







之前写了一篇selenium + ChromeDriver的一些入门的知识,这篇博客里面找了启信宝这个网站,简单的进行了一个实战练习。本篇博客的结构如下:
首先会给出一些使用 selenium + ChromeDriver的入门的一些友情链接
其次讲解一下本人在爬取网站的一些思路和流程
最后给 出github地址并总结经验。
1. 友情链接
环境配置以及入门知识参考我的之前一篇博客:
详细使用方式参考webDriver中文社区:
使用过程的常见异常参考他人博客:
2. 爬取思路及流程
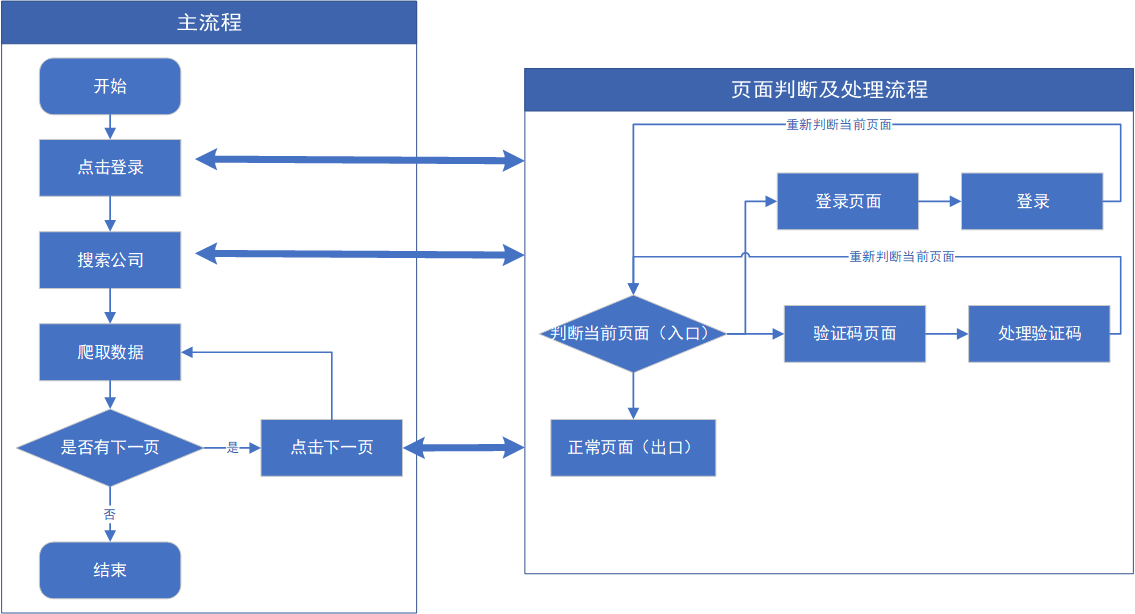
整体的爬取思路见上图,分为两个流程的原因是:在点击页面去向另一个页面时会出现让你登陆或者数据验证码的情况。如果每一步都要进行判断不好管理,还不如直接放在一个方法里面进行管理。只要每次有点击页面链接或者按钮的情况都进入到页面判断及处理流程中去。通过这个方法判断你新进入的页面是什么情况,并且对不同的页面进行不同的处理。下面对每个步骤进行详细讲解
2.1 点击登录
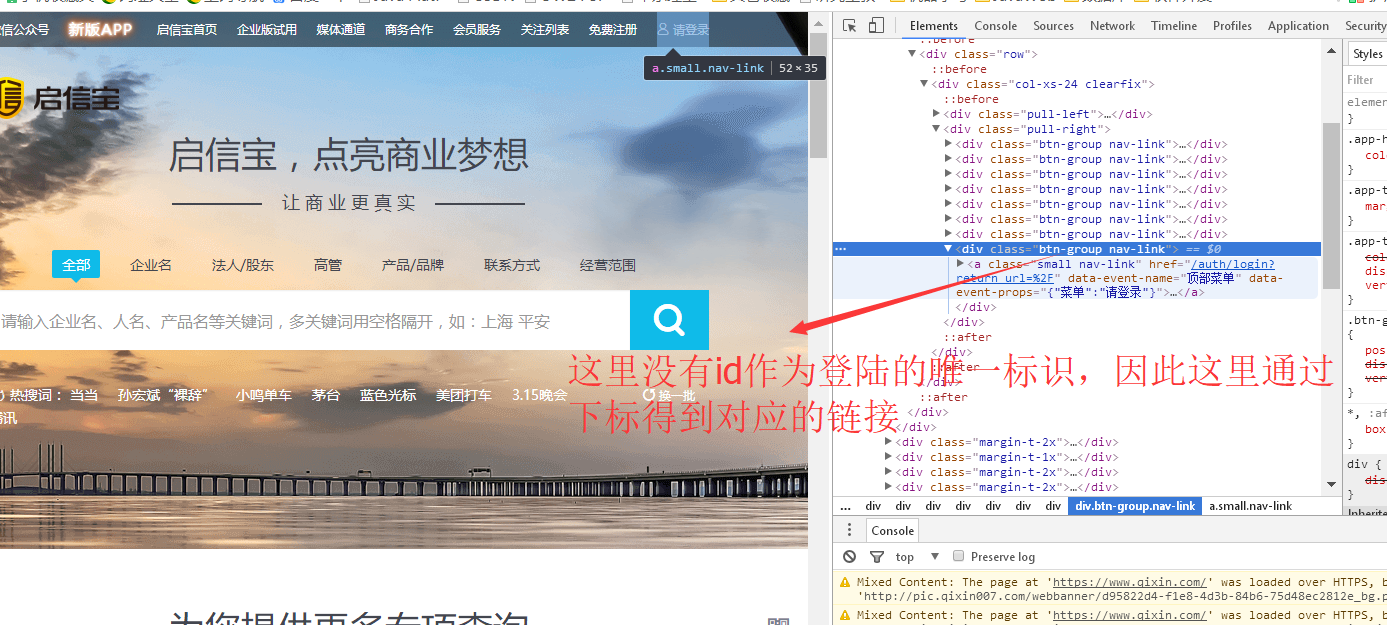
1 //去登陆页面并且登录
2 public static void toLoginAndLogin(WebDriver driver) {
3 //1、去登陆页面
4 List<WebElement> elements = driver.findElements(By.cssSelector("div.pull-right a"));
5 //2、通过下标得到对应的登录链接
6 WebElement lo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









