







 本文介绍了如何使用BeautifulSoup和Selenium爬取Bilibili的新番信息,包括新番名称、观看人数和弹幕数量。在解析HTML时遇到问题,但最终成功实现。翻页通过定位并点击下一页元素实现,爬取的数据将存储到数据库中,数据库操作部分将在后续博客讲解。
本文介绍了如何使用BeautifulSoup和Selenium爬取Bilibili的新番信息,包括新番名称、观看人数和弹幕数量。在解析HTML时遇到问题,但最终成功实现。翻页通过定位并点击下一页元素实现,爬取的数据将存储到数据库中,数据库操作部分将在后续博客讲解。
最近过年啦,祝大家新年快乐,万事如意。
由于前几天回到家后比较忙,就没时间更新。然后昨天终于闲了下来,就写了个爬取Bilibili新番的爬虫。
这次主要也还是用beautifulsoup,selenium来爬取信息,当然在存储数据的时候还会用到一些mysql的知识,这个在下一篇博客再讲吧。
那么接下来开始这次的记录。
先看我们这次要抓取的内容。
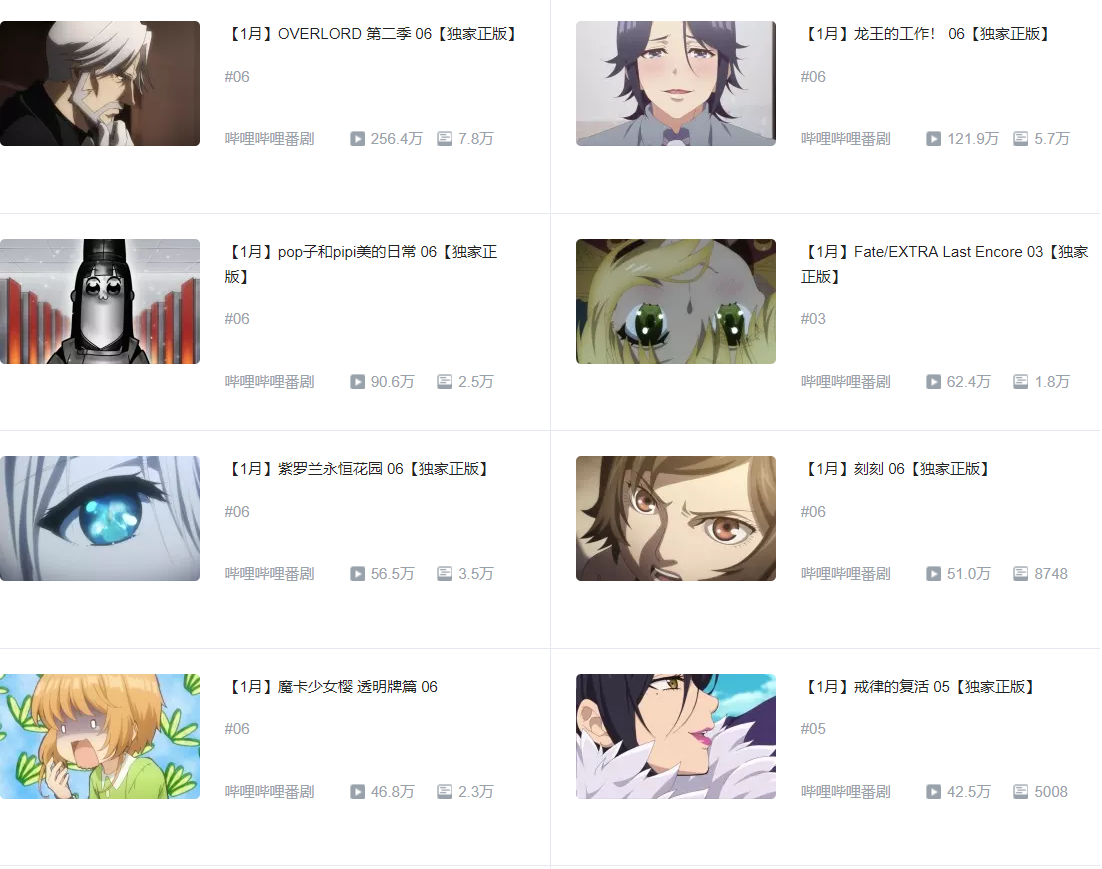
我们要抓取的是这个部分的新番名,还有观看人数,以及弹幕的数量,接下来我们看一下它们分别在HTML页面的哪个地方。
按一下F12
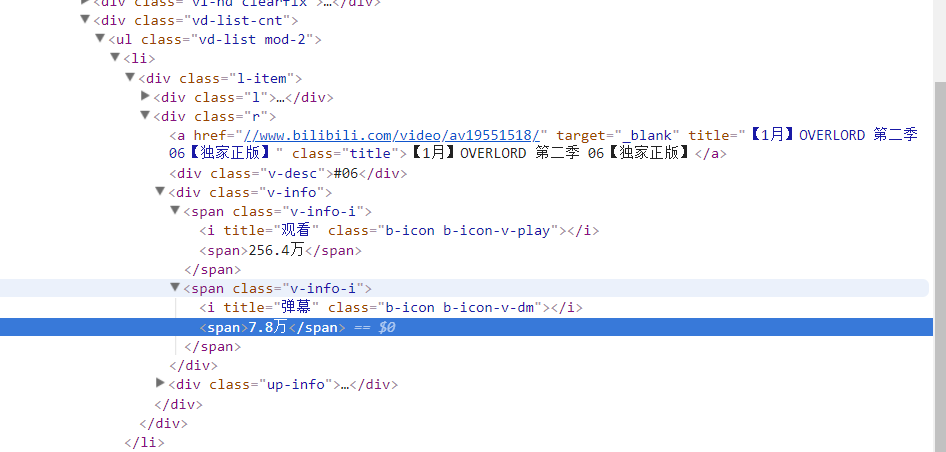
我们可以发现其实每个新番都在class为r的div里面,而观看人数和弹幕都在class为v-info-i里面,需要注意的是这两个是一样的,我昨天在爬取的时候在这里遇到了一点小麻烦,只能说学艺不精,待会再讲。
接下来看这几行代码:
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#videolist_box > div.vd-list-cnt > ul > li:nth-child(1) > div > div.r'))
)我们通过定位得到这个元素,接下来只要用beautifulsoup就可以得到新番名字了,关键是接下来这一步。
自己代码还是写的太少了,所以在得到观看人数和弹幕这两个数据的时候卡了一会才想出来怎么解决。
让我们先看代码:
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')
items = soup.find_all('div',class_ = 'r') #用find_all()函数找到该页面所有的新番
for item in items:
item1 = item.find_all('span',class_ = 'v-info-i') #这一步是我得到观看人数和弹幕的关键,找到第i个新番的所有v-info-i
Anime_name = item.find('a',class_ = 'title').text #得到新番名
Viewing_name = item1[0].text #得到观看人数
Barrage = item1[1].text #得到弹幕数量在我们得到页面的源代码后,我们通过beautifulsoup来解析网页
我们贴上这一段的完整代码:
def get_response(self):
driver = self.driver
wait = self.wait
try:
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#videolist_box > div.vd-list-cnt'))
)
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#videolist_box > div.vd-list-cnt > ul > li:nth-child(1) > div > div. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









