









 本文介绍LeetCode 779题“第K个语法符号”的多种解法,包括递归法和位运算法,并分析了每种方法的特点及适用场景。
本文介绍LeetCode 779题“第K个语法符号”的多种解法,包括递归法和位运算法,并分析了每种方法的特点及适用场景。
On the first row, we write a 0. Now in every subsequent row, we look at the previous row and replace each occurrence of 0 with 01, and each occurrence of 1 with 10.
Given row N and index K, return the K-th indexed symbol in row N. (The values of K are 1-indexed.) (1 indexed).
Examples: Input: N = 1, K = 1 Output: 0 Input: N = 2, K = 1 Output: 0 Input: N = 2, K = 2 Output: 1 Input: N = 4, K = 5 Output: 1 Explanation: row 1: 0 row 2: 01 row 3: 0110 row 4: 01101001
Note:
Nwill be an integer in the range[1, 30].Kwill be an integer in the range[1, 2^(N-1)].
我想,肯定是我这个字符串占用的内存太大了,毕竟有可能有2^30长度呢。于是我就想另一个方法,用队列,算完一个去掉一个。比如一开始队列offer进了0,然后出队列0,进队列01.....但是这个方法耗时太高了,kthGrammar(30, 434991989)这个测试用例久久跑不出结果。我只能继续想办法。
我发现结果跟行数 N 无关,因为每一行都是由上一行在末尾加上数字得到的。而我们要注意的是 K,第K个数是由上一行的第 ⌈K/2⌉ 个数算出来的。(比如第7个数是由第4个数算出来的,且数字等于第4个数。 第8个数是由第4个数算出来的,且数字与第4个数相反)。因此得到递归解法。
package leetcode;
public class K_th_Symbol_in_Grammar_779 {
public int kthGrammar(int N, int K) {
if(K==1){
return 0;
}
if(K==2){
return 1;
}
if(K%2==1){
return kthGrammar(-1, (K+1)/2);
}
else{
return 1-kthGrammar(-1, K/2);
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
K_th_Symbol_in_Grammar_779 k=new K_th_Symbol_in_Grammar_779();
System.out.println(k.kthGrammar(30, 434991989));
}
}而另外有的大神发现了数字序列的规律,用了另外一种方法一行解决。
public int kthGrammar(int N, int K) {
return Integer.bitCount(K-1) & 1;
}
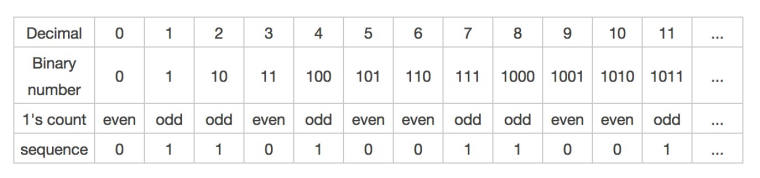
sequence中的序列正好是题目中的序列。

















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









