







1.1、一般的目标函数:
L(Θ):损失函数,代表我们的模型有多拟合数据,Ω(Θ):正则化项,表示模型的复杂程度
这样目标函数的设计来自于统计学习里面的一个重要概念叫做Bias-variance tradeoff44。比较感性的理解,Bias可以理解为假设我们有无限多数据的时候,可以训练出最好的模型所拿到的误差。而Variance是因为我们只有有限数据,其中随机性带来的误差。目标中误差函数鼓励我们的模型尽量去拟合训练数据,这样相对来说最后的模型会有比较少的 bias。而正则化项则鼓励更加简单的模型。因为当模型简单之后,有限数据拟合出来结果的随机性比较小,不容易过拟合,使得最后模型的预测更加稳定。
1.2、对于tree ensemble,我们可以比较严格的把我们的模型写成是:
k代表第k课树,最终的结果是K棵树结果的加和。
1.3、xgboost设计目标也包含上面的两部分:
找到ft来优化这一目标
当l为平方误差的情况下,这时候目标能改写成下面的二次函数:
1.4、目标函数通过二阶泰勒展开变形
- 泰勒展开:
f(x+Δx)≃f(x)+f′(x)Δx+12f′′(x)Δx2- 定义:
gi=∂y^(t−1)l(yi,y^(t−1)), hi=∂2y^(t−1)l(yi,y^(t−1))
l(yi,y^(t−1)i+ft(xi))其中yi每次都不变,l(yi,y^(t−1)i)→f(x)其中y^(t−1)i→x在f(x+Δx)中,ft(xi)→Δx
关于
ft的函数
在去除常数项后目标函数的形式如下:
传统的GBDT可能大家可以理解如优化平法aa残差,但是这样一个形式包含可所有可以求导的目标函数。也就是说有了这个形式,我们写出来的代码可以用来求解包括回归,分类和排序的各种问题
2.1、树的复杂度
对于f的定义做一下细化,把树拆分成结构部分
q
,和叶子权重部分
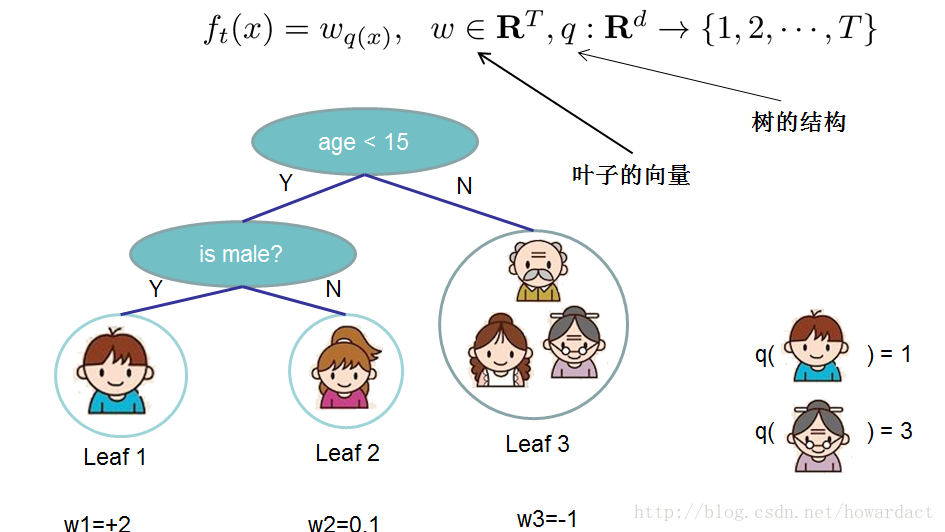
- 树的复杂度公式:
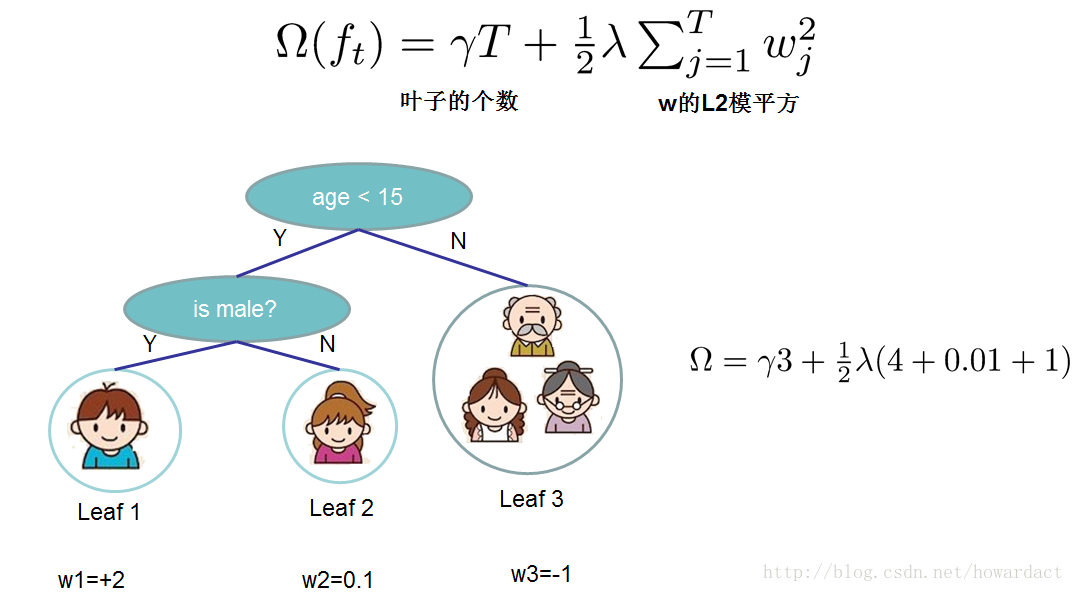
Ω(ft)=γT+12λ∑j=1Tw2j(2.1.2)
T为叶子节点的总数目,这个复杂度包括了一棵树里面节点个数,以及每个树叶子节点上面输出分数的 L2 模平方。
2.2、求解总目标函数
每个叶子上面的样本集合 Ij={i|q(xi)=j},j={1,2,...T},j为叶子节点的id
把2.2.4带入2.2.3得:
一元二次方程求最小值(一阶导数为0)
2.2.6带入2.2.5得:
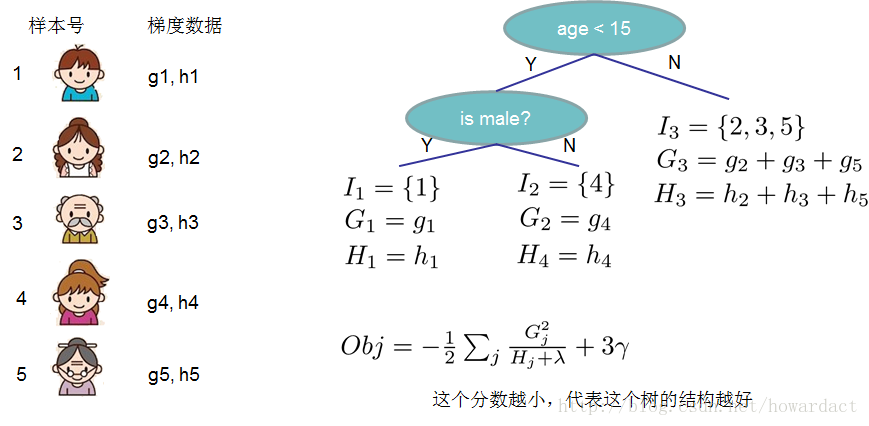
G2LHL+λ:左子树分数,G2RHR+λ:右子树分数;(Gl+GR)2HL+HR+λ:不分割的分数;γ:新加入节点引入的复杂代价
















 3432
3432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









