







本文介绍的是如何在Windows中使用Eclipse来开发MapReduce程序,并打包成jar包在已经搭建好的hadoop集群环境上运行。
环境
- Windows 7
- Hadoop 2.7.3
- Eclipse Mars Release (4.5.0)
安装Hadoop-Eclipse-Plugin
由于Windows系统下配置JDK环境和Eclipse的安装比较简单,所以此处省略其安装步骤。
要在Eclipse上编译和运行MapReduce程序,需要安装hadoop-Eclipse-Plugin,可下载hadoop-eclipse-plugin-2.7.3
下载后,将release中的hadoop-eclipse-plugin-2.7.3.jar复制到Windows系统中的Eclipse安装目录的plugin文件夹中,重启Eclipse即可。
配置Hadoop-Eclipse-Plugin
在继续配置前请确保已经开启了 Hadoop。
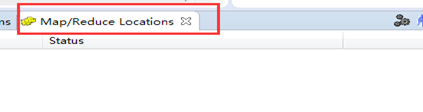
启动Eclipse后,依次点击 Windows -> Show View -> Other。在新弹出的选项框中找到 Map/Reduce Locations, 选中后单击 OK 按钮。如下图所示:

单击 OK 后,在Eclipse下面的视图中会多出一栏 Map/Reduce Locations,如下图所示:
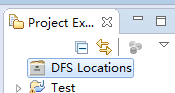
然后单击 Windows -> Show View -> Project Expore,在Eclipse左侧视图中会显示项目浏览器,项目浏览器中最上面会出现 DFS Locations,如下图所示:
Map/Reduce Locations 用于建立连接到Hadoop 集群,当连接到Hadoop集群后,DFS Locations 则会显示相应集群 HDFS 中的文件。 Map/Reduce Locations 可以一次连接到多个Hadoop集群。
在 Map/Reduce Locations 下侧的空白处右击,在弹出的选项中选择 New Hadoop location,新建一个Hadoop连接,之后会弹出 Hadoop location 的详细设置窗口,如下图所示,各项解释如下。

- Location name: 当前建立的Hadoop location命名。
- Map/Reduce Host: 为集群namenode的IP地址。
- Map/Reduce Port: MapReduce任务运行的通信端口号,客户端通过该地址向RM提交应用程序,杀死应用程序等。在yarn-site.xml中,默认值:${yarn.resourcemanager.hostname}:8032
- DFS Master Use M/R Master host: 选中表示采用和 Map/Reduce Host一样的主机。
- DFS Master Host: 为集群namenode的IP地址。
- DFS Master Port: HDFS端口号,对应core-site.xml中定义的fs.defaultFS参数中的端口号,一般为9000;
- User Name: 设置访问集群的用户名,默认为本机的用户名。
配置完成后,单击Finish即可完成 Hadoop location的配置。在 Advanced parameters选项卡中还可以配置更多细节,但在实际使用中非常繁琐,相应的设置在代码中也可以进行,或者将Hadoop集群的配置文件放到Eclipse目录下,自动完整配置。 这里只需要配置General选项卡的内容即可。这是,右侧Project Expore中的DFS locations中会多出一个子栏,名字为上面设置的MapReduce Location名称。
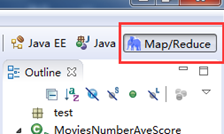
总之,我们只要配置 General 就行了,点击 finish,Map/Reduce Location 就创建好了。
使用Eclipse插件管理HDFS
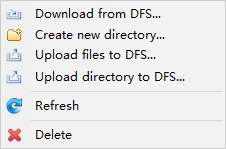
如果前面的配置参数没有问题,Hadoop集群也已经启动,那么Eclipse插件会自动连接Hadoop集群的HDFS,并获取HDFS的文件信息。便可以在上面操作HDFS。
还需要值的一提的是,为了安全,HDFS的权限检测机制默认是打开的,关闭之后,才能使用Eclipse插件上传文件到HDFS或者从HDFS中删除文件。
为了能在Windows上直接操作Hadoop集群中的HDFS,需修改Windows本地主机名:
首先,“右击”桌面上图标“我的电脑”,选择“管理”,接着选择“本地用户和组”,展开“用户”,找到当前系统用户,修改其为“root”。
最后,把电脑进行“注销”或者“重启电脑”,这样修改的用户名才有效,就可以用Hadoop Eclipse插件提供的图像化界面操作Hadoop集群中的HDFS了。
在Eclipse中提交任务到Hadoop
使用Eclipse插件可以直接在Eclipse环境下采用图形操作的方式提交任务,可以极大的简化了开发人员提交任务的步骤。
配置本地Hadoop目录和输入输出目录
首先,需要在Eclipse中设置本地Hadoop目录,假设安装hadoop的压缩包解压到本地D:\Software\hadoop 下,在Eclipse界面单击 Windows -> Preference 弹出设置界面,在设置界面找到 Hadoop Map/Reduce,在 Hadoop installation dierctory后面填上D:\Software\hadoop
此处,需要注意,解压的D:\Software\hadoop 源码包是在Linux环境下安装在master结点的源码包,与Windows不兼容。在Windows下提交任务是会出现Failed to lacation the winutils binary in hadoop binary path,需要使用如下操作进行修复:
- 下载Window下的运行包
将下载好的hadoop-common-2.7.3-bin_32b.zip中的bin文件下的所有文件覆盖掉D:\Software\hadoop\bin下的所有文件。 - 复制D:\Software\hadoop\bin\hadoop.dll文件到C:\Windows\System32中。
- 配置环境变量 HADOOP_HOME为D:\Software\hadoop,并将%HADOOP_HOME%\bin添加到PATH环境变量中去。
- 重启电脑
在向Hadoop集群提交任务时,还需要指定输入/输出目录,在Eclipse中,可按如下操作进行设置:双击打开工程的某代码文件,在代码编辑区 右键 -> Run As -> Run Configurations. 在弹出的窗口中找到 Java Application -> WordCount, 单击 WordCount 进入设置界面,单击 Arguments 切换选项卡,在 Program arguments 下的文本框中指定输入/输出目录。
第一行目录为输入目录,第二行目录为输出目录,格式为 hdfs://[namenode_ip]:[端口号][路径]。
注意,输出目录在HDFS中不能存在。如下图所示:
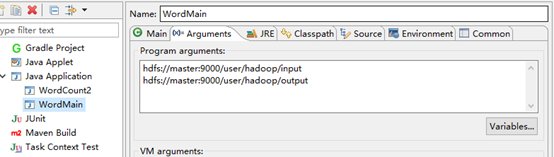
注意:上图中的master我已经在本地主机的hosts文件中映射为namenode的IP地址了。每次运行MapReduce前,切记要配置输入输出路径;运行后至下一次运行前,切记删掉“output”文件夹
在Eclipse中创建MapReduce项目
点击 File 菜单,选择 New -> Project…: 选择 Map/Reduce Project,点击 Next。

填写 Project name 为 WordCount 即可,点击 Finish 就创建好了项目。此时在左侧的 Project Explorer 就能看到刚才建立的项目了。

接着右键点击刚创建的WordCount项目,选择 New -> Class 需要填写两个地方:在 Package 处填写 需要填写两个地方:在 Package 处填写 org.apache.hadoop.examples;在 Name 处填写 WordCount。;在 Name 处填写 WordCount。创建class完成后,在Project的src中就能看到WordCount.java这个文件,打开这个文件就可以在编辑器里面书写java代码了。代码如下:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
将输入文件上传到input中:

代码编写完了后,选择Eclipse中File->Export 会出现如下图所示:

选择JAR File->Next ,在出现的对话框里面选择自己创建的项目和JAR File保存的路径,然后点击Finish即可导出JAR File。

然后用WinSCP软件将WordCount.jar包上传到master节点里的/usr/local/hadoop/tmp 文件夹下,接着在master节点上进入到/usr/local/hadoop/tmp文件夹,执行下面的命令:
hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount hdfs://172.16.136.34:9000/user/hadoop/input hdfs://172.16.136.34:9000/user/hadoop/output
其中,WordCount.jar是jar包所在当前目录(/usr/local/hadoop/tmp),org/apache/hadoop/examples/WordCount是因为main程序是放在org.apache.hadoop.examples包下的WordCount.java下,hdfs://172.16.136.34:9000/user/hadoop/input是dfs文件系统下的word.txt输入文件的目录,hdfs://172.16.136.34:9000/user/hadoop/output是设定的输出目录。

在master节点运行结束后的输出:

Windows上Eclipse中的输出:
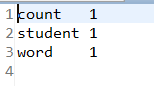
至此,整个编译运行过程结束。















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









