







读流程
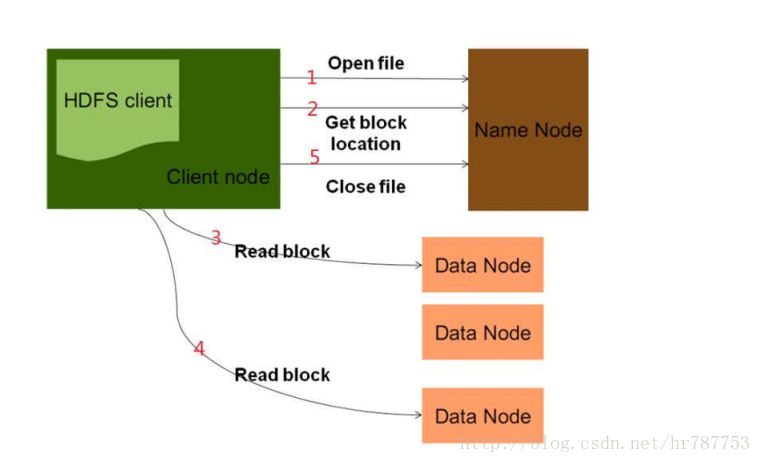
1.openfile 客户端 指定文件的读取路径
2.从namenode那里得到文件块的存储位置(元数据信息)
3.根据元数据信息 去指定的datanode上读文件。如果文件特别大,namenode不会一次性把所有的块信息给客户端 ,而是客户端读一部分,读完之后再找namenode去要。如此循环,知道全部读完。
4.读完之后,关闭输入流
写流程
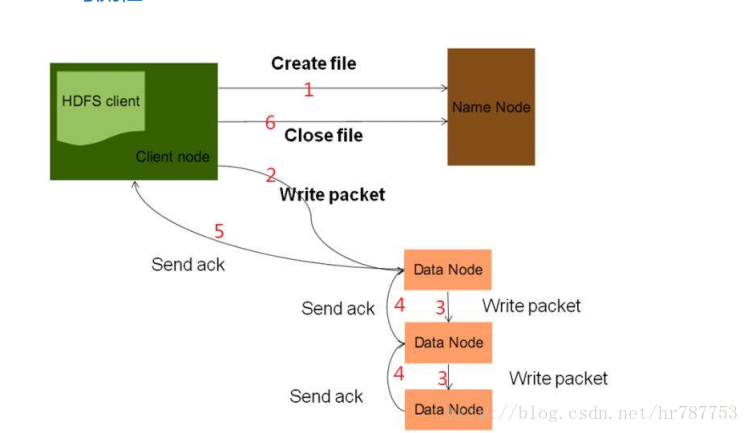
1.create file 客户端获取文件输出流,并指定文件的上传路径,namenode收到后会检查当前客户端是否具有写权限,以及路径的合法性。
2,3,4,5 客户端拿到输出流,如果文件过大,会对文件进行切块,有namenode分配块和副本的存放位置。比如130mb 的文件,切成两块。拿第一个文件块举例,有3个副本,即存储
到3个datanode。此时,在传输的过程中,会形成一个数据流管道,pipeline。
d1-d3-d7。pipeline的工作原理:一个文件块会被先发送到管道里的第一个
datanode=》发给第二个datanode=》发给第三个datanode,于此同时,每个
datanode收到数据块之后,会发送一个ack,依次向上游返回。等第一个文件块的
三个副本都确认复制后之后,再去发送下一个数据块。pipeline设计的目的是充分
利用每台机器的带宽,最小化降低数据推送的延迟。此外,这里用到了通信领域的
全双工通信模式,同时可进行收发。会把一个文件块打散成一个一个128kb大小的
数据包(packet)进行传输
6.写完之后,关输出流
MapReduce执行原理:
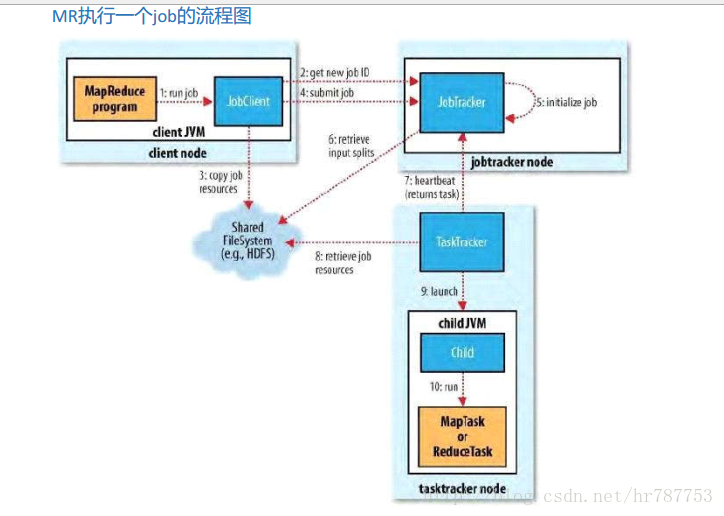
1.run job 客户端启动,收集job的环境信息,输入输出路径是否合法,不合法报错
2.get new jobid 客户端向jobTracker申请一个唯一性id ,通过这个id唯一性标识当前job,可以根据jobid 查看job 终止job
3.客户端将运算资源(算法job) 上传到hdfs上
4.提交job,告诉jobtracker 可以运行job了
5.jobtracker 初始化job
6.jontracker根据切片数量 计算出map任务的数量 并根据分区数量计算出reduce任务的数量
7.tasktracker发送心跳包的时候领取任务, 对于任务的分配是 :数据的本地化策略。hadoop移动的是运算,而不是数据
8.tasktracker 去hdfs上下载运算资源
9.启动jvm 运行运算资源
10 运算
11处理好的文件 上传到hdfs上。















 2766
2766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









