







Snapshot即是快照,代表某个时刻数据库中表的状态,就像是照片一样,记录了该时刻所有的数据。
HBase可以对某个时刻的表建立snapshot,过后可以恢复到该snapshot的状态,也可以用snapshot建立一个新的表等等。
本文重点在于解释,为什么HBase Snapshot的建立与恢复操作不涉及数据的大量复制,且能在常数时间内完成。
Snapshot的用法
建立snapshot、查看snapshot:
hbase> snapshot 'tableName', 'snapshotName' hbase> list_snapshots SNAPSHOT TABLE + CREATION TIME snapshotName tableName (Sun Mar 13 13:54:32 +0800 2016)
将snapshot复制到一个新表:
hbase> clone_snapshot 'snapshotName', 'newTableName'
删除snapshot
hbase> delete_snapshot 'snapshotName'
用snapshot恢复表:
hbase> restore_snapshot 'snapshotName'
与其它集群的导出或导入:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase \
-chuser MyUser -chgroup MyGroup -chmod 700 -mappers 16
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot -copy-from hdfs://srv2:8082/hbase \
-copy-to hdfs://srv1:50070/hbase \
利用Snapshot只需要常数时间的特性,还可以用来改表名:
hbase> disable 'tableName' hbase> snapshot 'tableName', 'tableSnapshot' hbase> clone_snapshot 'tableSnapshot', 'newTableName' hbase> delete_snapshot 'tableSnapshot' hbase> drop 'tableName'
使用场景
直接摘抄自https://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/,感觉写得很好(主要是我懒得翻译了:P)
- Recovery from user/application errors
- Restore/Recover from a known safe state.
- View previous snapshots and selectively merge the difference into production.
- Save a snapshot right before a major application upgrade or change.
- Auditing and/or reporting on views of data at specific time
- Capture monthly data for compliance purposes.
- Run end-of-day/month/quarter reports.
- Application testing
- Test schema or application changes on data similar to that in production from a snapshot and then throw it away. For example: take a snapshot, create a new table from the snapshot content (schema plus data), and manipulate the new table by changing the schema, adding and removing rows, and so on. (The original table, the snapshot, and the new table remain mutually independent.)
- Offloading of work Take a snapshot, export it to another cluster, and run your MapReduce jobs. Since the export snapshot operates at HDFS level, you don’t slow down your main HBase cluster as much as CopyTable does.
原理解析
Snapshot之所以能在常数时间内完成,是因为它只是一组元数据(MetaData)的集合。Snapshot的操作都不需要复制任何业务数据。
首先我们要理解,HBase的底层存储文件HFile是什么,以及是怎么被生成的、怎么被删除的(或者叫生命周期)。其次就不难理解Snapshot为什么不需要复制业务数据了。
1. HFile是什么
HBase是一个Key-Value数据库,其基本数据操作(如Put、Delete等)最后都化归为Key-Value对,存储在HDFS的一个个文件(HFile)中:
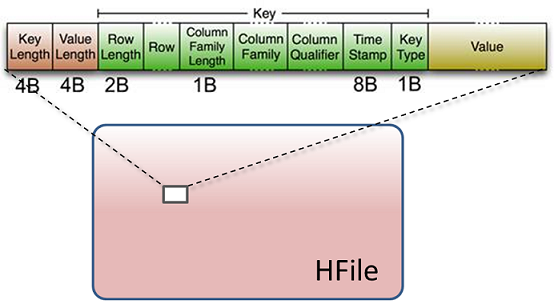
注意上图绿色的Key字段中,最后有个1 Byte的Key Type域,即是用来区分Put和Delete的。
另外更需注意的一点是,HBase的Delete操作并不是立即定位到目标数据将其删除或者做个删除标记,因为HDFS不支持这种随机写。Delete操作也跟Put一样存储,只是Key Type域不一样,以及Value域为空而已。HBase在读取时,会将拥有Delete操作的数据过滤掉。而具体何时删除目标数据,则是在对HFile做Compaction时。
2. HFile的两种生成方式
HFile有两种生成方式,分别是MemStore Flush和Compaction
- MemStore Flush
写操作(Put、Delete等)在WAL(Write-Ahead Log)提交成功后,马上会写入对应Region Server的内存缓冲区(MemStore)中。在MemStore里这些操作是按key排好序的。当MemStore写满时,就会将这些数据写入到HDFS中成为一个HFile。 - Compaction
HFile内部的数据是按key排好序的,但HFile之间的数据并不能保证key的顺序,也就是说,对于新生成的HFile,其里面的key值并不都比老的HFile的大。因此每次检索时,都需要在所有HFile中检索一次,再将结果合并。虽然HBase针对这个设计了各种加速机制(如Bloom Filter),但HFile文件数目一多还是会比较吃力,因此就需要对HFile做合并操作(Compaction)。Compaction分为minor和major两种级别,本质上都是从几个HFile生成合并后的HFile(类似于合并几个有序数组),然后,老的HFile被删除,起用合并后的HFile。
3. HFile何时会被删除
上面提到过的,在完成Compaction后,老的HFile就会被删除,起用合并后的HFile。
4. Snapshot操作的实现
细心的你是否发现了一个事实,HFile是不会被追加或者修改的!HFile一旦生成,就不会再被改变,只有被拿去合并后,生成了新的HFile,完成自己的使命时才会被删除。
那如果不删除呢?
比如说,我今天建了个表开始跑业务,这个表总共生成了10个HFile,每二天又生成一些HFile,并因此触发了合并操作,现在启用的HFile里有一些是老的没被合并的,有一些是新的由合并产生的。如果昨天那10个HFile还在,那我只要让这个表启用原来的这10个HFile,不就回滚到昨天的状态了嘛。依靠的是什么?就是这10个HFile自从诞生之后就不会被改动,连追加都不会。他们像琥珀一样,记录了这个表昨天的所有数据。
因此,建立Snapshot其实就是把当前所有启用的HFile文件名记录下来,并提醒系统在Compaction时不要删除它们。恢复Snapshot就是重新启用当时的那些HFile。当然这两句话说得不严谨,还有一些细节要处理,比如建Snapshot时要把内存里的东西也存下来先。具体是这样的:
建立Snapshot
1,Master与RegionServer同步,让他们同时进行MemStore flush
2,记录MetaData,即当前表有哪些region,每个region使用的HFile是哪些
3,“标记”HFile以防被删除
*建立Snapshot的过程不需要让表下线。恢复Snapshot
根据Snapshot对应的MetaData恢复各个region,该表需要先下线
总结
本文解析了为什么HBase的Snapshot操作只需要常数时间,不需要复制业务数据。其实说白了就一点,因为HFile生成之后只会被删除,不会被修改,连追加的修改都不会!

















 1502
1502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









