







前言
Solr 是一种可供企业使用的、基于 Lucene 的搜索服务器,它支持层面搜索、命中醒目显示和多种输出格式。
Solr对外提供标准的http接口来实现对数据的索引的增加、删除、修改、查询。在Solr中,用户通过向部署在servlet 容器中的Solr Web应用程序发送HTTP 请求来启动索引和搜索。
公司项目需要增加全文搜索功能。所以学习搭建了solr服务。
我使用的项目环境:
- Java运行环境(JRE)版本1.6。
- apache-tomcat-6.0.44。
- solr-4.6.1。
solr安装与配置
第一步: exmaple/webapps中的solr.war包解压开复制到Tomcat webapps中,或者直接将solr.war包直接复制到Tomcat的webapps中,然后启动Tomcat使其解压开再将war包删除。这时如果启动Tomcat是会报错的,因为我们没有设置solr_home(也就是索引和配置文件所在的目录)。
第二步: 配置solr_home。编辑solr_server\webapps\solr\WEB-INF\web.xml中内容,添加以下内容:
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>..\webapps\solr\solr_home</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>配置完了还需要在配置的路径处放置一个文件夹作为SOLR_HOME(solr的example中已经提供),我们将example/solr目录拷贝到solr项目目录下(这里是%TOMCAT_HOME%/webapps/solr/),并重命名为solr_home(根据自己的配置决定)。
第三步: 添加日志相关包。复制example/lib/ext目录中的jar包到项目的classpath下,可以将这些jar包放到/webapps/solr/WEB-INF/lib下。
example/resources/log4j.properties也拷到classpath(我在/solr_server/webapps/solr/目录下新建了一个classes目录,放log4j.properties放了进去)
第四步:启动tomcat,查看。
如下页面说明安装成功:
使用中文分词mmseg4j
下载mmseg4j分词器:https://code.google.com/p/mmseg4j/
我使用的版本为:mmseg4j-1.9.1。
在mmseg4j-1.9.1\dist下有以下三个包:
- mmseg4j-core-1.9.1.jar 包括词库文件
- mmseg4j-analysis-1.9.1.jar 是一些 analysis
- mmseg4j-solr-1.9.1.jar 是一些 solr 使用的功能。
在 solr 中使用需要使用以上三个 *.jar 放到 solr 实例目录的 lib 目录下(\solr\WEB-INF\lib)
schema.xml配置
在mmseg4j-1.9.0前。需要copy data目录到solr_home/solr中,并改名为dic(或者网上下载分词库,如搜狗等,为*.dic文件)。进入到你想使用mmseg4j分词器的core中(此处以solr自带的collection1为例),用编辑器打开collection1/conf/schema.xml配置文件,添加如下代码:
<!-- mmseg4j分词器 --> <fieldType name="text_mmseg4j" class="solr.TextField" > <analyzer type="index"> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="../dic" /><!--此处为分词器词典所处位置--> </analyzer> <analyzer type="query"> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="../dic" /><!--此处为分词器词典所处位置--> </analyzer> </fieldType>在mmseg4j-1.9.0后,如本例的mmseg4j-1.9.1中 ,就 可以不用 dicPath 参数,可以使用 mmseg4j-core-1.9.0.jar 里的 words.dic ,在Schema.xml中加入如下配置:
<!-- mmseg4j--> <fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/> </analyzer> </fieldType> <fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="dic"/> </analyzer> </fieldType> <fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" > <analyzer> <!-- <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="n:/OpenSource/apache-solr-1.3.0/example/solr/my_dic"/> --> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="dic"/> </analyzer> </fieldType> <!-- mmseg4j-->
引用mmseg4j分词器
只需要在该schema.xml中加入如下配置便可引用对应的mmseg4j分词器:
<field name="mmseg4j_complex_name" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="mmseg4j_maxword_name" type="text_mmseg4j_maxword" indexed="true" stored="true"/>
<field name="mmseg4j_simple_name" type="text_mmseg4j_simple" indexed="true" stored="true"/>
通过以上步骤就可以成功配置mmseg4j分词器到solr中了。
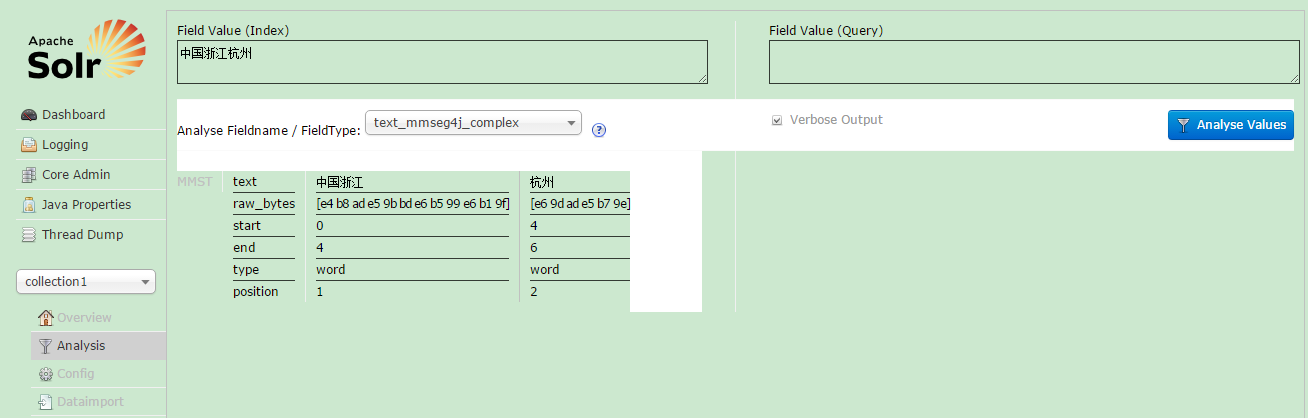
然后就可以打开Solr Admin的Page进行分词分析了。但当输入中文(如中国浙江杭州)并点击“Analyse Values”进行分析时,会发现如下的错误:
TokenStream contract violation: reset()/close() call missing, reset() called multiple times, or subclass does not call super.reset(). Please see Javadocs of TokenStream class for more information about the correct consuming workflow.
该原因是源码的一个bug引起的,需要修改上面下载的mmseg4j-analysis-1.9.1.zip解压后的mmseg4j-analysis目录下的类:MMSegTokenizer.java,修改reset()方法并加上下面注释中的这一句:
public void reset() throws IOException {
//lucene 4.0
//org.apache.lucene.analysis.Tokenizer.setReader(Reader)
//setReader 自动被调用, input 自动被设置。
super.reset(); //加这一句
mmSeg.reset(input);
}
修改后可以使用eclipse将整个solr源码文件当做MVN项目导入,然后重新导出mmseg4j-analysis-1.9.1.jar 包,并放入自己的项目中。即可。
重新启动Tomcat并访问Solr Admin Page,并在“Analysis”中输入中文进行分析,可以看到已经成功的进行分析:
sorl对数据库建立索引
数据库使用mysql数据库
solrconfig.xml配置
在solr\solr_home\collection1\conf中找到solrconfig.xml,添加<!-- DataImportHandler --> <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">db-data-config.xml</str> </lst> </requestHandler>在solr\solr_home\collection1\conf下创建db-data-config.xml文件,并添加内容:
<dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8" user="root" password="root" /> <document name="test" pk="id"> <entity name="user_inf" transformer="ClobTransformer" query="select id,realname,position,username,sex from user_inf"> <field column="id" name="id" /> <field column="realname" name="realname" /> <field column="position" name="position" /> <field column="username" name="username" /> <field column="sex" name="sex" /> </entity> </document> </dataConfig>说明:
dataSource是数据库数据源。
Entity就是一张表对应的实体,pk是主键,query是查询语句。
Field对应一个字段,column是数据库里的column名,后面的name属性对应着Solr的Filed的名字。
修改同目录下的schema.xml,这是Solr对数据库里的数据进行索引的模式
(1)保留_version_ 这个field
(2)添加索引字段:这里每个field的name要和data-config.xml里的entity的field的name一样,一一对应。
<field name="realname" type="text_general" indexed="true" stored="true"/> <field name="position" type="text_general" indexed="true" stored="true"/> <field name="username" type="text_general" indexed="true" stored="true"/> <field name="sex" type="text_general" indexed="true" stored="true"/>(3)可以将多余的field删除,删除copyField里的设置,这些用不上。注意:text这个field不能删除,否则Solr启动失败。
拷贝mysql-connector-java-5.1.22-bin.jar和solr-dataimporthandler-4.10.3.jar到D:\Solr\solr-4.10.3\example\solr-webapp\webapp\WEB-INF\lib。一个是mysql的java驱动,另一个在D:\Solr\solr-4.10.3\dist目录里,是org.apache.solr.handler.dataimport.DataImportHandler所在的jar包。
测试。
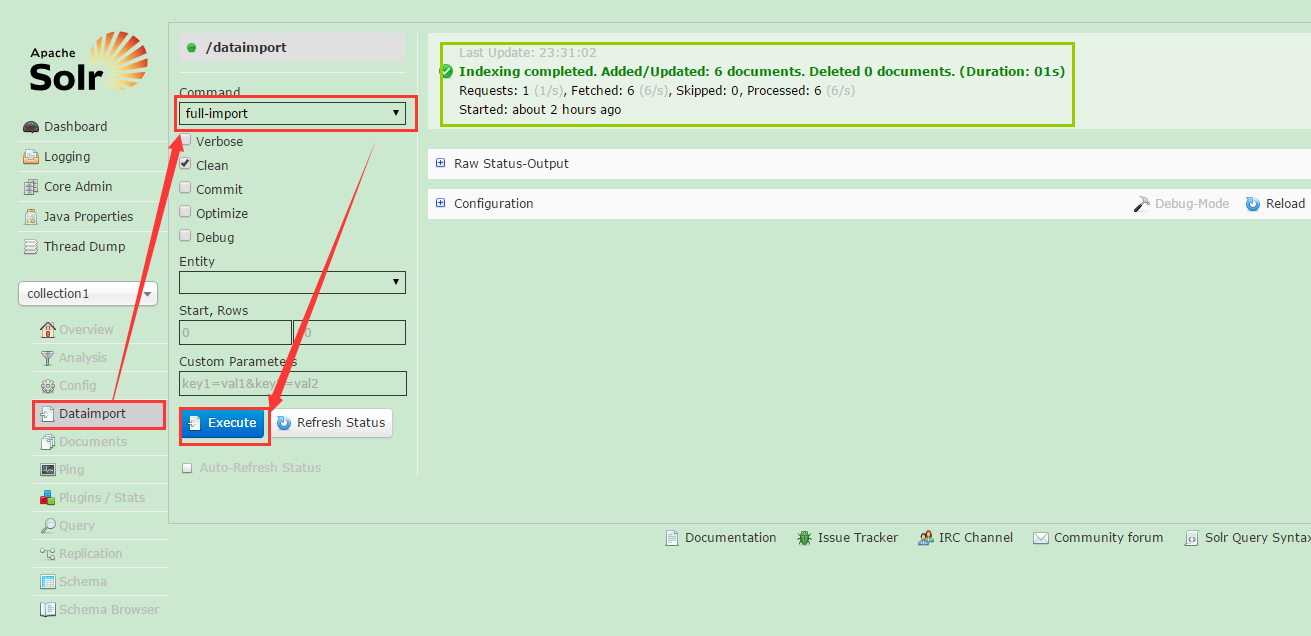
点击execute按钮后,稍等一段时间可点击refresh status按钮刷新,若看到绿框内的内容,说明导入成功。
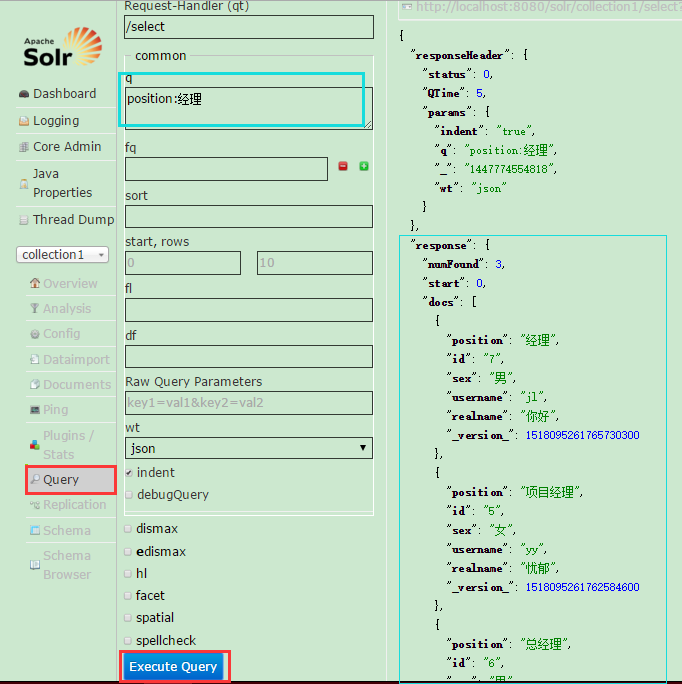
这里可以查询到数据库导入的数据,通过设置q蓝框内的字段名:值,可以设置查询条件。
问题解决
严重: Exception starting filter SolrRequestFilter
java.lang.UnsupportedClassVersionError: org/apache/solr/servlet/SolrDispatchFilter : Unsupported major.minor version 51.0 (unable to load class org.apache.solr.servlet.SolrDispatchFilter)
解决方法:
Unsupported major.minor version 51.0
说明solr编译的jdk与现在使用的jdk版本不支持,是因为所运行环境的jdk版本太低。在下载solr之前,需要先确定solr的版本, 目前最新版本是 4.10.1,但是在 4.8 以后需要编译在1.7的版本。所以如果是JDK1.6环境,建议使用4.8之前的版本(例如4.7.2)。
参考
中文分词整合参考:http://www.tuicool.com/articles/67BFFz
数据库数据导入生成索引:http://www.sjsjw.com/kf_jiagou/article/32_31269_3639.asp
Solr索引MySQL数据:http://www.cnblogs.com/luxiaoxun/p/4442770.html
lucene简单介绍及solr搭建使 用:http://download.csdn.net/detail/u013569416/9280891















 9535
9535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









