背景:基于手掌识别的应用这里研究的是haar-like特征,上一篇博文用的是LBP,但是发现LBP效果没有haar-like特征那么好,故只研究了haar-like特征,那么自然而然的就想知道其原理是如何运作的,故有了下面的研究,研究过程中参照了许多大牛写的文章和论文,故我只讲我学习到的内容写下来。而且下面的方向的实现还很不理想,在关于手的识别中,当背景复杂的情况下,错误率太高,得想办法解决或者等大牛指教,原本此文是记录在我的有道云笔记上,转移到此处,有点麻烦呀。
2.2Adaboost算法工作流程和细节
首先,算法的流程是分
训练和
识别部分。
一定程度上来说,训练就是提取能够与手匹配的多个弱分类器(实质是多个特征值)组合成强分类器(能较精确区分检测的物体)。识别就是提取那副图与训练部分强分类器对应的特征值进行比较。
训练部分
1.准备好大量的正例(包含检测物体,也就是手)和反例(不包含检测物体)的图片。
2.将图片进行归一化,也就是转灰度和调整为统一分辨率并进行如下的预处理。
A:给定一系列训练样本(x1,y1),(x2,y2),(x3,y3)....(xn,yn)其中yi=0表示其为负样本,yi=1表示其为正样本,n为一共训练样本的数量。
B:初始化权重W1,i = D(i)(D(i)=1/2m对负样本,D(i)=1/2t对于正样本,其中m和t分别是负样本和正样本的数量,m+t=n)
C:对t=1....T
1.归一化权重
3.计算正反例所有样本从灰度图转化为积分图。
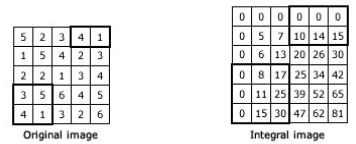
积分图:首先我们知道灰度图每个像素点的取值范围是0~255,全黑是0,全白是255。我们在这里取一张5x5像素的灰度图和积分图来说明积分图是个什么?如下图所示
左边为灰度图,右边为积分图,我们先从灰度图左上角的四个元素来看看,他们的值分别是5,2,1,5求和的话值为13,再来看右边,积分图的第三行和第三列的值为13。现在我们记灰度图每个点的值为i(x,y)而积分图每个点的值为x(x,y)下标都从0开始,那么积分图的每一点对应的值都是其对应坐标的左上角部分的灰度值的和。
在程序中,计算一张灰度图图的积分图通过下面两个公式循环求得
s(2,2) = s(2,1) + i(2,2) = 2 + 5 = 7 这里s(2,2)的列值在原图中是(1,1)列上两个值2 + 5 = 7,而i(2,2)在原图中是(1,1)列的值5,这里需要注意一下。
ii(2,2) = ii(1,2) + s(2,2) = 6 + 7 = 13
好,s(x,y)的意义在这里通过示范也能够理解了。
4.用积分图计算正反例对应存在的所有Haar-like特征值(也可以是其他特征,但是算法的框架并不会改变)。
Haar特征:Haar-like特征的定义是黑色矩阵和白色矩阵在图像窗口中对应的区域的权重灰度级总和之差。
Q1:那么Haar-like特征的分类为多少种?
A1:其实Haar特征主要分为3类:边缘特征,线性特征,中心特征和对角特征组合成特征模板。(如上图所示)特征模板中有白色和黑色的两种矩阵,并定义该模板的
特征值为白色矩形像素和减去黑色矩形像素和。在确定了特征形式之后,Haar-like特征的数量就取决于训练样本图像矩阵的大小,特征模板在子窗口中任意放置,一种形态成为一种特征,找出所有的子窗口的特征是进行弱分类器的基础。
Haar-like特征值=白色像素的总和-黑色像素的总和
为了更好理解下面所述的内容,其实特征在现实世界中,应该是这样的,如下图所示
图中红色框出来的部分其实可以等同于右边的Haar特征,而下面要描述的其实也就是要在样本中寻找所有的这样的特征并计算其相应特征值找到适合的能够区别物体存在与否的特征值,其实说白了,分类器其实就是包装好的特殊的特征值。
Q2:一张灰度图片的Haar-like特征有多少个?
A2:其实这是个数学问题,这里参考别人的博文进行一下说明
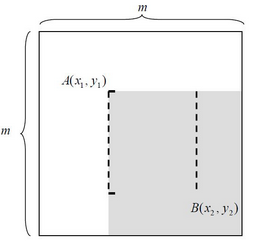
如图所示的一个m*m大小的子窗口,可以计算在这么大的子窗口内存在多少个矩形特征。
以 m×m 像素分辨率的检测器为例,其内部存在的满足特定条件的所有矩形的总数可以这样计算:
对于 m×m 子窗口,我们只需要确定了矩形左上顶点A(x1,y1)和右下顶点B(x2,63) ,即可以确定一个矩形;如果这个矩形还必须满足下面两个条件(称为(s, t)条件,满足(s, t)条件的矩形称为条件矩形)
1) x 方向边长必须能被自然数s 整除(能均等分成s 段);
2) y 方向边长必须能被自然数t 整除(能均等分成t 段);
则 , 这个矩形的最小尺寸为s×t 或t×s, 最大尺寸为[m/s]·s×[m/t]·t 或[m/t]·t×[m/s]·s;其中[ ]为取整运算符。
由上分析可知,在m×m 子窗口中,满足(s, t)条件的所有矩形的数量为:
实际上,(s, t)条件描述了矩形特征的特征,下面列出了不同矩形特征对应的(s, t)条件:
下面以 24×24 子窗口为例,具体计算其特征总数量:
Q3:知道了特征数量,如何计算每个特征的特征值?
A3:Haar-like的特征值=特征白色区域像素总和-黑色区域像素总和,下面我们以特征模板1为例,如下图所示
特征值=A像素值总和-B像素值总和
他们的值只需要在对应的积分图上查找即可。
5.找出弱分类器(分类器其实就是特殊包装好的特征值)
Q1.计算出了特征值,那么怎么找出能够分辨图片的阈值(特殊的特征值)?
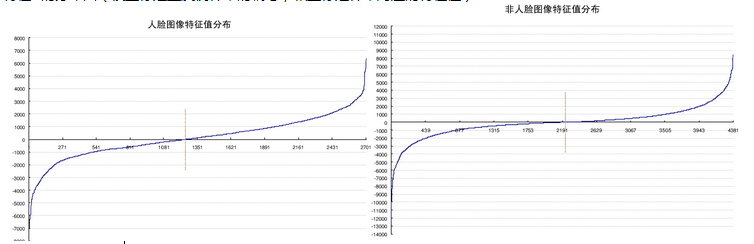
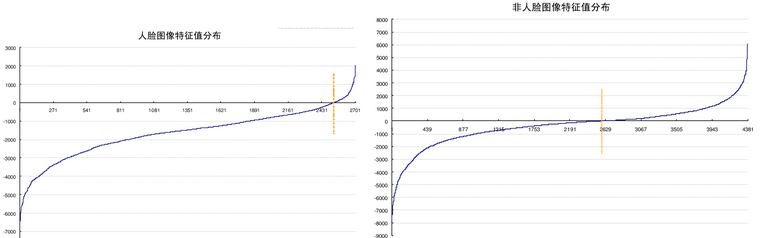
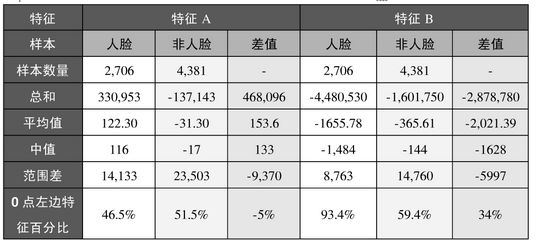
A1:为了更好的说明问题,我们从78460个矩阵中随机抽取了两个特征A和B,这两个特征遍历了2706个人脸样本和4381个非人脸样本,计算了每张图像对应的特征值,然后将特征值从小到大的排序,并按照这个顺序绘制了分布图,如下面的两幅图所示,一些统计数据如下
特征A的分布图(横坐标是正反例样本的编号,纵坐标是样本对应的特征值)
可以看到,对照特征A的分布图,特征A对人脸和非人脸的样本特征值为0的点几乎都处于相同的位置(46.5% 51.5%),这说明矩阵特征A对人脸和非人脸几乎没有分辨能力。然而对照特征B的分布图,特征B则表现了很一致性的倾向性,93.4%的特征都在0点的一侧,与非人脸的分布相差34%。这说明B能够相当可靠的分辨人脸和非人脸。
那么,这样循环遍历全部的特征,便能够得到具有分辨能力的阈值。有了上面的理解,那么我们接下来便来看看弱分类器的定义
弱分类器的定义:
一个弱分类器由一个特征f,阈值
![]()
和指示不等号方向的p组成。(有了上面的解释,这个定义也就很好理解了)
但是,别着急,还没有玩,程序挑选一个弱分类器需要进行下面的筛选
对
每个特征f,计算所有训练样本的特征值,并将其进行排序,通过扫描一遍排好序的特征值,可以为这个特征确定一个最阈值(可以通过特征值的分布进行确定)从而训练成一个弱分类器,具体来说,对排好序的每个元素(指排序表中一个对应某个样本的特征值),计算下面的四个值:
1)全部正例样本权重的和T+;
2)全部负例样本权重的和T-
3)在此元素之前正例样本的权重的和S+
4)在此元素之前负例样本的权值的和S-
这样,当选取当前元素的特征值和Fk和他前面的一个特征值Fk-1之间的数作为阈值时,所得到的弱分类器就在当前元素处把样本分开,也就是这个阈值对应的弱分类器将当前元素前所有的元素分类为正例(反例),而把当前元素后所有元素后分类为反例(正例)
可以认为这个阈值所带来的分类误差(
也就是加权错误率)为
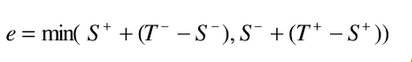 (其实不明白为什么是这样计算加权错误率)
(其实不明白为什么是这样计算加权错误率)
于是,通过把这个排序的表从头到尾扫描一遍就可以为弱分类器选择使
分类误差最小的加权错误率![]() t
t(
也就是e值最小对应的阈值),也就是选取了一个最佳弱分类器。
程序会将错误率小于50%的分类器选择出来。
接下来便是对选择出来的弱分类器进行检测,让他对现有存在的所有样本库进行判断,并对判断错误的样本进行权重的调整
具体过程如下
其中ei=0表示被正确的分类,ei=1表示被错误的分类;
6.将多个弱分类器组合成强分类器
经过过程5的T次迭代后,便得到T个弱分类器和其对应的加权错误率,那么最后组合成的强分类器便是由多个弱分类器加权投票对图像的物体进行检测的。由此可知,强分类器的定义如下。
其中
7,级联分类器
将得到弱分类器进行划分成几组,按照错误率递减进行划分,每组再组合成一个强分类器,使得每一层都能让几乎全部的人脸样本通过, 而拒绝很大一部分非人脸样本. 而且,由于前面的层使用的矩形特征数很少,计算起来非常快,越往后通过的候选匹配图像越少.即串联时应遵循“先重后轻”的分级分类器思想,将由更重要特征构成的结构较简单的强分类器放在前面,这样可以先排除大量的假样本. 尽管随着级数的增多矩形特征在增多,但计算量却在减少,检测的速度在加快,使系统具有很好的实时性。
8.生成记录强分类器的xml文件
xml文档记录了样本图片的尺寸,强分类器的值,和分类器所对应的特征值在图片中的坐标。
识别部分
1.图像输入,将其进行转灰度,并计算积分图。
2.读取训练生成的强分类器,生成扫描窗口(初始时为训练样本图像的尺寸,但其尺寸可以变化)
3.对图片进行窗口扫描,并计算当前窗口的对应坐标的特征值与分类器中特征值进行匹配。
4.得到匹配的坐标并在图像中框出来。
5.计算其坐标在9宫格的位置,并将其位置信息用文本显示出来。
Q1;为什么扫描的窗口是可以变化的?
A1:
在对输入图像进行检测的时候,一般输入图像都会比20*20的训练样本大很多。
在Adaboost 算法中采用了扩大检测窗口的方法,而不是缩小图片。
为什么扩大检测窗口而不是缩小图片呢,在以前的图像检测中,一般都是将图片连续缩小十一级,然后对每一级的图像进行检测,最后在对检测出的每一级结果进行汇总。然而,有个问题就是,使用级联分类器的AdaBoost的人脸检测算法的速度非常的快,不可能采用图像缩放的方法,因为仅仅是把图像缩放11级的处理,就要消耗一秒钟至少,已经不能达到Adaboost 的实时处理的要求了。
因为Haar特征具有与检测窗口大小无关的特性(不知道怎么证明,但是感觉好像是如此),所以可以将检测窗口进行级别方法。
在检测的最初,检测窗口和样本大小一致,然后按照一定的尺度参数(即每次移动的像素个数,向左然后向下)进行移动,遍历整个图像,标出可能的人脸区域。遍历完以后按照指定的放大的倍数参数放大检测窗口,然后在进行一次图像遍历;这样不停的放大检测窗口对检测图像进行遍历,直到检测窗口超过原图像的一半以后停止遍历。因为 整个算法的过程非常快,即使是遍历了这么多次,根据不同电脑的配置大概处理一幅图像也就是几十毫秒到一百毫秒左右。
在检测窗口遍历完一次图像后,处理重叠的检测到的人脸区域,进行合并等操作。
关于具体代码和实现的部分,可以参照我7.15-7.20日的笔记,链接如下
http://note.youdao.com/share/?id=92ab0230be24f8e2fd884eaafec4c12d&type=note
3.总结
通过对此Adaboost算法的学习,我们能够实时的对图像的感兴趣的物体进行识别,而且做到了和之前的算法相比(我们之前的算法是通对手势的视频通过pca降维提取特征再对采集的视频进行降维和比较),有了精度和时间上的突破。
运用了此算法,能够达到了对手的识别,识别率大概在60%左右(随着样本数量的增多,识别率将会增加),而且对动作也具有了一定初步的判断。
参考:









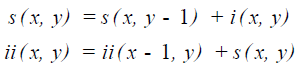


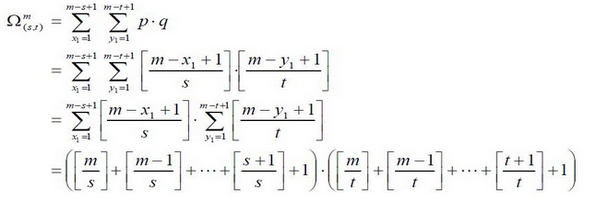


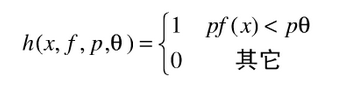
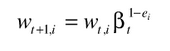
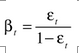
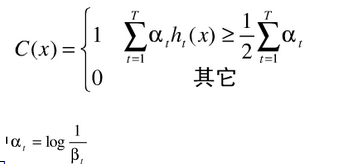















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









