






什么!一本书的Github仓库居然有18.5k的星标!(这含金量不必多说)
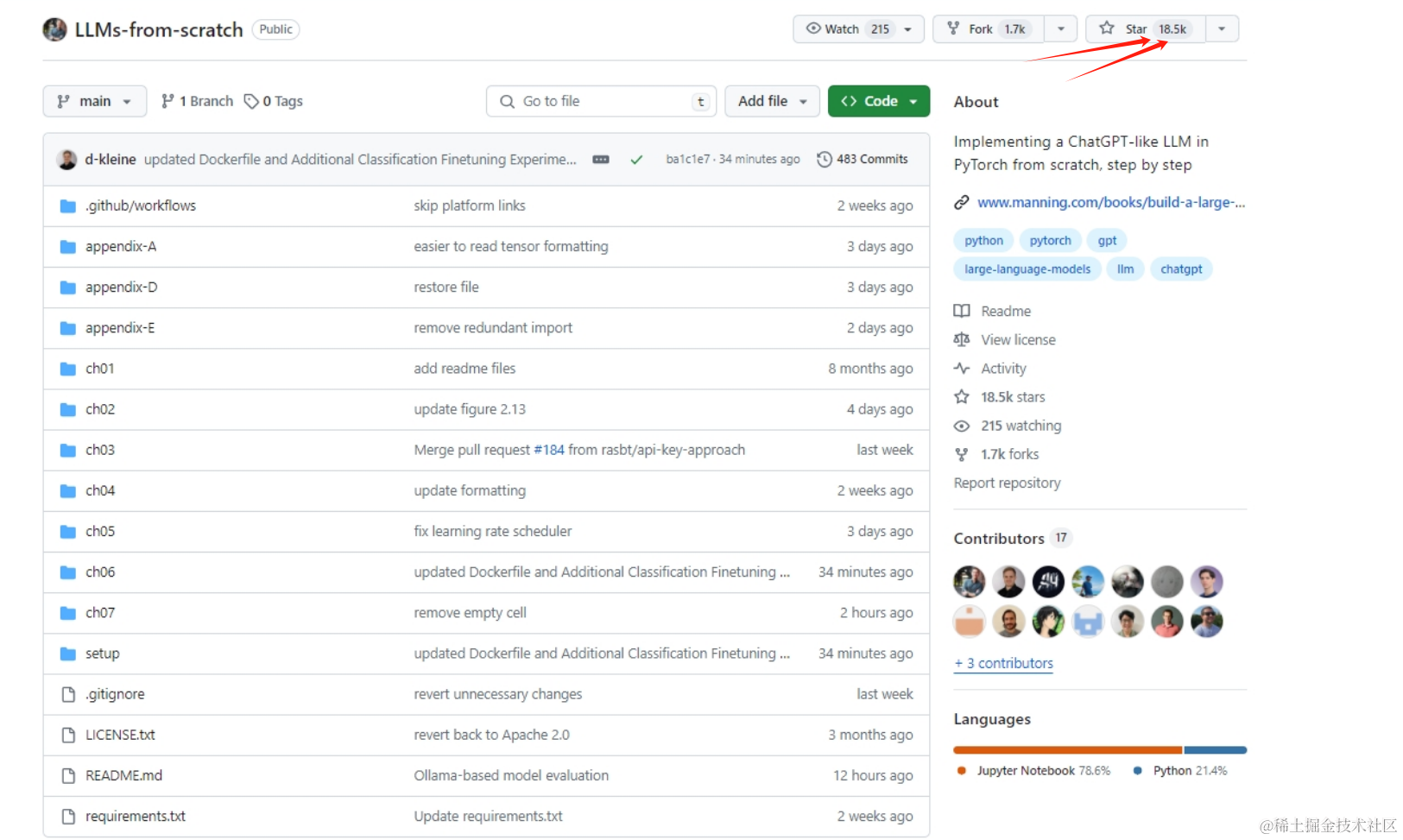
对GPT大模型感兴趣的有福了!这本书的名字叫 《Build a Large Language Model (From Scratch)》 也就是 从零开始构建大语言模型!
虽然这是一本英文书、而且还没正式出版,但是他真的可以帮你使用python从零构建一个自己的大模型!

为了加强读者的动手能力,这本书主要使用的是 pytorch 框架,而不是依靠各种库。通过这种方法,加上大量的图表和插图让大家可以彻底了解llm的工作原理。
大家了解过llm的应该都知道,大模型就意味着大算力,但是这本书的作者考虑到很多同学算力有限,所以这本书的一切操作都是可以在笔记本上实现的(而且不用花很长时间),不说了1050直接申请出战!!!
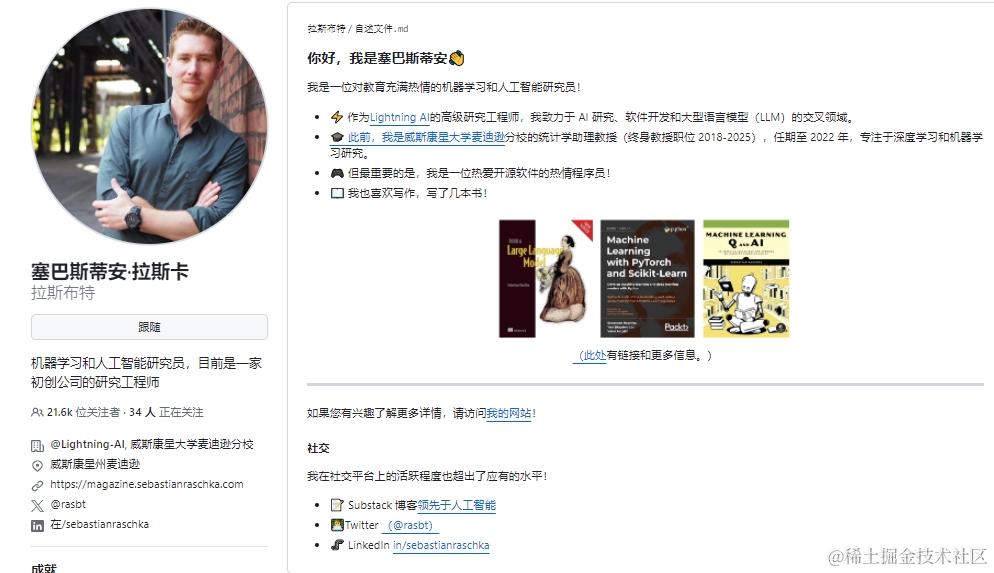
这本书的作者Sebastian是Lightning AI的创始人,之前是威斯康辛大学麦迪逊分校的助理教授
值得一提的是这本机器学习神书也是他写的。
朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

但是这本书的Github仓库里没有PDF,我也是找了很久才找到了PDF版本,大家可以看到现在还是早期版本,模型微调章节还没更新完。
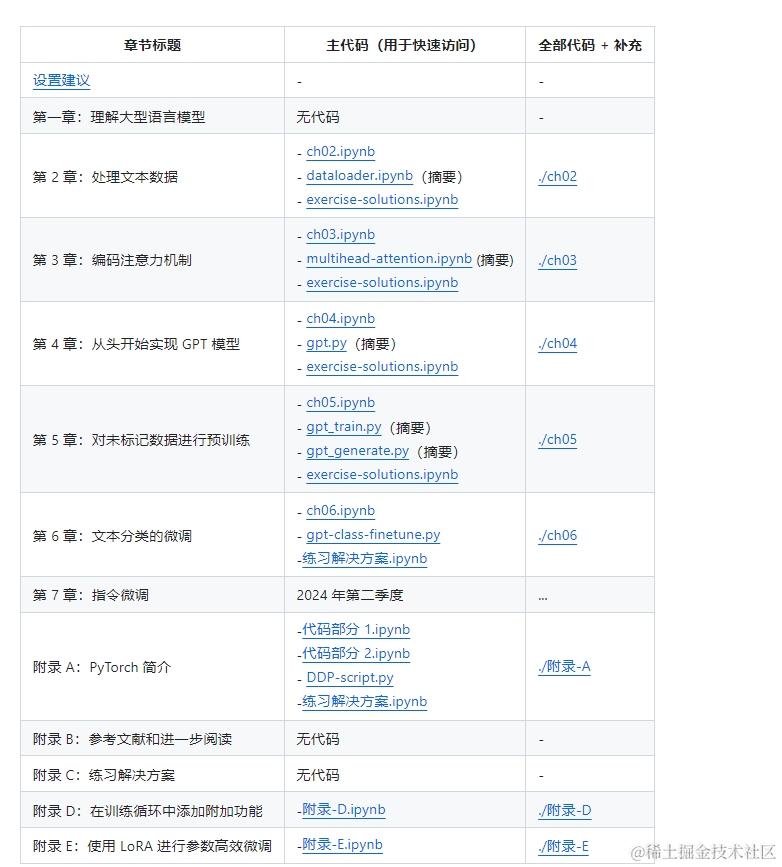
这本书可以分为六个部分
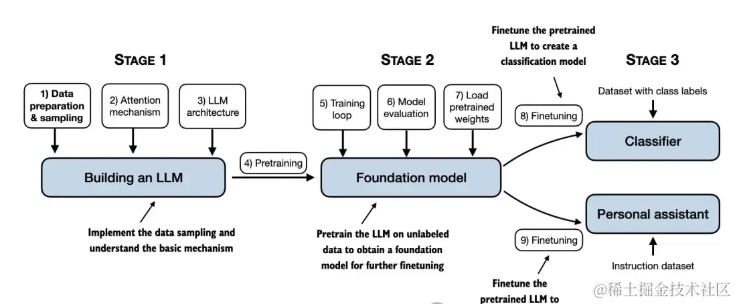
第一部分理解大型语言模型: 介绍了 LLM 的基本概念、transformer架构以及训练大型语言模型所需的基础知识。

第二部分文本数据处理: 详细讲解了如何准备和处理用于训练 LLM 的文本数据。

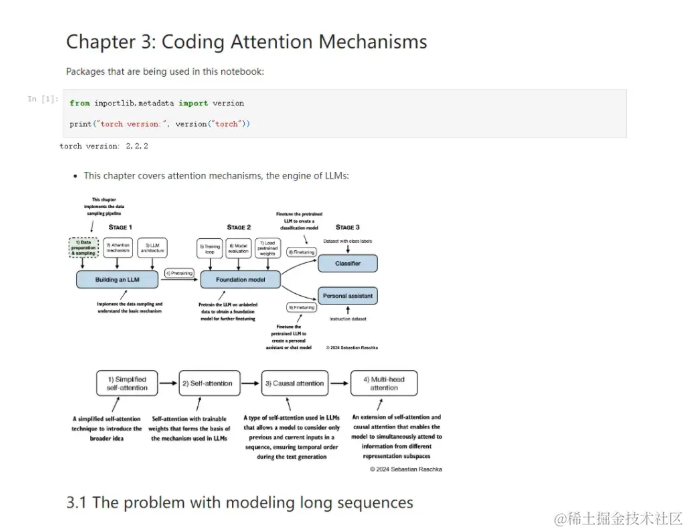
第三部分注意力机制编程: 深入探讨了注意力机制的原理及其在 LLM 中的应用,并通过代码实现了这些机制。

第四部分从零实现 GPT 模型: 通过一步步的指导,读者将学会如何从头开始构建一个 GPT 模型,并用于生成文本。

第五部分无标签数据的预训练: 讨论了如何在没有标签的数据上进行预训练,使模型能够捕捉语言的复杂性和上下文关系。

第六部分模型微调: 解释了如何在特定任务或领域的数据上微调预训练的模型,以提升其在特定应用中的表现。(暂未更新)
通过本书,大家不仅可以掌握 LLM 的理论知识,还能通过动手实践,学习如何从头构建一个功能强大的语言模型。
( 本书在 公主号:【AI智能江河】)
朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









