










获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读
论文标题:LLM-Generated Natural Language Meets Scaling Laws: New Explorations and Data Augmentation Methods
机构:
- School of Information Resource Management, Renmin University of China
- School of Computing, National University of Singapore
论文链接:https://arxiv.org/pdf/2407.00322.pdf
在人工智能领域,大型语言模型(LLM)如GPT-4的出现引起了广泛关注,特别是它们在自然语言处理(NLP)中的应用。这些模型通过生成与人类自然语言(HNL)极为相似的文本,推动了NLP的发展。然而,尽管LLM在文本生成方面表现出色,它们在生成人类自然语言的准确性和深度上仍存在疑问。
这篇论文主要探讨了大语言模型(LLM)生成的自然语言与人类自然语言(HNL)之间的对齐问题和数据增强方法。作者提出了一种新的数据增强方法ZGPTDA,利用基于缩放定律的模糊计算机制来提高文本分类的效果。通过大量的实验验证,该方法在性能上优于现有的方法。此外,论文还揭示了一些有趣的见解,如Hilberg's law和Taylor's law可以为文本分类带来更多好处等。
LLM与HNL的基本对比
1. 训练和反馈机制的差异
LLM通常通过从人类反馈中学习的强化学习进行训练,这种方法预设生成的文本与HNL一致。然而,这一假设的实证真实性尚未得到充分探索。与之相对,HNL是通过日常交流和长期的语言习得过程形成的,这一过程涉及复杂的认知和社会互动因素,这些是LLM难以完全模拟的。
2. 语言的复杂性和深度
从语言的复杂性来看,HNL具有丰富的变化和深度,这反映在不同语境下语言的灵活运用上。相比之下,尽管LLM能够生成语法结构正确的文本,但它们生成的内容往往缺乏人类语言的微妙情感和语境深度。例如,LLM在处理具有双关语或幽默等元素的文本时,可能无法完全捕捉其语言的微妙之处。
3. 数据增强与真实性问题
在使用LLM进行数据增强时,一个关键问题是生成的文本数据(Daug)与人类语言的一致性。研究表明,尽管通过LLM生成的文本可以扩展训练数据集,但这些文本的质量和多样性之间的权衡可能会影响模型的最终性能。此外,由于缺乏策略性过滤,可能会包含一些低质量或与人类语言差异较大的数据,这一点在训练过程中需要特别注意。
通过对LLM和HNL的这些基本对比,我们可以看到尽管LLM在模拟人类语言方面取得了一定的成就,但在真实性、复杂性和深度上仍有较大的提升空间。这些差异提示我们在将LLM应用于实际NLP任务时,需要仔细考虑其局限性,并探索更有效的方法来提高其与人类语言的一致性。
新的数据增强方法:ZGPTDA
在自然语言处理(NLP)领域,大型语言模型(LLM)如GPT-4的出现,已经显著推动了文本生成技术的发展。然而,这些模型生成的文本(LLMNL)与人类自然语言(HNL)的一致性仍是一个未解之谜。为了解决这一问题,本文提出了一种新的文本数据增强方法,名为ZGPTDA(基于缩放法则的GPT数据增强方法)。
1. ZGPTDA的动机和目标
ZGPTDA的核心动机是解决LLM生成的文本随机性问题,即不是所有生成的文本都对训练有同等的价值。这种方法特别关注那些更接近人类语言的文本,因为分类器的设计初衷是服务于人类,并在现实生活中使用。因此,ZGPTDA通过评估这些文本与八个缩放法则的符合度来确定其适用性,如拟合优度(goodness of fit)等,从而选择出最佳的增强实例。
2. ZGPTDA的实现机制
ZGPTDA首先使用GPT-4从原始数据集生成额外的训练文本。然后,这些生成的文本将根据它们与已知的缩放法则(如Zipf定律、Heaps定律等)的一致性来评估。通过这种方式,ZGPTDA能够量化每个文本实例的“适用性”。具有较高适用性的实例被认为更具代表性,更符合人类语言的特性,因此更适合被纳入训练过程中。


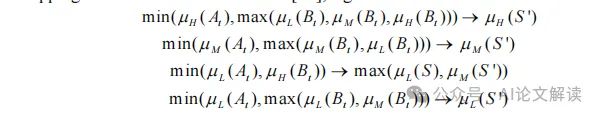
3. ZGPTDA的评估和效果
通过对比实验,ZGPTDA在多个数据集上的应用显示出了其有效性。例如,在使用Bert和RoBerta分类器的测试中,ZGPTDA能够提高7-10%的F1得分,并且在一些情况下超过了最近的AugGPT方法。这些结果验证了ZGPTDA在处理由LLM生成的文本时,通过缩放法则进行筛选和决策的有效性。
总之,ZGPTDA提供了一种新的视角和方法,用于改进基于LLM的文本数据增强技术,特别是在训练数据不足的情况下。通过精确地评估生成文本的人类语言适用性,ZGPTDA有助于提高NLP模型的性能和适用性。
实验设置与验证
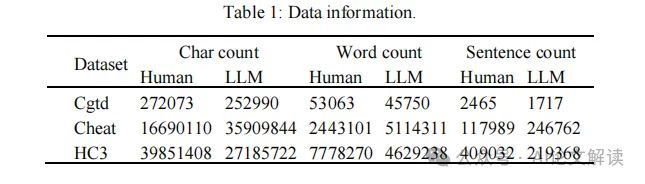
在本研究中,我们采用了三个数据集,每个数据集都包含由GPT-3.5和人类在相同提示下生成的文本。为了更好地进行实验,我们将每个数据集中的LLM生成的自然语言(LLMNL)和人类自然语言(HNL)分别整合。表1展示了一些统计信息,包括文本数量和词频等。
为了验证LLM生成的文本与人类文本的一致性,我们采用了多种统计法则进行量化分析。这些包括Zipf定律、Heaps定律、Taylor定律等,通过这些定律的参数优化和回归分析来确定它们的适用性。我们使用R2、Kullback-Leibler散度(KL)、Jensen-Shannon散度(JS)和平均绝对百分比误差(MAPE)等多种指标来衡量拟合的好坏。其中,R2值大于0.9通常表示很强的一致性。
实验结果显示,在三个数据集上,所有的R2值均高于0.9,甚至在Heaps定律和Mandelbrot定律上超过了0.99。此外,KL和JS散度的最小值(例如在Mandelbrot定律中低至0.001)也强有力地支持了LLM生成的语言与真实分布之间的一致性。这些结果充分证明了LLM在语言输出上与人类语言的高度一致性。
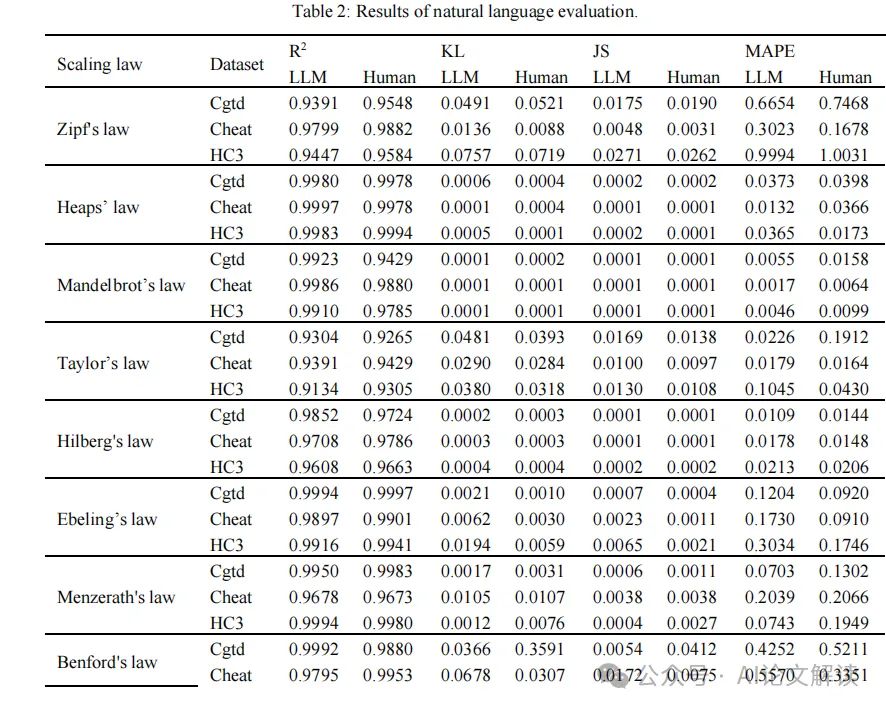
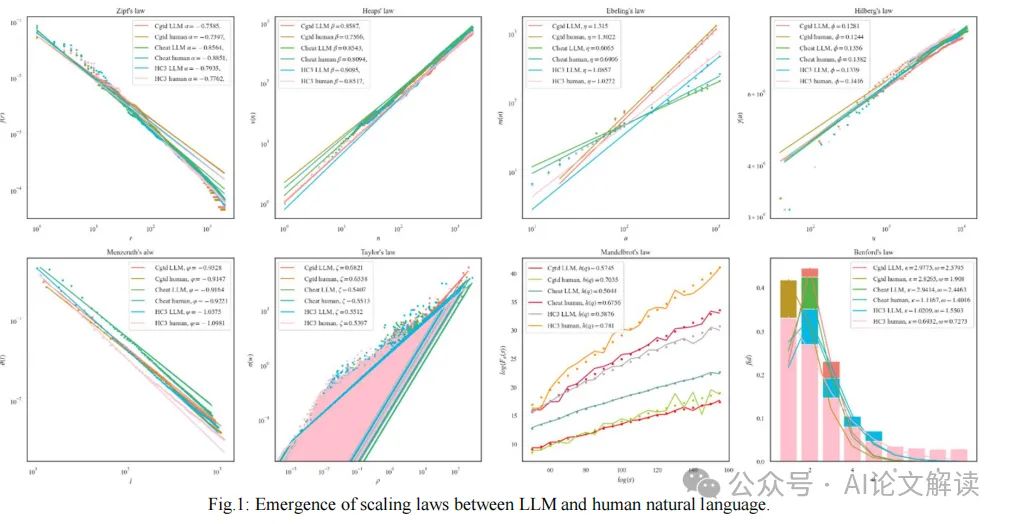
图1清晰地展示了LLM和人类语言输出中出现的定律的一致性,显示出在不同数据集上的统一趋势。例如,在HC3数据集上,Zipf指数α的差异被限制在0.03以下,显示出对最小努力原则近乎等同。
通过这些严格的实验设置和验证,我们不仅证实了LLM生成的文本在结构和统计特性上与人类文本的高度相似,而且还为使用LLM进行文本数据增强提供了坚实的理论基础和实践证据。这些发现为自然语言处理的进一步研究和应用提供了重要的支持。
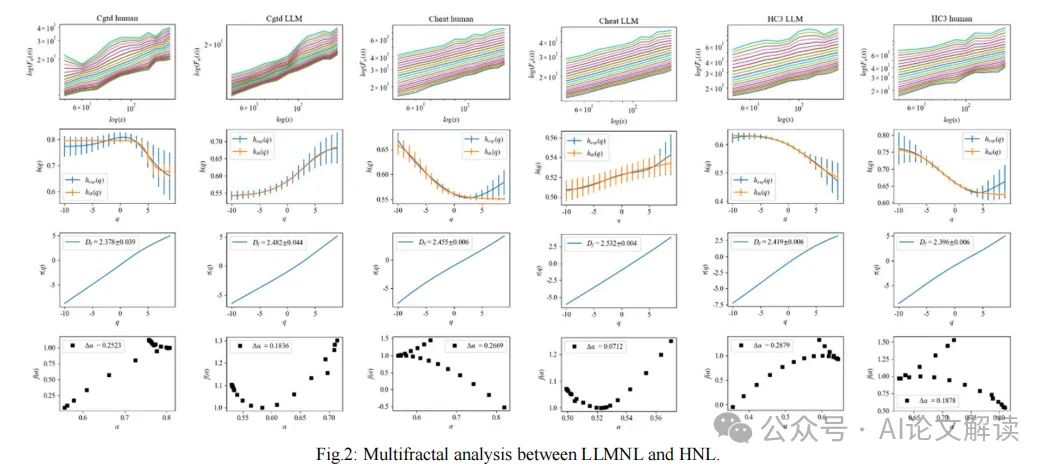
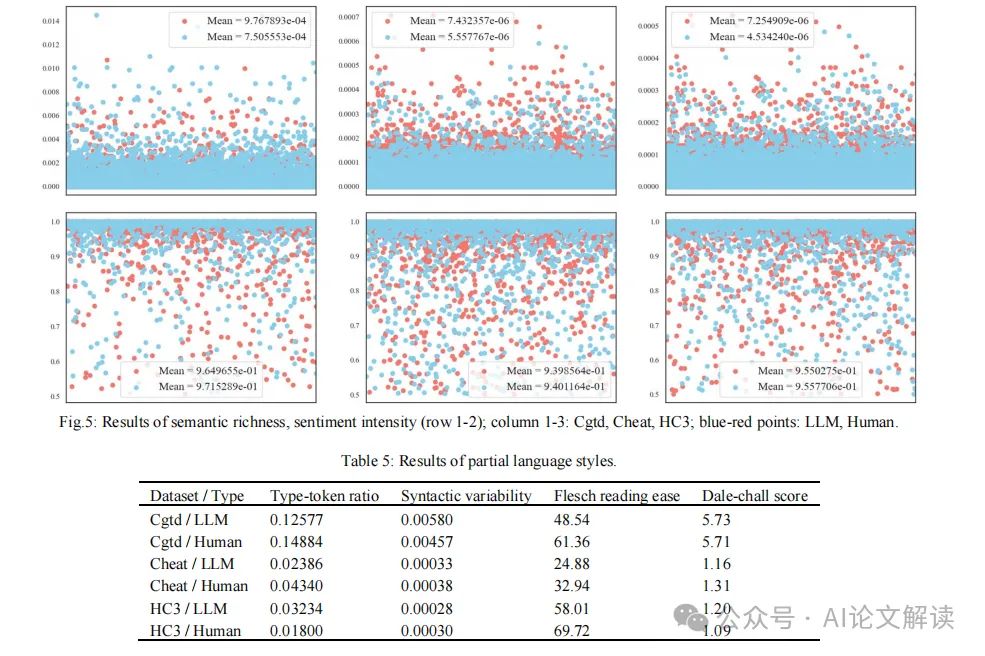
深入分析与讨论
在探索大型语言模型(LLM)如GPT-4在自然语言处理(NLP)中的应用时,一个核心问题是这些模型生成的语言(LLMNL)与人类自然语言(HNL)的真实对应程度。尽管LLM通过从人类反馈中学习而设计,理论上应该能够模拟人类语言,但实际上这一假设的经验验证仍然是一个未知数。这种不确定性使得我们必须更加深入地研究LLM生成语言的真实性和适用性。
1. 语言生成与理解的差异
LLM如GPT-4在生成语言方面的能力无疑是革命性的,但它们在理解语言的能力上却有所不足。这种生成与理解的差异在特定领域尤为明显,例如在工业安全领域,由于缺乏特定领域的训练数据,LLM在进行危害分类等任务时可能效果不佳。
2. 数据增强的实际应用
在标签数据稀缺的情况下,使用LLM生成的标签文本来增强原始训练数据集大小是一种直接有效的策略。这种方法可以在保证生成数据标签的正确性(保真度)和生成数据的多样性(多样性)之间进行权衡。然而,这种方法也存在生成文本的随机性和可能包含低质量数据的问题,这些低质量数据可能会被错误地包含在训练集中。
3. 缩放法则的应用
通过引入缩放法则,如Zipf定律、Heaps定律和Mandelbrot法则等,我们可以从一个新的角度来评估LLMNL与HNL之间的相似性和差异。这些法则帮助我们从统计物理的角度理解语言的复杂性,提供了一种量化语言本质的方法。例如,Zipf定律揭示了词频分布的偏斜性,这可以被视为语言经济性的体现,而Mandelbrot法则则从多重分形分析的角度提供了对语言自相似性的深入理解。
4. ZGPTDA方法的创新
在数据增强方面,我们提出了一种新的方法ZGPTDA,它基于LLM生成文本与缩放法则的符合度来评估这些文本的适用性。这种方法不仅考虑了生成文本的质量,还通过决策过程来选择最适合训练目的的文本实例。ZGPTDA通过实验显示,能够有效提高文本分类的F1分数,并且在多个数据集上的表现优于现有的数据增强方法。
通过这些深入的分析和讨论,我们不仅加深了对LLM在自然语言处理中应用的理解,还推动了相关技术的进一步发展和优化。这些研究成果为LLM在NLP领域的应用提供了理论基础和实践指导,为未来的研究方向指明了道路。
总结与未来展望
在本文中,我们探讨了大型语言模型(LLM)生成的自然语言(LLMNL)与人类自然语言(HNL)之间的关系,并引入了缩放法则来深入分析这两者之间的相似性和差异。通过广泛的实验,我们发现LLMNL与HNL之间存在微小的偏差,特别是在Mandelbrot的法则中观察到约0.2的指数差异。这一发现不仅加深了我们对语言风格的理解,还为LLM的进一步应用和发展奠定了坚实的基础。
此外,我们提出了一种新的文本分类数据增强方法——ZGPTDA,该方法利用缩放法则的一致性通过模糊计算机制对GPT-4增强数据进行决策。实际应用场景中的广泛实验验证了ZGPTDA的有效性和竞争力,其在Bert和RoBerta上的F1得分提高了7-10%,并在DeBerta上的准确率上超过了最近的AugGPT和GENCO方法约2%。
我们的研究还揭示了一些有趣的见解,例如Hilberg法则和Taylor法则在文本分类中可能带来更多的好处。这些发现为未来的研究提供了新的方向,例如在特征工程中优先考虑这些法则,以提高效率和完善自然语言处理的范式。




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











