2中为正常显示中文,引入coding声明,python3中不需要
- 6、python2中是raw_input()函数,python3中是input()函数
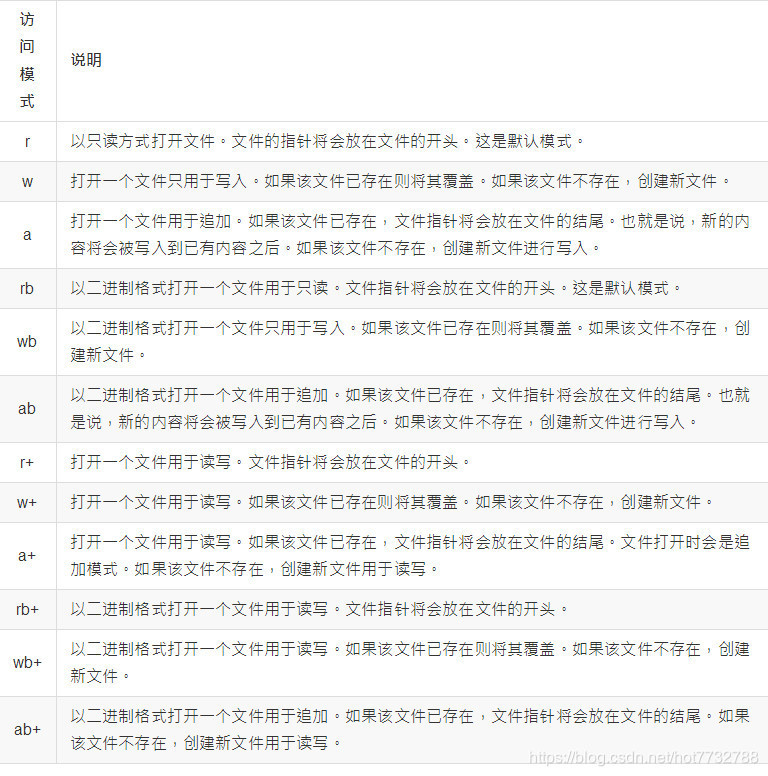
2.文件打开模式区别
二,数据处理类
1.将二维数组展开成一维数组
a = [[1, 2], [3, 4], [5, 6]]
x = [j for i in a for j in i] #方法一
import numpy as np
b = np.array(a).flatten().tolist() #方法二
2.设置保留小数位
a = 1.3333333
b = "%.03f"%a #保留三位小数
print(b)
c = round(a, 2) #保留两位小数
print(c)
3.将列表推导式转化为生成器
生成器是特殊的迭代器,
- 1、列表表达式的【】改为()即可变成生成器
- 2、函数在返回值得时候出现yield就变成生成器,而不是函数了
中括号换成小括号即可,有没有惊呆了
a = (i for i in range(3))
print(a)
<generator object <genexpr> at 0x000000C660EB65C8>
4.求两个列表的交集,差集,并集
a = [1, 2, 3, 4]
b = [3, 4, 5, 6]
#交集
j1 = [i for i in a if i in b]
j2 = list(set(a).intersection(set(b)))
#并集
b = list(set(a).union(set(b)))
#差集
c1 = list(set(b).difference(set(a))) #b中有而a中没有,反之转换a,b即可
5.进制转换
dec = int(input("请输入一个十进制数字:"))
print("十进制为:", dec)
print("二进制为", bin(dec))
print("八进制为:", oct(dec))
print("十六进制为", hex(dec))
6.字符串拼接
- 加号拼接
>>> a, b = 'hello', ' world'
>>> a + b
'hello world'
- format方法
print('{}{}'.format('hello', ' world')
- join方法
print('-'.join(['aa', 'bb', 'cc']))
- f-string方法
>>> aa, bb = 'hello', 'world'
>>> f'{aa} {bb}'
'hello world'
- *方法
>>> aa = 'hello '
>>> aa * 3
'hello hello hello '
7.使用.get()和.setdefault()在字典中定义默认值
#最垃圾的获取字典中需要的键的数据
>>> cowboy = {'age': 32, 'horse': 'mustang', 'hat_size': 'large'}
>>> if 'name' in cowboy:
... name = cowboy['name']
... else:
... name = 'The Man with No Name'
...
>>> name
'The Man with No Name'
#获取响应键值,如果有则返回,没有则返回后面的字符
>>> name = cowboy.get('name', 'The Man with No Name')
#取响应键值,如果有则返回,没有则设置此键并以后面的数据作为内容,并返回
>>> name = cowboy.setdefault('name', 'The Man with No Name')
三,排序类
1.利用lambda函数对list排序,正数从小到大,负数从大到小
a = [-5, 8, 0, 4, 9, -4, -20, -2, 8, 2, -4]
a = sorted(a, key = lambda x:(x<0, abs(x)))
print(a)
[0, 2, 4, 8, 8, 9, -2, -4, -4, -5, -20]
2.列表嵌套字典的排序,分别根据年龄和姓名排序
foo = [{"name":"zs","age":19},{"name":"ll","age":54},
{"name":"wa","age":17},{"name":"df","age":23}]
a = sorted(foo, key = lambda x:x["age"], reverse=False) #年龄从大到小排序
b = sorted(foo, key = lambda x:x["name"])#姓名从小到大排序
3.列表嵌套元组,分别按字母和数字排序
foo = [("zs", 19), ("ll", 54), ("wa", 17), ("sf", 23)]
a = sorted(foo, key=lambda x:x[1], reverse=True) #按年龄从大到小
print(a)
b = sorted(foo, key = lambda x:x[0])#按姓名首字母从小到大
print(b)
[('ll', 54), ('sf', 23), ('zs', 19), ('wa', 17)]
[('ll', 54), ('sf', 23), ('wa', 17), ('zs', 19)]
4.列表嵌套列表排序,年龄数字相同怎么办?
foo = [["zs", 19], ["ll", 54], ["wa", 23], ["df", 23], ["xf", 23]]
a = sorted(foo, key = lambda x:(x[1], x[0]), reverse=False) #年龄相同时,添加参数按照字母排序
print(a)
[['zs', 19], ['df', 23], ['wa', 23], ['xf', 23], ['ll', 54]]
5.根据键对字典排序
dic = {"name":"zs", "sex":"man", "city":"bj"}
#方法一,zip函数
a1 = zip(dic.keys(), dic.values()) #字典转化为元组对象
print(a1) #<zip object at 0x000000433E943988>
a1 = [i for i in a1] #生成器取出元素
print(a1) #[('name', 'zs'), ('sex', 'man'), ('city', 'bj')]
b1 = sorted(a1, key = lambda x:x[0]) #依据元素的第一个元素进行排序,即根据键进行排序
print(b1) #[('city', 'bj'), ('name', 'zs'), ('sex', 'man')]
new_dic = {i[0]:i[1] for i in b1}#还原排序好的字典
print(new_dic) #{'city': 'bj', 'name': 'zs', 'sex': 'man'}
#方法二,不用zip
print(dic.items()) #字典转化为列表嵌套元组(不在原字典上进行操作)
b2 = sorted(dic.items(), key = lambda x:x[0])
new_dic = {i[0]:i[1] for i in b1}#还原排序好的字典
print(new_dic) #{'city': 'bj', 'name': 'zs', 'sex': 'man'}
6.根据字符串长度排序
s = ["ab", "abc", "a", "abcd"]
a = sorted(s, key = lambda x:len(x))
print(a)
s.sort(key=len) #在原列表上进行更改
print(s)
['a', 'ab', 'abc', 'abcd']
['a', 'ab', 'abc', 'abcd']
四,函数应用类
1.map函数的使用
list = [1, 2, 3, 4, 5]
def fn():
return x**2
res = map(fn, list)
#res = 1, 4, 9, 16, 25
2.生成随机整数,生成正态规律(-1~1),生成0-1小数
import random
import numpy as np
result = random.randint(10, 20)
res = np.random.randn(5)
ret = random.random()
/*
15
[-0.53466153 0.69176947 0.18377477 0.47902627 0.93834969]
0.6697961508083531
*/
3.利用collections中的Counter方法统计字符串中每个单词出现的次数
from collections import Counter
a = "kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
res = Counter(a)
print(res)
4.利用filter方法过滤数据
- filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
def fn(a):
return a%2 == 1
new_list = filter(fn, a) #生成的是一个构造器对象,需要单个取出
new_list = [i for i in new_list]
print(new_list)
5.列出当前目录下所有文件和目录名
import os
[d for d in os.listdir('.')]
6.输出某个路径下的所有文件和文件夹的路径
import os
def print_dir():
filepath = input("请输入一个路径:")
if filepath == '':
print("请输入正确路径")
else:
for i in os.listdir(filepath):
print(os.path.join(filepath, i))
print_dir()
7.输出某个路径及其子目录下所有以.py为后缀的文件
import os
def print_dir(filepath):
for i in os.listdir(filepath):
path = os.path.join(filepath, i)
if os.path.isdir(path):
print_dir(path)
if path.endswith('.py'):
print(path)
filepath = '.'
print_dir(filepath)
8.使用collections.Counter计算Hashable对象
“”“假如你有一长串没有标点符号或大写字母的单词,你想要计算每个单词出现的次数。”“”
#collections.Counter提供了一种更清晰,更方便的方法
>>> from collections import Counter
>>> words = "if there was there was but if
... there was not there was not".split()
>>> counts = Counter(words)
>>> counts
Counter({'if': 2, 'there': 4, 'was': 4, 'not': 2, 'but': 1})
#如果你好奇两个最常见的词是什么?只需使用.most_common()
>>> counts.most_common(2)
[('there', 4), ('was', 4)]
9.使用Itertools生成排列和组合
#当你需要列出一个列表中所有可能的搭配组合
#不在乎顺序,会存在重复
>>> import itertools
>>> friends = ['Monique', 'Ashish', 'Devon', 'Bernie']
>>> list(itertools.permutations(friends, r=2))
[('Monique', 'Ashish'), ('Monique', 'Devon'), ('Monique', 'Bernie'),
('Ashish', 'Monique'), ('Ashish', 'Devon'), ('Ashish', 'Bernie'),
('Devon', 'Monique'), ('Devon', 'Ashish'), ('Devon', 'Bernie'),
('Bernie', 'Monique'), ('Bernie', 'Ashish'), ('Bernie', 'Devon')]
#不希望重复(不会前后重复)
>>> list(itertools.combinations(friends, r=2))
[('Monique', 'Ashish'), ('Monique', 'Devon'), ('Monique', 'Bernie'),
('Ashish', 'Devon'), ('Ashish', 'Bernie'), ('Devon', 'Bernie')]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









