










获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读

引言:挑战无限长输入的边界
在人工智能领域,尤其是自然语言处理(NLP)的进展中,Transformer模型已经成为了一种革命性的技术,它极大地推动了机器翻译、文本摘要、问答系统等任务的发展。然而,尽管Transformer模型在处理短文本时表现出色,但它们在处理长文本时却遇到了瓶颈。这是因为标准的Transformer模型在设计时,并没有考虑到处理极长序列的需求,其注意力机制的内存和计算需求随着输入长度的增加而呈二次方增长,这限制了模型处理长文本的能力。
为了突破这一限制,研究人员提出了各种方法来扩展Transformer模型的能力,使其能够有效处理长序列。这些方法包括引入稀疏注意力机制、使用层次化注意力结构等。然而,这些方法要么牺牲了模型的性能,要么增加了模型的复杂度,使得训练和推理变得更加困难。
在这一背景下,本文介绍了一种新的方法,旨在使Transformer基于的大型语言模型(LLMs)能够以有界的内存和计算需求处理无限长的输入。我们提出了一种名为Infini-attention的新型注意力技术,它通过将压缩记忆集成到标准注意力机制中,实现了在单个Transformer块中同时构建遮蔽局部注意力和长期线性注意力机制。我们在长上下文语言建模基准测试、1M序列长度的密钥上下文块检索和500K长度的书籍摘要任务上验证了我们方法的有效性。我们的方法引入了最小的有界内存参数,并为LLMs启用了快速流式推理。
论文标题:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
机构:Google
论文链接:https://arxiv.org/pdf/2404.07143.pdf
Infini-attention机制介绍
在处理长序列数据时,传统的Transformer模型面临着显著的挑战,主要是由于其注意力机制在内存和计算上的二次方复杂度。为了克服这一限制,本文提出了一种新型的注意力技术,称为Infini-attention。Infini-attention机制通过将压缩记忆系统整合到标准的注意力机制中,有效地扩展了Transformer模型处理无限长输入的能力,同时保持有界的内存和计算需求。
1. 设计理念
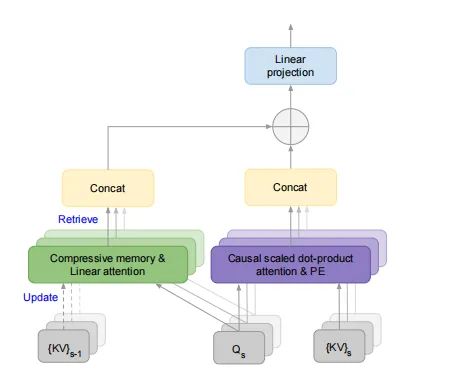
Infini-attention的核心设计理念在于重用和压缩标准注意力计算中的键(Key)、值(Value)和查询(Query)状态。通过存储旧的键值(KV)状态而不是像标准注意力机制那样丢弃它们,Infini-attention能够在处理后续序列时,利用查询状态从压缩记忆中检索值。这一机制不仅减少了内存需求,还加快了训练和推理速度。
2. 结构组成
Infini-attention在单个Transformer块中同时构建了遮蔽的局部注意力和长期的线性注意力机制。这种结构的创新之处在于,它允许模型在不增加额外计算负担的情况下,有效地处理长距离依赖关系。此外,Infini-attention通过学习一个门控标量来平衡长期记忆检索的内容和局部注意力上下文,从而实现了对长短期信息流的灵活控制。
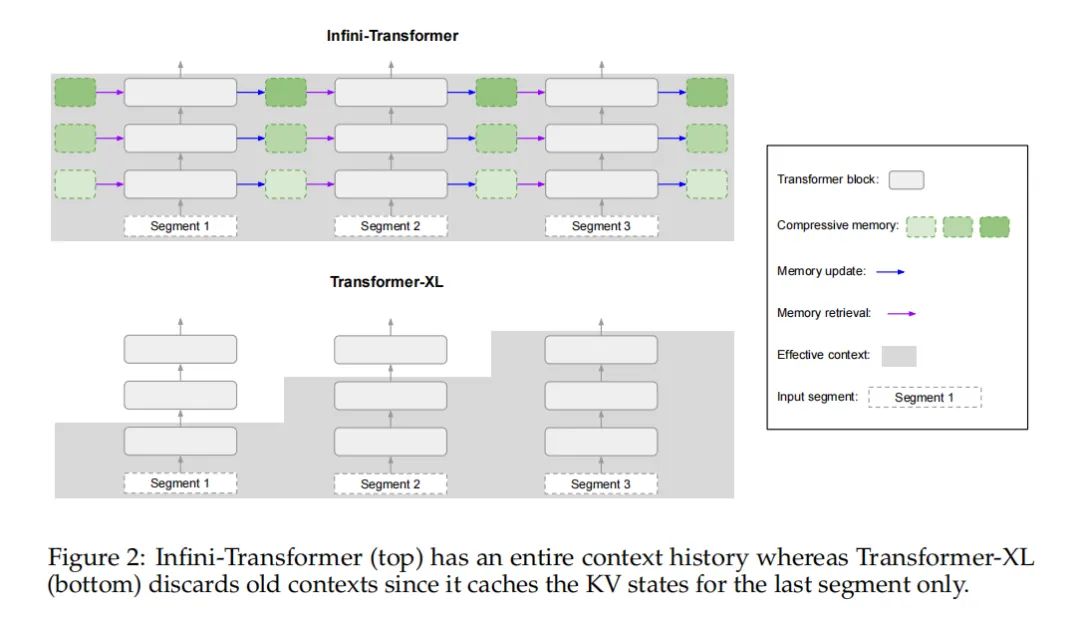
压缩记忆系统的优势
压缩记忆系统是Infini-attention机制的关键组成部分,它为处理极长序列提供了一种更可扩展和高效的解决方案。
1. 有界的内存和计算成本
与传统的注意力机制相比,压缩记忆系统通过维持固定数量的参数来存储和回忆信息,从而显著降低了存储和计算成本。这种设计使得模型能够以线性的复杂度处理任意长度的输入,解决了标准Transformer模型在处理长序列时面临的内存瓶颈问题。
2. 高效的信息检索和更新
通过参数化的关联矩阵,压缩记忆系统能够以线性注意力机制的形式进行高效的信息检索和更新。这一机制不仅简化了记忆系统的设计,还利用了稳定的训练技术,进一步提高了模型的性能和可靠性。此外,Infini-attention采用了改进的记忆更新规则(线性+Delta规则),在保持关联矩阵不变的同时,通过先检索现有值条目再应用关联绑定作为新更新,实现了更精确的记忆管理。
3. 实验验证
在长上下文语言建模基准测试中,采用Infini-attention的模型在内存大小方面实现了114倍的压缩比,同时在性能上也超越了基线模型。这一结果证明了压缩记忆系统在处理极长序列时的优势,为大型语言模型的长期上下文建模提供了一种有效的解决方案。
综上所述,Infini-attention机制通过其独特的设计和压缩记忆系统,成功地扩展了Transformer模型处理无限长输入的能力,同时显著降低了内存和计算成本。这一创新不仅为长序列数据的处理提供了新的视角,也为未来大型语言模型的发展开辟了新的可能性。
实验设计与结果分析
在本研究中,我们采用了一种新颖的注意力技术——Infini-attention,旨在解决传统Transformer模型在处理极长输入时遇到的内存和计算资源限制问题。Infini-attention通过将压缩记忆融入标准的注意力机制中,实现了对无限长输入的有效处理,同时保持有界的内存占用和计算量。
1. 实验设计
我们的实验设计包括三个主要部分:长上下文语言建模、1M长度的密钥上下文块检索任务和500K长度的书籍摘要任务。这些任务旨在评估Infini-attention在处理极长输入序列时的有效性和效率。
长上下文语言建模:我们在PG19和Arxiv-math基准数据集上训练和评估了小型Infini-Transformer模型。所有模型均配置有12层和8个注意力头,每个头的维度为128,FFN的隐藏层大小为4096。我们将Infini-attention的段长度N设置为2048,并将输入序列长度设置为32768进行训练。
1M长度的密钥上下文块检索任务:我们在1B LLM中替换了标准的多头注意力(MHA)为Infini-attention,并在长度为4K的输入上继续进行预训练。模型在批大小为64的情况下训练了30K步骤,然后在密钥检索任务上进行微调。
500K长度的书籍摘要任务:我们通过在长度为8K的输入上连续预训练8B LLM模型30K步骤,进一步扩展了我们的方法。然后我们在书籍摘要任务BookSum上进行微调,该任务的目标是生成整本书文本的摘要。
2. 结果分析
在长上下文语言建模任务中,我们的Infini-Transformer在保持比记忆Transformer模型少114倍的内存参数的同时,超越了Transformer-XL和记忆Transformer的基线模型。
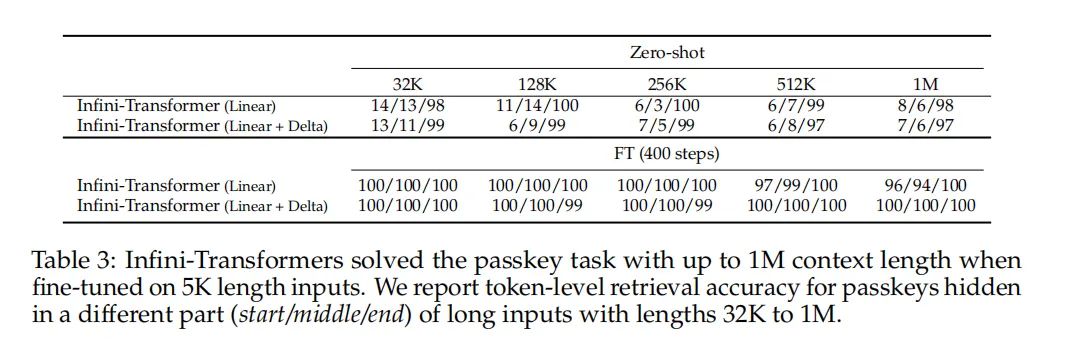
在1M长度的密钥上下文块检索任务中,经过Infini-attention改进的1B LLM在仅在5K长度输入上微调后,成功解决了1M长度的问题。
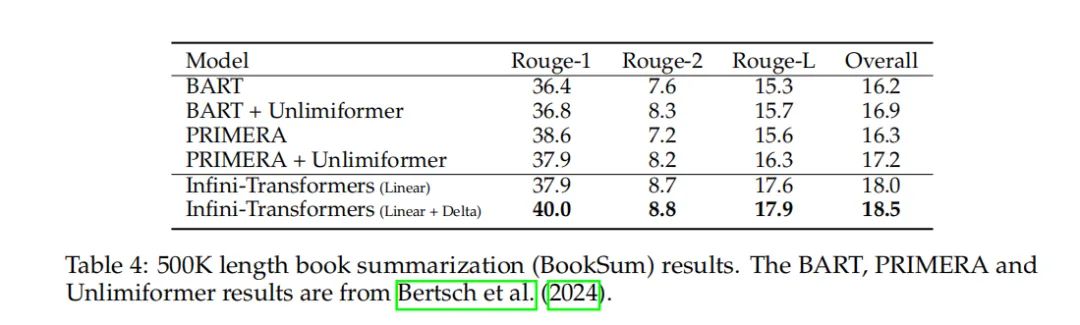
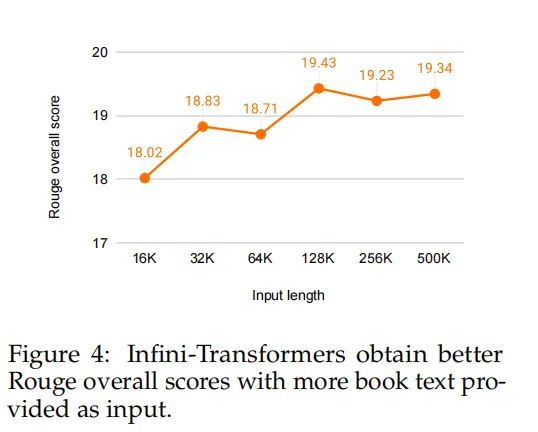
对于500K长度的书籍摘要任务,经Infini-attention改进的8B模型在连续预训练和任务微调后,在500K长度的书籍摘要任务上达到了新的最佳状态。
这些实验结果不仅证明了Infini-attention在处理极长输入序列方面的有效性,而且展示了其在内存和计算资源有限的情况下,如何通过压缩记忆技术实现高效的长序列处理能力。
Infini-attention的实际应用
Infini-attention通过在单个Transformer块中结合压缩记忆、局部遮蔽注意力和长期线性注意力机制,为处理无限长输入提供了一种高效的解决方案。这种创新的注意力机制不仅在理论上具有吸引力,而且在实际应用中展现出了巨大的潜力。
1. 长上下文语言建模
Infini-attention使得模型能够在极长的文本序列上进行语言建模,这对于理解和生成长篇文章、书籍或其他长文本内容至关重要。通过有效地管理内存和计算资源,Infini-attention使得长上下文语言建模成为可能,从而推动了自然语言处理技术的进步。
2. 密钥上下文块检索
在安全和信息检索领域,Infini-attention展现了处理和检索大量文本中特定信息的能力。例如,在1M长度的密钥上下文块检索任务中,Infini-attention能够有效地从大量干扰文本中检索和恢复隐藏的密钥信息,这对于提高信息检索的准确性和效率具有重要意义。
3. 书籍摘要生成
在内容创作和知识管理领域,Infini-attention的应用为自动文本摘要提供了新的可能性。通过处理和理解长达500K的书籍文本,Infini-attention能够生成准确、连贯的书籍摘要,这对于快速获取大量文本信息的核心要点具有重要价值。
总之,Infini-attention的实际应用范围广泛,从长上下文语言建模到信息检索,再到文本摘要生成,都展现了其在处理极长输入序列方面的强大能力和潜在价值。
讨论与未来展望
在未来的展望中,Infini-attention机制提出的解决方案有望在众多领域中发挥重要作用。我们的工作证明了,通过融合压缩记忆体系,Transformer模型可以有效处理无限长的输入,而仅仅需要有限的记忆和计算资源。这一技术突破不仅有助于提高长文本处理的效率,也为未来的各种应用,如文档检索、摘要生成、对话系统等,提供了新的可能性。
1. 扩展应用领域
Infini-attention的提出,可望在处理大规模数据集、进行深度学习训练以及实时数据流处理等方面带来革命性的改进。特别是,在自然语言处理领域,模型对长篇文本的理解能力将得到极大增强,这将推动自动摘要、问答系统和机器翻译等技术的发展。
2. 模型优化与迭代
尽管Infini-attention已经在实验中显示出其优越性,但仍有进一步优化的空间。例如,在模型训练和推理速度方面,有可能通过算法优化或硬件加速来实现效率的进一步提升。此外,模型的参数调优、记忆压缩机制的改良以及对不同类型数据的适应性等方面,都是未来研究的重要方向。
3. 长期记忆与连续学习
Infini-attention模型的长期记忆能力,为持续学习和知识积累提供了新的途径。未来的研究可以探索如何更有效地利用这种记忆能力,以实现更复杂的推理和决策。此外,模型如何在不断变化的环境中适应新信息,同时保持对历史信息的记忆,也是一个值得深入研究的话题。
4. 处理能力与资源限制
虽然Infini-attention能够在有限资源下处理无限长的文本,但在实际应用中,如何在硬件资源受限的情况下平衡处理能力与计算效率,依然是一个挑战。研究者需要考虑到成本效益,并寻求新的方法来优化记忆资源的使用。
5. 理论与实践的结合
Infini-attention的理论研究为长文本处理提供了新的视角。不过,将理论转化为实际应用,需要考虑到更多实际操作中的变量和限制。因此,未来的工作需要在理论研究和实践应用之间架起桥梁,确保新技术能够在真实世界中得到高效、稳定的应用。
综上所述,Infini-attention为处理长序列数据提供了一个高效的框架,其未来潜力巨大,可预期的是,随着技术的不断成熟和优化,它将极大地推动语言模型及相关领域的发展。
总结
本文介绍了一种新颖的Infini-attention技术,通过在标准Transformer模型中引入压缩记忆机制,实现了对无限长输入的有效处理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











