







本文重点
前面我们学习了逻辑回归算法,本文我们基于sklearn完成逻辑回归算法的构造,因为逻辑回归算法可以解决分类问题,所以本文我们使用python代码完成垃圾邮件的分类问题,我们下面来看一下是如何操作的
数据准备
现在有两个文件,一个文件是训练数据(带有标签的),另外一个是测试集数据(没有标签)

我们第一步的任务是将train训练数据分为两个文件,一个文件只存邮件的文本,另外一个文件存储邮件多对应的标签,那么执行下面的任务就可以完成,这个代码就遍历每一个样本,然后将文本放到email.txt中,然后将标签放到labels.txt中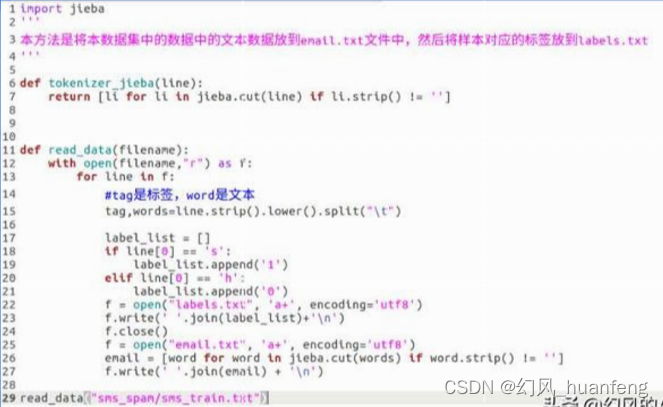
使用随机森林算法需要我们手动构建特征,这里我们使用tf-idf的方式来看一下,我们如何构建样本的特征。这里我们使用tf-idf工具,只需要把数据放入进去就可以自动构建出tf-idf数据了
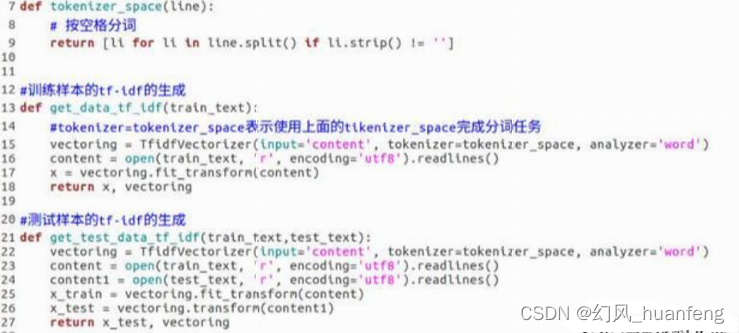
如代码所示,这里我们有两个tf-idf的方法,不同点是一个为了训练集构建,一个为了测试集构建,我们知道训练集和测试集的样本是不一样的,为了让二者统一,我们使用

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











