







Google 的 BERT 模型一经发布便点燃了 NLP 各界的欢腾,Google Brain 的资深研究科学家 Thang Luong 曾给出其“开启了 NLP 新时代”的高度定义,国内外许多公司及开发者对其进行了研究及应用,本文作者及其团队对 BERT 进行了应用探索。
随着 Google 推出的 BERT 模型在多种 NLP 任务上取得 SOTA,NLP 技术真正进入了大规模应用阶段,由此,我们展开了对 BERT 的探索。
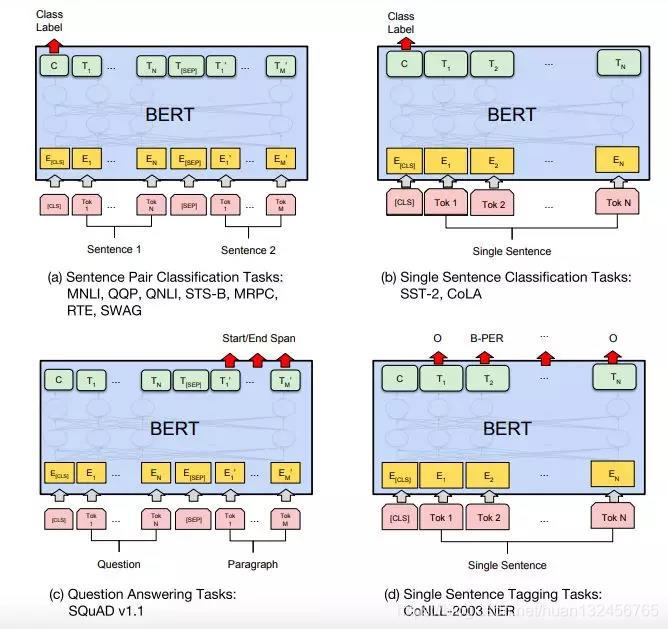
训练模型
训练数据
训练其他模型时我们已经标注了大量的训练数据,主要把相似句对分为三类来标注:
不相似(0)、相关(0.5)、相似(1)
所以,训练 BERT 模型时就可以“拿来主义”了。
模型修改
我们的主要应用点是相似度计算,期望模型返回的结果是一个概率(分值)而不是每个类别的概率。当然如果模型给的结果是每一个类别的概率,依然可以通过加权求和输出一个分值,但这样是不是又复杂了。
所以我们在官方代码上做了点小的修改(将最后的 softmax 改为了 sigmoid)使得模型输出是一个分值,这个分值也就是我们要的相似度了。
模型训练
我们使用之前标注的数据集在 GeForce GTX 1070 上训练(Fine-Tune),大概训练了 8 个小时左右。
模型导出
模型训练完会产生几个 Checkpoint,这些 Checkpoint 是不能直接在工程中使用的,需要导出成 PB 文件,可以使用 Estimator 的 export_savedmodel 方法导出。
模型使用
通过调研,主要有两种方式:
Java JNI:基于我们的 GPU 编译[1]一个合适的 libtensorflow 和libtensorflow_jni_gpu(如果你的配置和官方一致就不需要自己编译 了,自己编译太多坑,这里有一份经过验证的编译环境配置[2])打成 jar 包并加入到工程依赖,使用 TensorFlow 提供的 Java API 加载 BERT 模型,在你的 Java 工程中使用[3]。
Docker + Nvidia-docker + Tensorflow Serving:需要一个合适的 Tensorlfow Serving 的 image,这里有一份官方做好的 image 列表[4],当然你也可以自己做一个。
这两种方式各有优缺点,我们主要考虑以下几个方面:
性能:我们对两种方案做了实验,Tensorflow Serving 是 C++ 写成的服务,对于 batch 做过优化[6],性能优于 Java JNI。
多模型支持能力:方案 2 是支持多模型的,也就是多个模型共用一个 GPU,方案 1 不支持。
简单好部署:两种方案都不复杂。
与现有服务开发和运维体系兼容性:方案 1 更有优势。
另外,方案 2 不仅支持多模型还支持多版本、模型的冷启动和热加载。综合考虑下,我们使用了方案 2 进行模型部署。
效果对比
我们用一些典型客户的数据构建了测试环境,抽取这些客户的真实访客数据,对现有模型和 BERT 模型做了对比实验,BERT 模型的效果相比于对照模型提高了超过 10%。
调用图
这是我们的调用时序图:
FAQ 服务->相似度计算服务:句子 1 和 句子 2 相似度是多少 ?
相似度计算服务->TensorflowServing: 句子 1 和 句子 2 相似度是多少 ?
Note right of TensorflowServing: bert 模型预测
TensorflowServing->相似度计算服务: 句子 1 和 句子 2 相似度是 xx
相似度计算服务->FAQ 服务: 句子 1 和 句子 2 相似度是 xx
这里抽象出一个相似度计算服务,是因为我们集成了多种相似度计算方法。
优化
后处理
这种模型的一个主要问题是:模型并不能完美解决所有问题,时不时总会有 bad case 出现。一旦模型上线,如果有问题我们无法及时解决(训练模型和上线都会消耗大量时间)。为此我们增加了后处理,以便于我们的训练师能够及时干预,解决问题。
预训练
BERT 预训练的模型使用的数据来源于维基百科,与我们的主要应用场景不一致。我们可以猜想如果在 BERT 原有 Pre-Training 模型的基础上,使用客服里的数据再次进行 Pre-Training 应该会更好,事实上我们也的确这样做了。结论是影响不大,可能是数据不够多,新的训练实验还在进行中。
数据标注
GPT 2.0 的出现再次证明了要想得到好的模型,不仅要有数据量,还要提高数据的品质。我们新的标注也在进行中,相信会对模型效果有所提高。
其他应用
我们在产品中还提供了意图识别的服务,意图识别服务要求必须能够在线训练。如果直接使用 BERT 来做意图识别,很难满足在线训练的要求(BERT 训练太慢了)。为此我们使用了简单的模型来支持在线训练,并把 Fine-tune 模型的倒数第二层作为特征,增强意图识别的效果。
BERT 的近邻
最近 Google 又携 XLnet 屠榜了,从实验效果看对比 BERT 确实有比较大的提升,我们也在关注中,实验的小手已经蠢蠢欲动了。如果在我们的场景实验效果好的话,相信我们的客户很快会便会体验到。
[1]: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/java/README.md
[2]: https://www.tensorflow.org/install/source#tested_build_configurations
[3]: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/java/README.md
[4]: https://hub.docker.com/r/tensorflow/serving/tags
[5]:https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/building_with_docker.md
[6]: https://github.com/tensorflow/serving/tree/master/tensorflow_serving/batching
[7]: https://www.tensorflow.org/tfx/serving/serving_config
[8]: https://arxiv.org/abs/1906.08237
作者简介:董文涛,环信人工智能研发中心算法工程师,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
参考文档:
注册环信IM:https://console.easemob.com/user/register
环信官方Demo下载:https://www.easemob.com/download/demo
IMGeek社区支持:https://www.imgeek.net/















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









