所有文件类型的文件读取流程
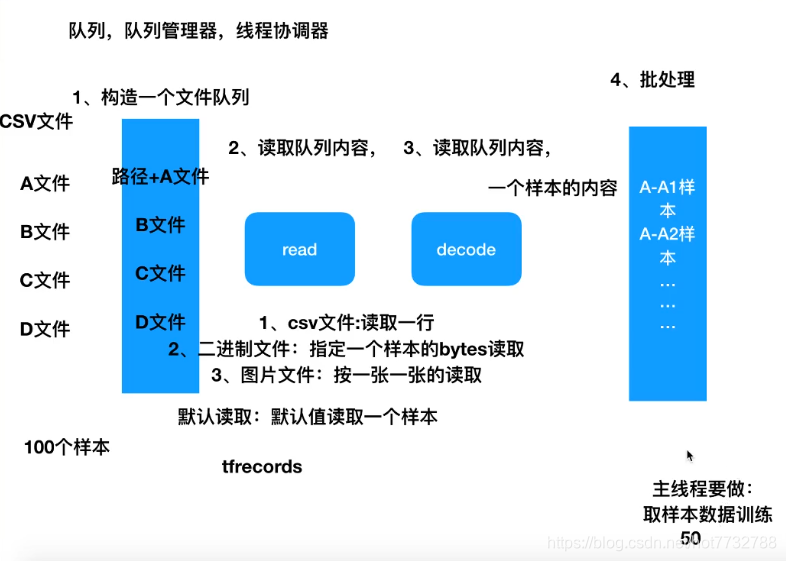
1.CSV文件

- 构造文件队列api

- 构造文件阅读器api并进行数据读取

- 对文件内容进行解码(一次一行)

- 读取多个文件开启批处理过程

- 在主线程中开启子线程读取文件的线程协调器,别忘记用完后要回收线程

- 代码
import tensorflow as tf
import os
def csv_read(file_list):
file_queue = tf.train.string_input_producer(file_list)
reader = tf.TextLineReader()
key, value = reader.read(file_queue)
records = [["None"], [1]]
col1, col2 = tf.decode_csv(value, field_delim=",", record_defaults=records)
col1_more, col2_more = tf.train.batch([col1, col2], batch_size=10, num_threads=1, capacity=10)
print(col1_more, col2_more)
return col1_more, col2_more
if __name__ == '__main__':
file_names = os.listdir("./csv_data/")
file_list = [os.path.join("./csv_data/", file) for file in file_names]
example, label = csv_read(file_list)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config = config) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess,coord = coord)
a, b = sess.run([example, label])
print(a, b)
coord.request_stop()
coord.join(threads)
2.图片读取
- 图片读取器和图像解码api,图像解码有很多格式,这里只列举两种

- 为了统一图像特征值(像素点数相同,调整为统一大小)

- 代码
import tensorflow as tf
import os
def tupian_read(file_list):
file_queue = tf.train.string_input_producer(file_list)
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
image = tf.image.decode_jpeg(value)
image_resize = tf.image.resize_images(image, [200, 200])
image_resize.set_shape([200, 200, 3])
image_batch = tf.train.batch([image_resize], batch_size=5, num_threads=1, capacity=5)
print(image_batch)
return image_resize
if __name__ == '__main__':
file_names = os.listdir("./狗/")
file_list = [os.path.join("./狗/", file) for file in file_names]
values = tupian_read(file_list)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord=coord)
a= sess.run([values])
print(a)
coord.request_stop()
coord.join(threads)
3.二进制文件
- 使用cifar10作为数据读取例子数据集
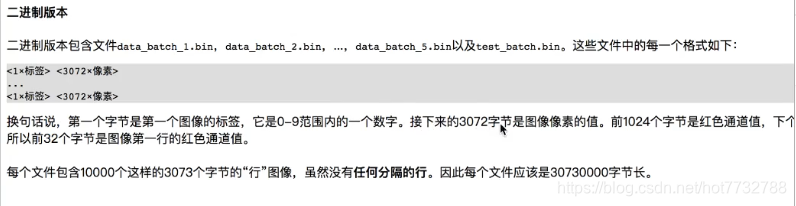
- 二进制文件阅读器

- 二进制文件解码器
 - 源码(为了后面的转化为tfrecord方便直接做成了一个类)
- 源码(为了后面的转化为tfrecord方便直接做成了一个类)
import tensorflow as tf
import os
class erjinzhi_duqu:
def __init__(self, file_list):
self.file_list = file_list
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = 3072
self.bytes = 3073
def readanddecode(self):
file_queue = tf.train.string_input_producer(self.file_list)
reader = tf.FixedLengthRecordReader(self.bytes)
key, value = reader.read(file_queue)
label_image = tf.decode_raw(value, tf.uint8)
label1 = tf.slice(label_image, [0], [self.label_bytes])
image1 = tf.slice(label_image, [self.label_bytes], [self.image_bytes])
label2 = tf.cast(label_image[0:self.label_bytes], tf.int32)
image2 = label_image[self.label_bytes:self.image_bytes]
"""
Tensor("Cast:0", shape=(1,), dtype=int32)
Tensor("Slice_1:0", shape=(3072,), dtype=uint8)
Tensor("Cast_1:0", shape=(?,), dtype=int32)
Tensor("strided_slice_1:0", shape=(?,), dtype=uint8)
"""
image_reshape1 = tf.reshape(image1, [self.height, self.width, self.channel])
image_batch1, label_batch1 = tf.train.batch([image_reshape1, label1], batch_size=10, num_threads=1, capacity=10)
return image_batch1, label_batch1
if __name__ == '__main__':
file_names = os.listdir("./cifar10/cifar-10-batches-bin/")
file_list = [os.path.join("./cifar10/cifar-10-batches-bin/", file) for file in file_names if file[-3:] == "bin"]
br = erjinzhi_duqu(file_list)
example, label = br.readanddecode()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config = config) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess,coord = coord)
a, b = sess.run([example, label])
print(a, b)
coord.request_stop()
coord.join(threads)
4.tfrecord文件的存储与读取
1.从二进制文件写入tfrecords文件
- 创建tfrecords存储器(注意:存储需要序列化)

- example协议块填写参数

- 核心存储代码
def write_to_tfrecords(self, image_batch, label_batch, save_path):
"""
将图片的特征值和目标值存进tfrecord
:param image_batch:
:param label_batch:
:return:
"""
print("开始存储")
writer = tf.python_io.TFRecordWriter(save_path)
for i in range(10):
image = image_batch[i].eval().tostring()
label = int(label_batch[i].eval()[0])
example = tf.train.Example(features = tf.train.Features(feature = {
"image":tf.train.Feature(bytes_list = tf.train.BytesList(value=[image])),
"label":tf.train.Feature(int64_list = tf.train.Int64List(value=[label])),
}))
writer.write(example.SerializeToString())
writer.close()
print("存储完毕")
2.从tfrecords文件中读取数据(流程就和前面的读取差不多了,就是多了一个解码)

import tensorflow as tf
import os
class erjinzhi_duqu:
def __init__(self, file_list):
self.file_list = file_list
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = 3072
self.bytes = 3073
def readanddecode(self):
file_queue = tf.train.string_input_producer(self.file_list)
reader = tf.FixedLengthRecordReader(self.bytes)
key, value = reader.read(file_queue)
label_image = tf.decode_raw(value, tf.uint8)
label1 = tf.slice(label_image, [0], [self.label_bytes])
image1 = tf.slice(label_image, [self.label_bytes], [self.image_bytes])
label2 = tf.cast(label_image[0:self.label_bytes], tf.int32)
image2 = label_image[self.label_bytes:self.image_bytes]
"""
Tensor("Cast:0", shape=(1,), dtype=int32)
Tensor("Slice_1:0", shape=(3072,), dtype=uint8)
Tensor("Cast_1:0", shape=(?,), dtype=int32)
Tensor("strided_slice_1:0", shape=(?,), dtype=uint8)
"""
image_reshape1 = tf.reshape(image1, [self.height, self.width, self.channel])
image_batch1, label_batch1 = tf.train.batch([image_reshape1, label1], batch_size=10, num_threads=1, capacity=10)
return image_batch1, label_batch1
def write_to_tfrecords(self, image_batch, label_batch, save_path):
"""
将图片的特征值和目标值存进tfrecord
:param image_batch:
:param label_batch:
:return:
"""
print("开始存储")
writer = tf.python_io.TFRecordWriter(save_path)
for i in range(10):
image = image_batch[i].eval().tostring()
label = int(label_batch[i].eval()[0])
example = tf.train.Example(features = tf.train.Features(feature = {
"image":tf.train.Feature(bytes_list = tf.train.BytesList(value=[image])),
"label":tf.train.Feature(int64_list = tf.train.Int64List(value=[label])),
}))
writer.write(example.SerializeToString())
writer.close()
print("存储完毕")
def tfrecords_read(self, read_path):
file_queue = tf.train.string_input_producer([read_path])
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
features = tf.parse_single_example(value, features = {
"image":tf.FixedLenFeature([], tf.string),
"label":tf.FixedLenFeature([], tf.int64)
})
print(features["image"], features["label"])
image = tf.decode_raw(features["image"], tf.uint8)
label = features["label"]
print(image, label)
image_reshape = tf.reshape(image, [self.height, self.width, self.channel])
print(image_reshape)
image_batch, label_batch = tf.train.batch([image_reshape, label], batch_size=10, num_threads=1, capacity=10)
print(image_batch, label_batch)
return image_batch, label_batch
if __name__ == '__main__':
file_names = os.listdir("./cifar10/cifar-10-batches-bin/")
file_list = [os.path.join("./cifar10/cifar-10-batches-bin/", file) for file in file_names if file[-3:] == "bin"]
br = erjinzhi_duqu(file_list)
read_path = "./写入的tfrecords文件/cifar10.tfrecords"
image_batch, label_batch = br.tfrecords_read(read_path)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config = config) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess,coord = coord)
save_path = "./写入的tfrecords文件/cifar10.tfrecords"
print(sess.run([image_batch, label_batch]))
coord.request_stop()
coord.join(threads)























 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









