







1.基本概念
首先需要科普一下,最长公共子序列(longest common sequence)和最长公共子串(longest common substring)不是一回事儿。什么是子序列呢?即一个给定的序列的子序列,就是将给定序列中零个或多个元素去掉之后得到的结果。什么是子串呢?给定串中任意个连续的字符组成的子序列称为该串的子串。给一个图再解释一下:
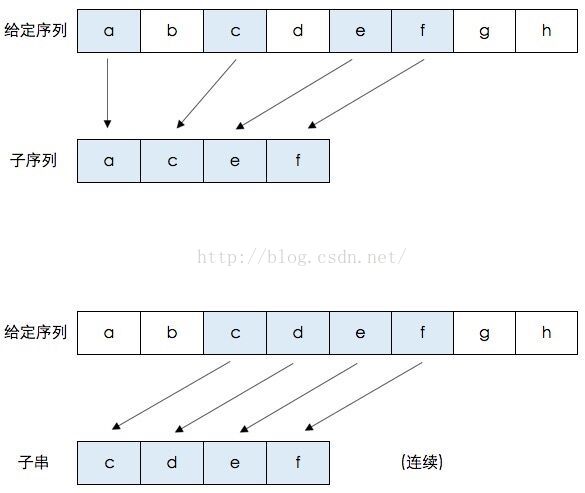
如上图,给定的字符序列: {a,b,c,d,e,f,g,h},它的子序列示例: {a,c,e,f} 即元素b,d,g,h被去掉后,保持原有的元素序列所得到的结果就是子序列。同理,{a,h},{c,d,e}等都是它的子序列。
它的字串示例:{c,d,e,f} 即连续元素c,d,e,f组成的串是给定序列的字串。同理,{a,b,c,d},{g,h}等都是它的字串。
这个问题说明白后,最长公共子序列(以下都简称LCS)就很好理解了。
给定序列s1={1,3,4,5,6,7,7,8},s2={3,5,7,4,8,6,7,8,2},s1和s2的相同子序列,且该子序列的长度最长,即是LCS。
s1和s2的其中一个最长公共子序列是 {3,4,6,7,8}
2.动态规划
求解LCS问题,不能使用暴力搜索方法。一个长度为n的序列拥有 2的n次方个子序列,它的时间复杂度是指数阶,太恐怖了。解决LCS问题,需要借助动态规划的思想。
动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。如果我们能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。我们可以用一个表来记录所有已解的子问题的答案。不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。这就是动态规划法的基本思路。
3.特征分析
解决LCS问题,需要把原问题分解成若干个子问题,所以需要刻画LCS的特征。
设A=“a0,a1,…,am”,B=“b0,b1,…,bn”,且Z=“z0,z1,…,zk”为它们的最长公共子序列。不难证明有以下性质:
如果am=bn,则zk=am=bn,且“z0,z1,…,z(k-1)”是“a0,a1,…,a(m-1)”和“b0,b1,…,b(n-1)”的一个最长公共子序列;
如果am!=bn,则若zk!=am,蕴涵“z0,z1&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









