






目录
4、docker存储驱动devicemapper overlay aufs区别和各自优势
1、Docker常用命令
##查看docker容器版本 docker version
##查看docker容器信息 docker info
##查看docker容器帮助 docker --help
##列出本地images docker images
##下载镜像,docker pull redis
##将容器中的文件copy至本地路径 docker cp dockername:/[path] [local_path]
##查看正在运行的容器 docker ps
##查看容器端口映射 docker port redis
##删除一个运行中的容器 docker rm -f redis
##单个镜像删除,docker rmi redis
##构建docker镜像,docker build -f /tmp/dockerfile -t mycentos:1.1
##打包镜像docker save,docker save -o images.tag image1:v1
##docker load将打包的tar中包含的镜像load到本地镜像库,但不能重命名其中的镜像名。docker load -i images.tar
##docker export打包container文件系统,docker export -o thecontainer.tar container_name
##使用 docker import 载入,可以为新镜像指定name和tag
docker import thecontainer.tar newimagename:tag
docker save保存的是镜像(image),docker export保存的是容器(container);
docker load用来载入镜像包,必须是一个分层文件系统,必须是是save的包;
docker import用来载入容器包,但两者都会恢复为镜像;
docker load不能对载入的镜像重命名,而docker import可以为镜像指定新名称。
docker export的包会比save的包要小,原因是save的是一个分层的文件系统,export导出的只是一个linux系统的文件目录
##新建并启动容器,参数:-i 以交互模式运行容器;-t 为容器重新分配一个伪输入终端;--name 为容器指定一个名称 docker run -i -t --name mycentos
##启动一个或多个已经被停止的容器 docker start redis
##重启容器 docker restart redis
##列出redis容器中运行进程 docker top redis
##查看redis容器日志,默认参数 docker logs rabbitmq
##在 centos 容器中打开新的交互模式终端,可以启动新进程,参数:-i 即使没有附加也保持STDIN 打开;-t 分配一个伪终端 docker exec -i -t centos /bin/bash
2、dockerfile命令
FROM 功能为指定基础镜像,并且必须是第一条指令:FROM <image>
RUN 功能为运行指定的命令:RUN ["/bin/bash", "-c", "echo hello"]
LABEL 为镜像指定标签:LABEL "com.example.vendor"="ACME Incorporated"
EXPOSE 功能为暴漏容器运行时的监听端口给外部:EXPOSE port
ENV功能为设置环境变量:ENV <key>=<value>
WORKDIR设置工作目录:WORKDIR /path/to/workdir
COPY与ADD的区别
ADD 复制命令,把文件复制到镜像中
1.ADD <src>... <dest>,例:ADD test relativeDir/
2.ADD ["<src>",... "<dest>"]
COPY 复制命令
1.COPY <src>... <dest>
2.COPY ["<src>",... "<dest>"]
COPY指令和ADD指令的唯一区别在于是否支持从远程URL获取资源,COPY的<src>只能是本地文件,其他用法一致
CMD和ENTRYPOINT区别
ENTRYPOINT 启动时的默认命令,其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
1. ENTRYPOINT ["executable", "param1", "param2"]
2. ENTRYPOINT command param1 param2
CMD容器启动以后,默认的执行的命令,如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
CMD ["executable","param1","param2"] (推荐使用这种,比较明确)
CMD ["param1","param2"] # 该写法是为 ENTRYPOINT 指令指定的程序提供默认参数
CMD command param1 param2
如果docker run没有指定任何的执行命令或者dockerfile里面也没有entrypoint,那么,就会使用cmd指定的默认的执行命令执行。同时也从侧面说明了entrypoint的含义,它才是真正的容器启动以后要执行命令。
ENTRYPOINT搭配 CMD 命令使用
一般是变参才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参。
示例:假设已通过 Dockerfile 构建了 nginx:test 镜像:
FROM nginx
ENTRYPOINT ["nginx", "-c"] # 定参
CMD ["/etc/nginx/nginx.conf"] # 变参 1、不传参运行
$ docker run nginx:test容器内会默认运行以下命令,启动主进程。
nginx -c /etc/nginx/nginx.conf
2、传参运行
$ docker run nginx:test -c /etc/nginx/new.conf容器内会默认运行以下命令,启动主进程(/etc/nginx/new.conf:假设容器内已有此文件)
nginx -c /etc/nginx/new.conf
3、容器分层结构,只读层,读写层,写时复制,用时分配
分层结构
新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层
可分为
第一层:镜像层(只读层,roLayer),分层信息记录在
/var/lib/docker/image/{graph_driver}/layerdb/sha256/{chainID} 目录中
第二层:init 层,分层信息记录在
/var/lib/docker/image/{graph_driver}/layerdb/sha256/{chainID_init}目录中
第三层:容器层(读写层,mountLayer),分层信息存放在
/var/lib/docker/image/{graph_driver}/layerdb/mounts/{container_id} 目录中
容器(container)和镜像(image)的最主要区别就是容器加上了顶层的读写层
在容器的设计当中,通过同一个Image启动的容器,全部都共享这个image,而并不复制。在镜像的最上层,有一个读写层。而这个读写层,即在容器启动时为当前容器单独挂载。每一个容器在运行时,都会基于当前镜像在其最上层挂载一个读写层。而用户针对容器的所有操作都在读写层中完成。一旦容器销毁,这个读写层也随之销毁。针对这个读写层的操作,主要基于两种方式:写时复制和用时分配
写时复制(CoW)
CoW就是copy-on-write,表示只在需要写时才去复制,这个是针对已有文件的修改场景。CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。所以无论有多少个容器共享同一个image,所做的写操作都是对从image中复制到自己的文件系统中的复本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都是自己的复本,相互隔离,相互不影响。
用时分配
用时分配是用在原本没有这个文件的场景,只有在要新写入一个文件时才分配空间,这样可以提高存储资源的利用率。比如启动一个容器,并不会为这个容器预分配一些磁盘空间,而是当有新文件写入时,才按需分配新空间。
参考:https://blog.csdn.net/iov_aaron/article/details/97135158
4、docker存储驱动devicemapper overlay aufs区别和各自优势
AUFS
AUFS(AnotherUnionFS)是一种Union FS,是文件级的存储驱动。支持将不同目录挂载到同一个虚拟文件系统下的文件系统。这种文件系统可以一层一层地叠加修改文件。无论底下有多少层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS创建该文件的一个副本,使用CoW将文件从只读层复制到可写层进行修改,结果也保存在可写层。在Docker中,底下的只读层就是image,可写层就是Container。
OverlayFS
OverOverlayFSlayFS,也是一种Union FS,和AUFS的多层不同的是Overlay只有两层:一个upper文件系统和一个lower文件系统,分别代表Docker的镜像层和容器层。当需要修改一个文件时,使用CoW将文件从只读的lower复制到可写的upper进行修改,结果也保存在upper层。在Docker中,底下的只读层就是image,可写层就是Container。目前最新的OverlayFS为Overlay2。
Devicemapper
Devicemapper是块级存储,所有的操作都是直接对块进行操作,而不是文件。Device mapper驱动会先在块设备上创建一个资源池,然后在资源池上创建一个带有文件系统的基本设备,所有镜像都是这个基本设备的快照,而容器则是镜像的快照。所以在容器里看到文件系统是资源池上基本设备的文件系统的快照,并没有为容器分配空间。当要写入一个新文件时,在容器的镜像内为其分配新的块并写入数据,这个叫用时分配。当要修改已有文件时,再使用CoW为容器快照分配块空间,将要修改的数据复制到在容器快照中新的块里再进行修改。Device mapper 驱动默认会创建一个100G的文件包含镜像和容器。每一个容器被限制在10G大小的卷内,可以自己配置调整。
devicemapper、overlay、aufs的优缺点
| 存储驱动 | 特点 | 优点 | 缺点 | 适用场景 |
| AUFS | 联合文件系统、未并入内核主线、文件级存储 | 作为docker的第一个存储驱动,已经有很长的历史,比较稳定,且在大量的生产中实践过,有较强的社区支持 | 有多层,在做写时复制操作时,如果文件比较大且存在比较低的层,可能会慢一些 | 大并发但少IO的场景 |
| overlayFS | 联合文件系统、并入内核主线、文件级存储 | 只有两层 | 不管修改的内容大小都会复制整个文件,对大文件进行修改显示要比小文件消耗更多的时间 | 大并发但少IO的场景 |
| Devicemapper | 并入内核主线、块级存储 | 块级无论是大文件还是小文件都只复制需要修改的块,并不是整个文件 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本,在很多容器启停的情况下可能会导致磁盘溢出 | 适合io密集的场景 |
https://www.cnblogs.com/breezey/p/9589288.html
5、cgroup、namespace、rootfs
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
完整的容器可以用以下公示描述:容器=Cgroup+Namespace+rootfs+容器引擎(用户态工具)。
| Cgroup: | 资源控制 |
|---|---|
| Namespace: | 访问隔离 |
| rootfs: | 文件系统隔离 |
| 容器引擎: | 生命周期控制 |
namespace
Namespace又称为命名空间,它主要做访问隔离。其原理是针对一类资源进行抽象,并将其封装在一起提供给一个容器使用,对于这类资源,因为每个容器都有自己的抽象,而他们彼此之间是不可见的,所以就可以做到访问隔离。

6种在Linux 内核中实现的Namespace
在/proc/{pid}/ns目录下可以看到

| IPC | 隔离 信号量、 POSIX 消息队列、共享内存 |
|---|---|
| Network | 隔离网络资源(网络设备、网络协议栈、端口等) (通过添加网络空间进行隔离(ip nets add ***),创建两块相连的虚拟网卡对,一块添加到新的网络空间) |
| Mount | 隔离文件系统挂载点(通过mount实现) |
| PID | 隔离进程ID(隔离/proc目录) |
| UTS | 隔离主机名和域名 (每一个进程都有一个属于自己的uts命名空间。多个进程可共享这个命名空间 。 创建容器时,通过CLONE_UTSNS来指定一个新的命名空间。待容器中的init进程创建子进程时,子进程复制其父进程的uts命名空间。这样做到了再一个容器中的所有进程共享一个uts命名空间,从而其相应的utsname信息也是共享一份的。 ) |
| User | 隔离用户和用户组 (同样一个用户的 user ID 和 group ID 在不同的 user namespace 中可以不一样。 每个用户命令空间有一张表,这张表中记录着宿主机中用户ID对应namespace 的用户ID。这种映射是通过读写/proc/PID/uid_map(/proc/PID/gid_map gid映射文件)伪文件来设置,其中PID是user namespace这个进程的进程ID。) |
Cgroups
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。
Cgroup主要是做资源控制。原理是将一组进程放在放在一个控制组里,通过给这个控制组分配指定的可用资源,达到控制这一组进程可用资源的目的。
Cgroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 Cgroup 子系统或控制器。


任务(task)。在 cgroups 中,任务就是系统的一个进程;
控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制;
层级(hierarchy)。控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性;
子系统(subsystem)。一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
cgroup原理
Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup,该目录下是各个子系统的根目录, cgroups 是以这些文件作为 API 的。
cgroup真正的工作原理就是hook钩子,本质上是给系统进程挂上钩子实现的,当task进程运行的过程中,涉及到某个资源时,就会触发钩子上附带的subsystem子系统进行资源检测,最终根据资源类别的不同使用对应的技术进行资源限制和优先级分配。
钩子是怎么实现的
简单来说,linux中管理task进程的数据结构,在每个task设置一个关键词,将关键词都指向钩子,叫做指针。
一个task只对应一个指针结构时,一个指针结构可以被多个task进行使用
当一个指针一旦读取到唯一指针数据的内容,task就会被触发,就可以进行资源控制
rootfs
rootfs 代表一个 Docker 容器在启动时(而非运行后)其内部进程可见的文件系统视角,或者叫 Docker 容器的根目录。

在容器中修改用户视角下文件时,Docker 借助 COW(copy-on-write) 机制节省不必要的内存分配。
在 Linux 操作系统里,有一个名为 chroot 的命令可以帮助你在 shell 中方便地完成这个工作。顾名思义,它的作用就是帮你“change root file system”,即改变进程的根目录到你指定的位置。它的用法也非常简单。
6、Docker网络模型
| Docker网络模式 | 配置 | 说明 |
|---|---|---|
| host模式 | –net=host | 容器和宿主机共享Network namespace。 |
| container模式 | –net=container:NAME_or_ID | 容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。 |
| none模式 | –net=none | 容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等。 |
| bridge模式 | –net=bridge | (默认为该模式) |
host模式
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能比较好,但是docker host上已经使用的端口就不能再用了,网络的隔离性不好。
Host模式如下图所示:

container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
Container模式示意图:
none模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过--network=none来指定。这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
None模式示意图:

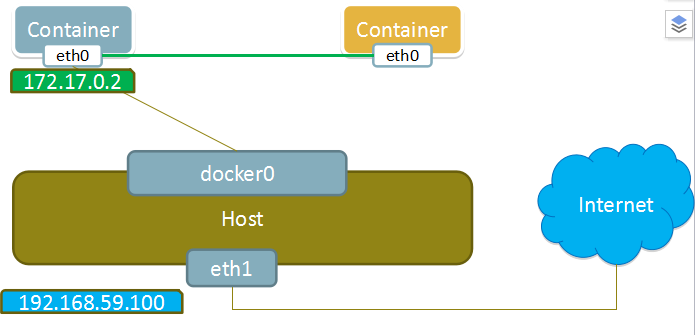
bridge模式
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。
bridge模式是docker的默认网络模式,不写--net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
bridge模式如下图所示:
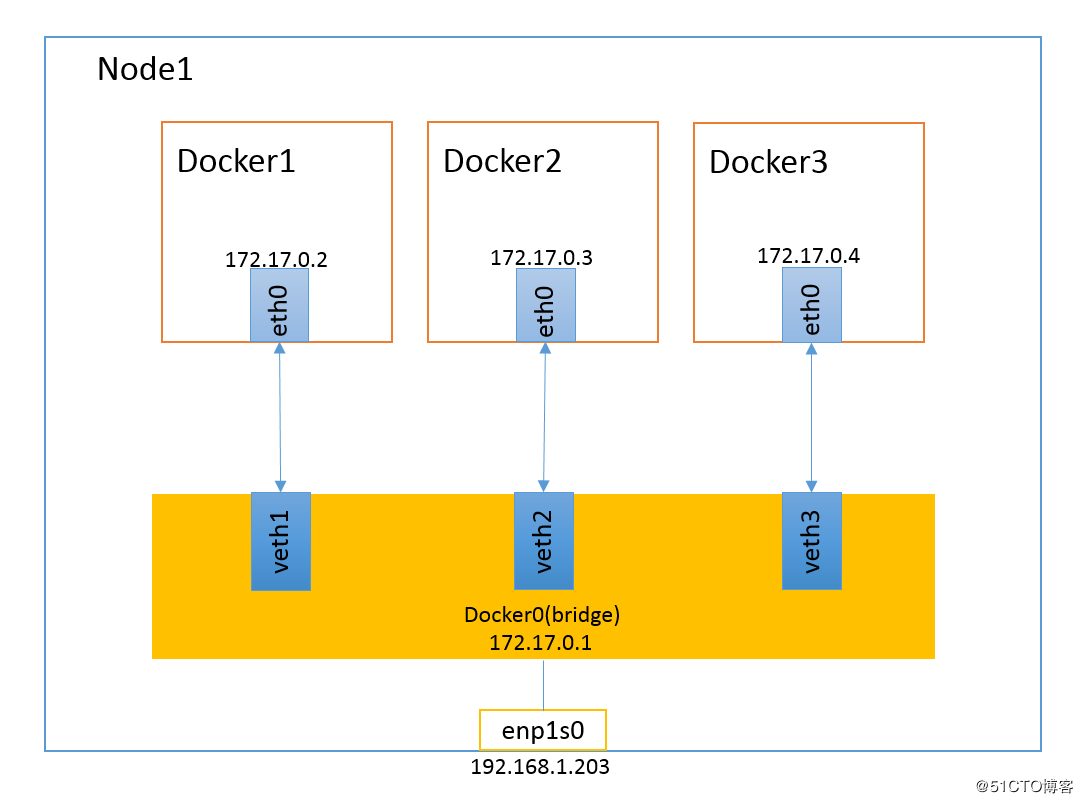
https://www.jianshu.com/p/22a7032bb7bd















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









