






-
线性回归(linear regression)
-
回归(regression)与梯度下降(gradient descend)
-
回归在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如locally weighted回归,logistic回归,等等。
-
线性回归定义——房屋售价预测系统
做一个房屋价值的评估系统,一个房屋的价值来自很多地方,比如说面积、房间的数量(几室几厅)、地段、朝向等等,这些影响房屋价值的变量被称为特征(feature),feature在机器学习中是一个很重要的概念,有很多的论文专门探讨这个东西。在此处,为了简单,假设我们的房屋就是一个变量影响的,就是房屋的面积。
假设有一个房屋销售的数据如下:
面积(m^2) 销售价钱(万元)
123 250
150 320
87 160
102 220
… …
我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:

我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:
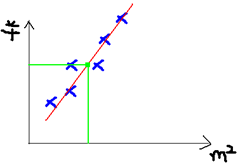
绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号,在不同的机器学习书籍中可能有一定的差别。
房屋销售记录表 - 训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x
房屋销售价钱 - 输出数据,一般称为y
拟合的函数(或者称为假设或者模型),一般写做 y = h(x)
训练数据的条目数(#training set), 一条训练数据是由一对输入数据和输出数据组成的
输入数据的维度(特征的个数,#features),n
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。
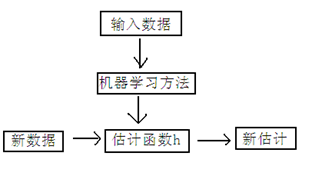
我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:

θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:

我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),描述h函数不好的程度,在下面,我们称这个函数为J函数
在这儿我们可以做出下面的一个错误函数:
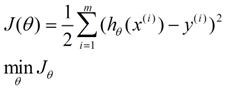
这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square),是一种完全是数学描述的方法,在stanford机器学习开放课最后的部分会推导最小二乘法的公式的来源,这个来很多的机器学习和数学书上都可以找到,这里就不提最小二乘法,而谈谈梯度下降法。
-
最小二乘法
"最小二乘法"的核心就是保证所有数据偏差的平方和最小。("平方"的在古时侯的称谓为"二乘")
假设我们收集到一些战舰的长度与宽度数据

假如我们取前两个点(238,32.4)(152, 15.5)就可以得到两个方程
152*a+b=15.5
328*a+b=32.4
解这两个方程得a=0.197,b=-14.48
那样的话,这样的a,b是不是最优解呢?用专业的说法就是:a,b是不是模型的最优化参数?在回答这个问题之前,我们先解决另外一个问题:a,b满足什么条件才是最好的?答案是:保证所有数据偏差的平方和最小。
-
直接求最优解
要求最优解,即要让预测的结果和真是的结果的误差和最小:
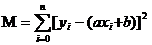
即求使得M最小的参数a和b;就是求这个方程的极小值。
那么利用求偏导数的方式求参数a和b:

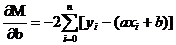
令偏导数=0即可求出极值,也能求出参数a和b。
-
解析式求解最优解
定义矩阵X为(特征属性)样本矩阵,y为样本的观测结果向量
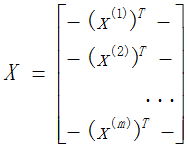

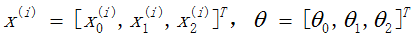

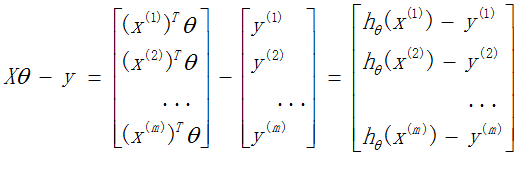
那么,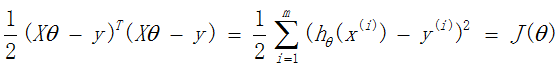
损失函数
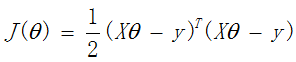
求偏导数,并令之为0
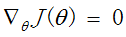
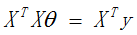
最终结果: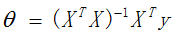
-
梯度下降法
-
梯度
-
在向量微积分中,标量场的梯度是一个向量场。标量场中某一点的梯度指向该点标量场增长最快的方向。或者说,梯度的绝对值是长度为1的方向中函数最大的增长率,也就是其中代表方向导数。
对于单变量的函数来说,梯度就是导数,线性函数就是指的线的斜率。
【理解】假设有一个房间,房间内所有点的温度由一个标量场给出,即点(x,y,z)的温度为,假设温度不随时间改变,然后,在房间的每一点,该点的梯度将显示变热最快的方向。梯度的大小将表示在该方向上变热的速度。
-
梯度的形式化定义
一个变量函数的梯度记为:
(其中表示向量微分算子)
在三维直角坐标系中表示为:
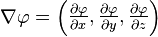
【例子】
函数的梯度为:
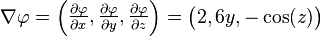
-
梯度下降法
梯度下降法,也称为最速下降法,是一种迭代的搜索方法。朝着"最快下降"的方向进行搜索。首先确定一个初始位置,然后沿着下降最快的方向调整,在若干次迭代后找到局部最小值。
-
梯度下降法缺点
-
靠近极小值时速度减慢
-
直线搜索可能出现一些问题
-
可能会"之字型"地下降
-
梯度下降法使用的一般步骤
求代价函数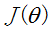
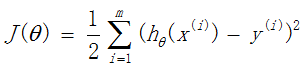
步骤如下:
(1)随机初始化参数:
(2)迭代更新参数θ,直到J(θ)收敛到最小
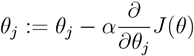
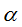
对训练集中的某个单独的样本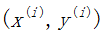
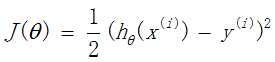
梯度求解:
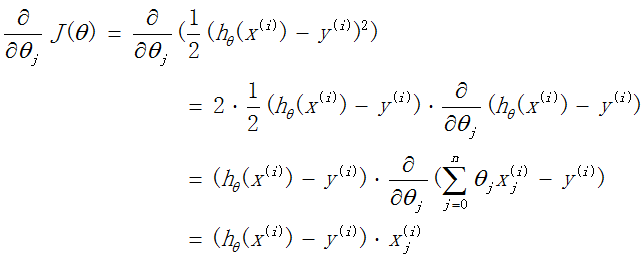
对训练集中的m个样本,代价函数
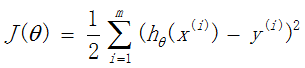
梯度求解:
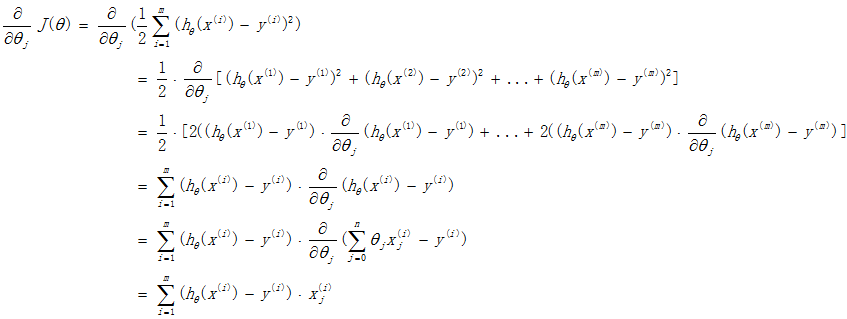
求代价函数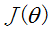
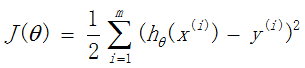
步骤如下:
(1)随机初始化参数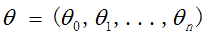
(2)迭代更新参数θ,直到J(θ)收敛到最小:

-
随机梯度下降法
随机梯度下降法每次迭代只带入单个样本,迭代一次计算量为,当样本数综述m很大的时候,随机梯度下降法迭代一次的速度要远小于梯度下降法,随机梯度下降法迭代公式如下:
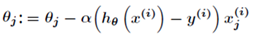
随机梯度下降法每次只带入一个样本进行计算,虽然每次迭代误差准则函数都不一定是向着全局最优方向,但是大的整体方向是向着全局最优方向的,最终得到的结果往往在全局最优解附近。
-
梯度下降法考虑因素
梯度下降法主要考虑两个方面问题:一是方向,二是步长。方向决定是否走在最优化的道路上,而步长决定了要多久才能到达最优的地方。
对于第一方面,就是求梯度,多元函数求相应变量的偏导数;对于第二方面,如果步子太少,则需要很长的时间才能达到目的地,如果步子过大,可能导致在目的地周围来回震荡,所以步长选择比较关键。
-
求最优解
1、如果优化函数存在解析解。例如我们求最值一般是对优化函数求导,找到导数为0的点。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数。
2、如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,互相依赖的情况。或者求导后式子得不到解释解,或者未知参数的个数大于方程组的个数等。这时候使用迭代算法来一步一步找到最优解。















 4148
4148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









