







GitHub开源的最全中华古典文集数据库,包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。
利用开源的数据库,随手练习写了一个程序,原本是想练习一下用pandas读取json数据写入mysql数据库,然后用这个庞大的数据来练习数据库的基本语法,然而写入数据库总是报错,具体问题就不说了,有兴趣的同学可以自己试试。
但是毕竟研究了好多天,也把这个数据集的结构了解了大概,不想彻底放弃,最后就写了一个简单的诗歌查询功能,试了一下,还是比较方便,尤其现在我家小孩老师要求每天背古诗,所以给孩子查询古诗词的时候可以用用。
这里主要写了查询的简单逻辑结构,另外原来数据集全部是繁体字,这里也做了转换,这里用到了开源项目https://github.com/skydark/nstools/tree/master/zhtools,里面langconv.py文件,还有zh_wiki.py文件。
文件结构如下,这里只做了唐诗,宋词,曹操诗歌,的基本查询,其他诗歌文件其实做法基本一样,把函数重复利用一下就可以了,大同小异,只是数据结构可能稍微不同,读取和查询条件需要修改一下。
代码如下:这里加了pyttsx3 朗读诗词的输出(就是包含engine.say())的语句,不需要的可以关掉,不然一句一句输出太慢。
import pandas as pd
import numpy as np
import pymysql
from langconv import *
import os
import difflib
import pyttsx3
import time
def Traditional2Simplified(sentence):
'''
将sentence中的繁体字转为简体字
:param sentence: 待转换的句子
:return: 将句子中繁体字转换为简体字之后的句子
'''
sentence = Converter('zh-hans').convert(sentence)
return sentence
def Simplified2Traditional(sentence):
'''
将sentence中的简体字转为繁体字
:param sentence: 待转换的句子
:return: 将句子中简体字转换为繁体字之后的句子
'''
sentence = Converter('zh-hant').convert(sentence)
return sentence
def showpoet(json,author,titl,flg): #获取json 查找唐宋诗词 常用
try:
df = pd.read_json(json)
#print(df.keys())
#df=df[['author','paragraphs', 'title']]
#print(df.keys())
for auth, title,tx in zip(df['author'],df['title'],df['paragraphs']):
#if Simplified2Traditional(auth)==author or auth==author:
if Simplified2Traditional(author)== auth or author == auth or author == '':
if Simplified2Traditional(titl) in title or titl in title:
count.append('1')
print(Converter('zh-hans').convert(auth))
print(Converter('zh-hans').convert(title))
#engine.say('作者{0} 标题{1}'.format(auth,title))
#engine.runAndWait()
#engine.say('python 为您朗读' )
#engine.runAndWait()
for i in tx:
#Converter('zh-hans').convert(i)
ii=Traditional2Simplified(i)
print(ii)
#engine.say('{}'.format(ii))
#engine.runAndWait()
print('\n')
else:
pass
except Exception as e:
#print('核对输入作者{}是否正确,或者无匹配内容'.format(author))
pass
#print(e)
def ci(json,author,cp,flg):# pandas 读取ci集的文件 查找诗词
try:
df = pd.read_json(json)
#print(df.keys())
#df=df[['author','paragraphs', 'rhythmic']]
#print(df.keys())
for auth,tx,rhythmic in zip(df['author'],df['paragraphs'],df['rhythmic']):
if Simplified2Traditional(author) in auth or author in auth:
if Simplified2Traditional(cp) in rhythmic or cp in rhythmic :
count.append('1')
print(Converter('zh-hans').convert(auth))
print(Converter('zh-hans').convert(rhythmic))
for i in tx:
#Converter('zh-hans').convert(i)
ii=Traditional2Simplified(i)
print(ii)
print('\n')
else:
pass
except Exception as e:
#print(e)
#print('核对输入作者{}是否正确,或者无匹配内容'.format(author))
pass
def cao(json,title,flg):# pandas 读取曹操诗集的文件 查找诗词
try:
df = pd.read_json(json)
#print(df.keys())
#df=df[['author','paragraphs', 'rhythmic']]
#print(df.keys())
for t,p in zip(df["title"],df['paragraphs']):
if Simplified2Traditional(title) in t or title in t :
print(Converter('zh-hans').convert(t))
count.append('1')
for i in p:
#Converter('zh-hans').convert(i)
ii=Traditional2Simplified(i)
print(ii)
print('\n')
elif title=='a':
print(Converter('zh-hans').convert(t))
for i in p:
#Converter('zh-hans').convert(i)
ii=Traditional2Simplified(i)
print(ii)
print('\n')
except Exception as e:
#print(e)
#print('核对输入作者{}是否正确,或者无匹配内容')
pass
def walkFile(file): #用于获取指定文件夹里面所有诗词文件地址
for root, dirs, files in os.walk(file):
# root 表示当前访问的文件夹路径
# dirs 表示该文件夹下的子目录名list
# files 表示该文件夹下的文件list
# 遍历文件
for f in files:
#print(os.path.join(root, f))
json=os.path.join(root, f) #获取json诗歌文件传参给showpoet(json,author) ci(json,author) cao(json,title) 三个函数 读取诗词数据
if choice=='1':
showpoet(json,author,titl,flg)
elif choice=='2':
ci(json,author,cp,flg)
elif choice=='3':
cao(json,title,flg)
for d in dirs:
os.path.join(root, d)
#print(os.path.join(root, d))
def main( book):#book用来指定读取哪个诗词文件夹 顺便设置一下
walkFile("H:\\chinese-poetry\\{}".format(book))
def main2():
global choice,author,title,engine,cp,titl,flg,count
count=[]
flg=0
engine = pyttsx3.init()
rate = engine.getProperty('rate') # 获取当前语速
engine.setProperty('rate', 180) # 设置语速
file={'诗歌':'json','词':'ci','曹操':'caocaoshiji'}
choice=input('选择项目:1 诗歌,2 词,3 曹操诗集:\n')
if choice=='1':
book=file['诗歌']
author=input('输入作者,未知则输入空值: ')
titl=input('输入标题未知则输入空值: ')
print('\n')
main(book)
elif choice=='2':
book=file['词']
author=input('输入作者或者空: ')
cp=input('输入词牌名: ')
print('\n')
main(book)
elif choice=='3':
book=file['曹操']
title=input('输入曹操诗歌标题,输入a输出所有诗词: ')
print('\n')
main(book)
else:
print('选择错误,重新输入')
if count!=[]:
print('查询完毕')
print('共找到{}项内容'.format(len(count)))
print('\n')
else:
print('没有匹配到内容')
print('\n')
if __name__ == '__main__':
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
#pd.set_option('display.width', 180) # 设置pandas dataframe 的输出打印宽度(**重要**)
pd.set_option("display.max_colwidth", 5000)# 设置pandas dataframe 的输出column宽度(**重要**)
while True:
main2()
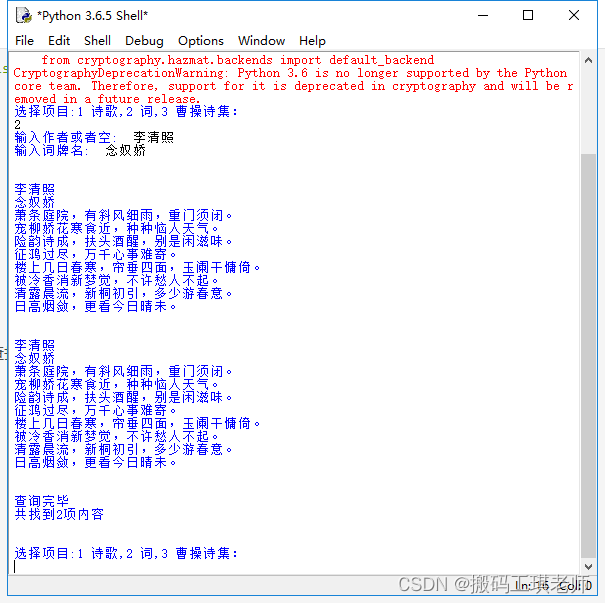
效果如下,扫描到查找的诗人或者诗句,就会输出诗句,同时显示文件位置。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











