







 本文介绍如何使用IntelliJ IDEA和Maven构建Spark单词计数应用,并详细说明了配置过程及代码实现,最后演示了如何打包并运行jar包。
本文介绍如何使用IntelliJ IDEA和Maven构建Spark单词计数应用,并详细说明了配置过程及代码实现,最后演示了如何打包并运行jar包。
环境介绍:IntelliJ IDEA开发软件,hadoop01-hadoop04的集群(如果不进行spark集群测试可不安装),其中spark安装目录为/opt/moudles/spark-1.6.1/
准备工作
首先在集群中的hdfs中添加a.txt文件,将来需在项目中进行单词统计

构建Maven项目
点击File->New->Project…
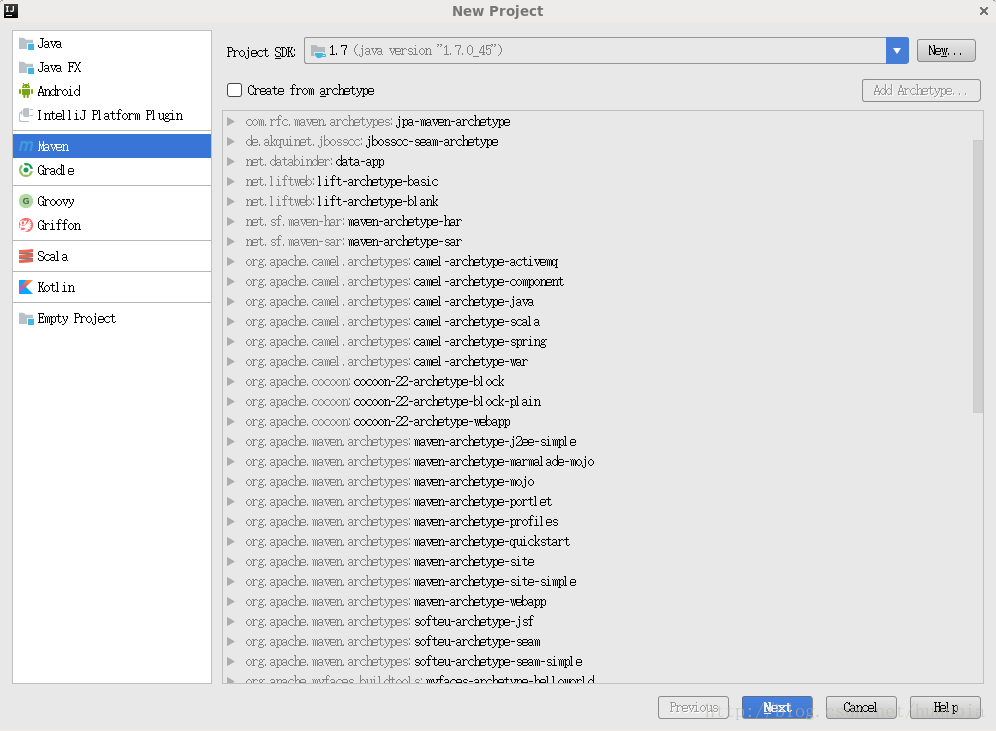
点击Next,其中GroupId和ArtifactId可随意命名
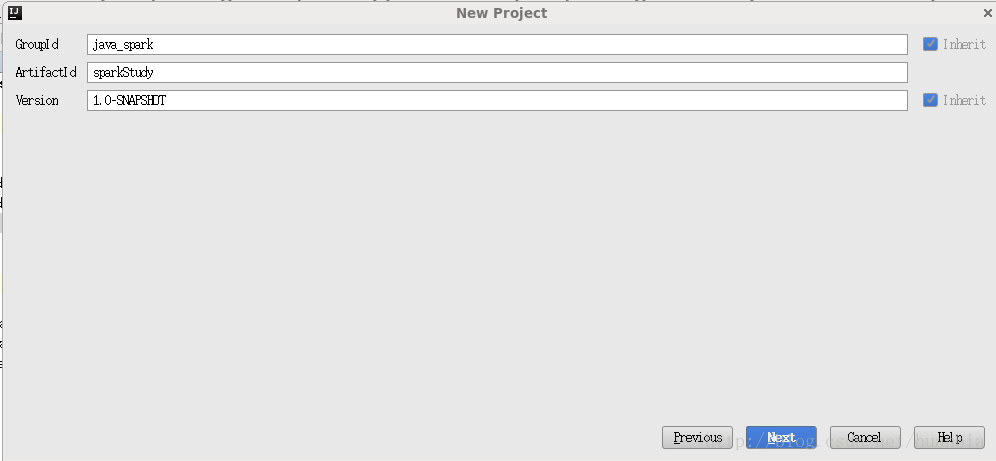
点击Next
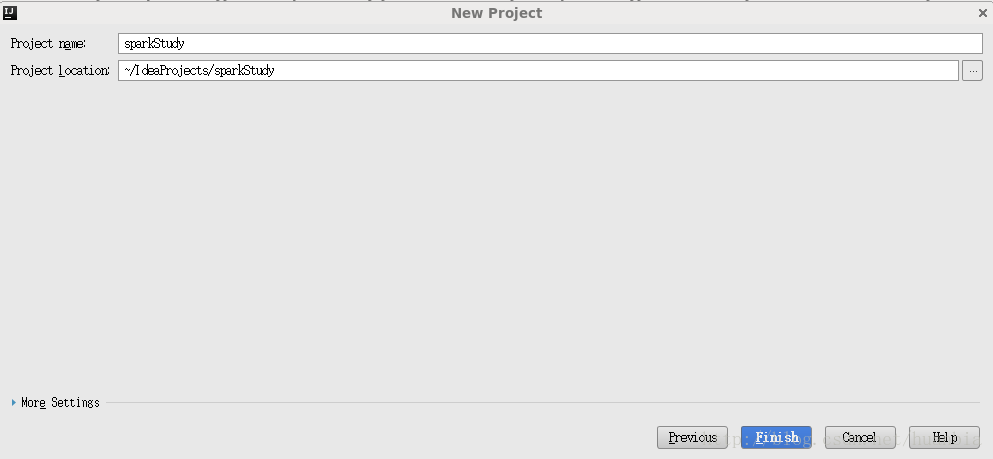
点击Finish,出现如下界面:

书写wordCount代码
请在pom.xml中的version标签后追加如下配置
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2-beta-5</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<maniClass></maniClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.3.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>false</includeProjectDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.dt.spark.SparkApps.App</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>点击右下角的Import Changes导入相应的包
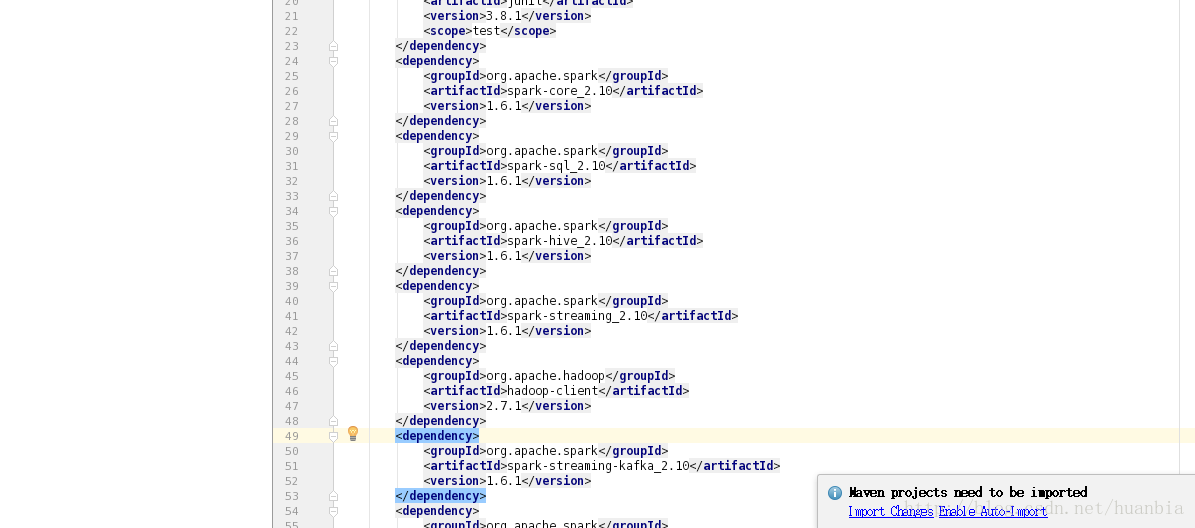
点击File->Project Structure…->Moudules,将src和main都选为Sources文件
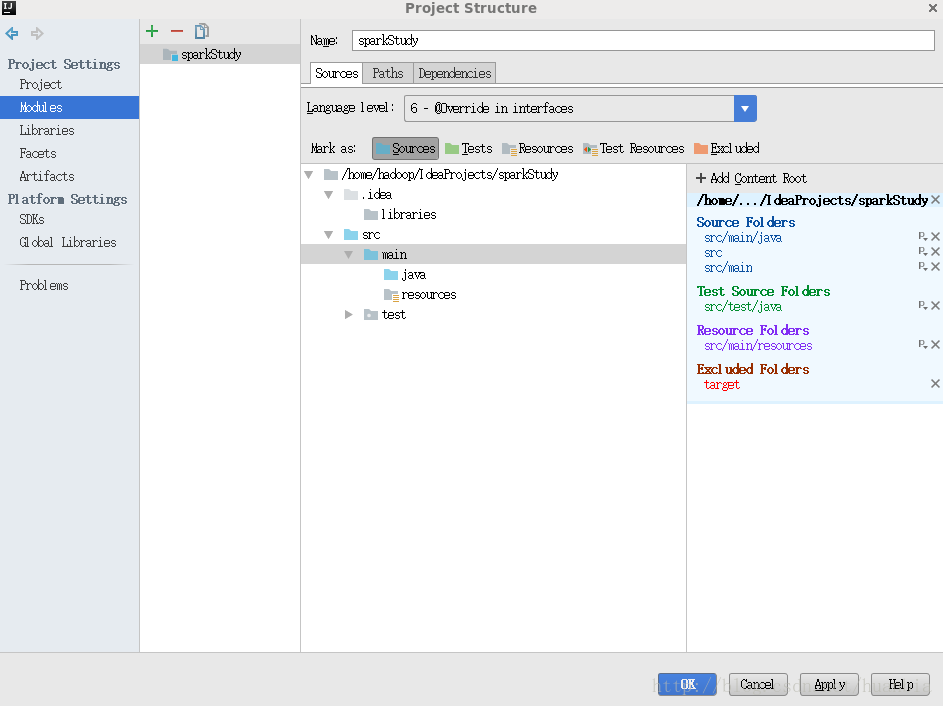
在java文件夹下创建SparkWordCount java文件
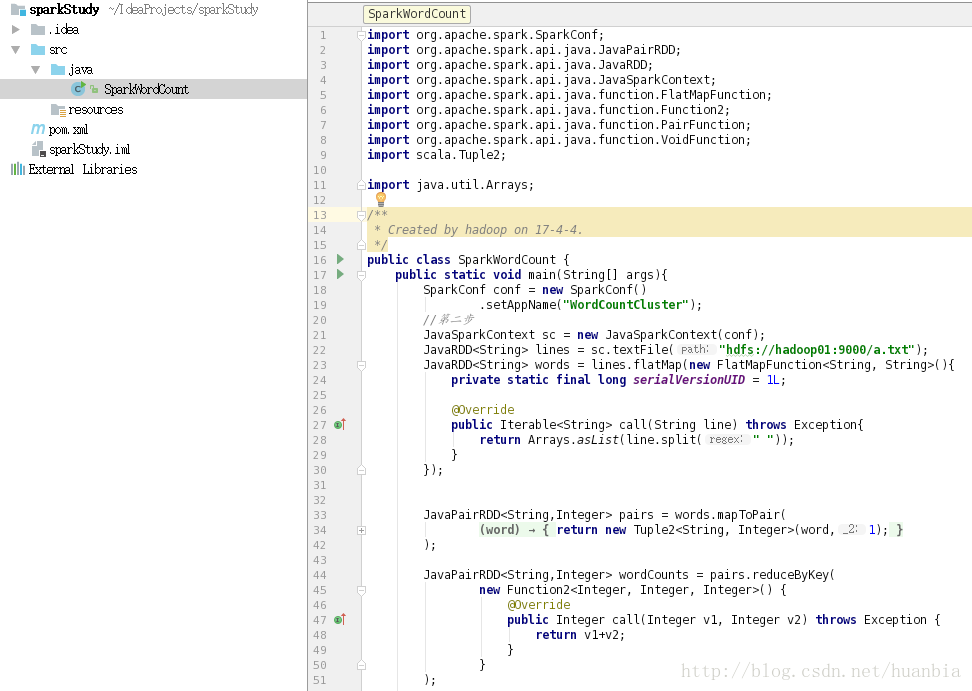
该文件代码为:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by hadoop on 17-4-4.
*/
public class SparkWordCount {
public static void main(String[] args){
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
//第二步
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://hadoop01:9000/a.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String,Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}
);
JavaPairRDD<String,Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1+" : "+ wordCount._2 );
}
});
sc.close();
}
}生成jar包
点击File->Project Structure…->Artifacts,点击+号
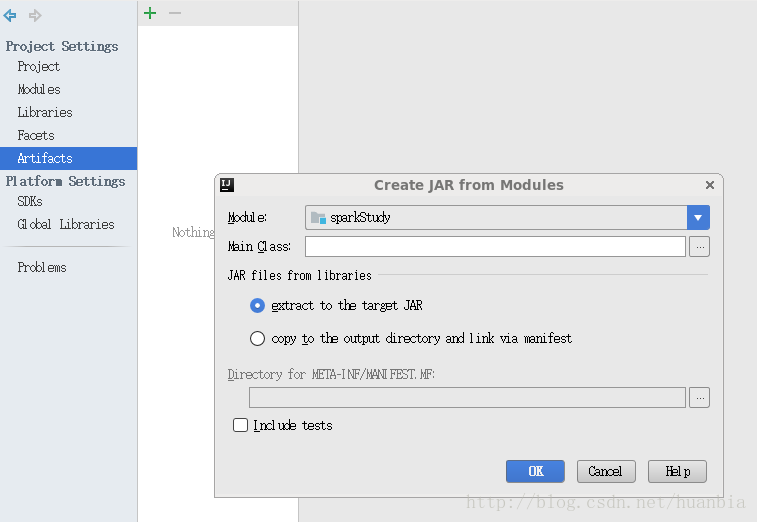
选择Main Class
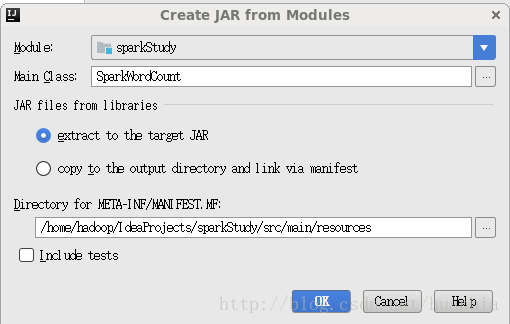
点击ok
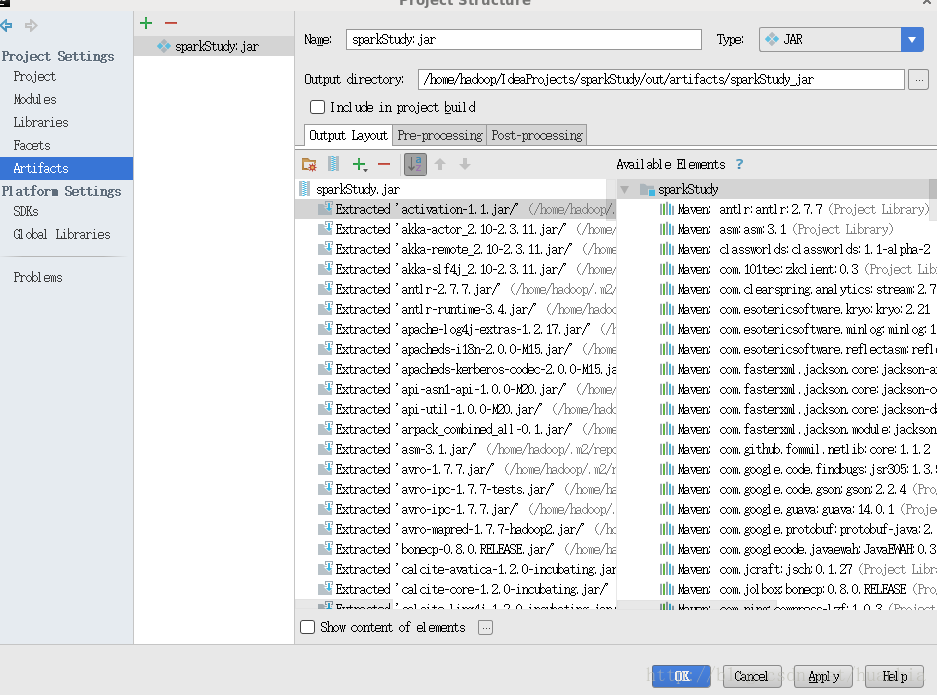
由于集群中已包含spark相关jar包,将那些依赖jar包删除

点击apply,ok。然后点击菜单栏中的Build->Build Artifacts…->Build,将会在out目录中生成相应的jar包
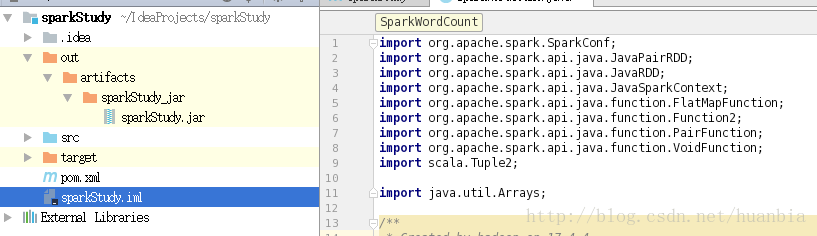
jar包上传到集群并执行
本文使用scp将jar包上传到集群,如果在windows下可使用filezilla或xftp软件来上传

在集群上输入如下命令来执行:
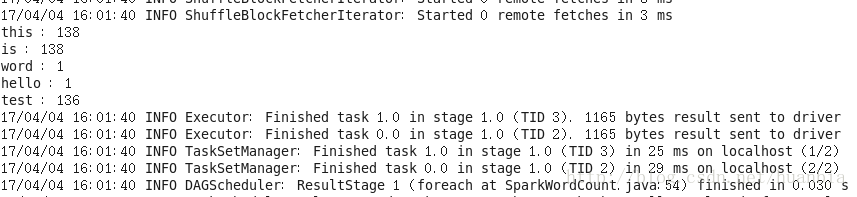
/opt/moudles/spark-1.6.1/bin/spark-submit --class SparkWordCount sparkStudy.jar --master=spark://192.168.20.171:7077最终结果为:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









