









Kmeans算法介绍

基本原理


伪代码

聚类结果评估


编程实现
封装,KMeansCluster_Class.py
# -*- coding: utf-8 -*-
"""
Created on Mon May 4 16:26:05 2020
@author: Hja
@Company:北京师范大学珠海分校
@version: V1.0
@contact: 583082258@qq.com 2018--2020
@software: Spyder
@file: KMeansCluster_Class.py
@time: 2020/4/22 9:02
@Desc:kMeans聚类
"""
import time
from copy import deepcopy
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.datasets import make_blobs
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import mglearn
import warnings
warnings.filterwarnings("ignore")#消除警告
# 初始化图形参数
plt.rcParams['figure.figsize'] = (16,9)# 设置大小
# 图形美化
plt.style.use('ggplot')
class KMeansCluster(object):
'''KMeans聚类'''
def __init__(self,n_clusters = 8,max_iter = 300):
'''
n_clusters: ,默认= 8,形成的簇数以及生成的质心数
max_iter :默认为300,单次运行的k均值算法的最大迭代次数
'''
self.n_clusters = n_clusters
self.max_iter = max_iter
self.X_train = None# 训练集
self.n_iter = None# 运行迭代的次数
self.Center_point = None# 保存当前中心点的坐标
self.Center_point_old = None# 用于保存中心点更新前的坐标
self.clusters = None# 用于保存数据所属的中心点
self.iteration_flag = None# 迭代标识位,通过计算新旧中心点的距离
self.labels_ = None# 保存训练数据类标,标签本身并没有先验意义
# self.DBI = None# 度量聚类优劣的指标, DBI指数,越小越好
self.Intra_Dis = None# 存放所有类内距离之和
self.score = None# 存放 类间间距/类内间距 来衡量聚类结果的好坏,越大越好
def dist(self,matrix_a,matrix_b,ax = 1):
# linalg=linear(线性)+algebra(代数),norm则表示范数,默认二范数
# axis=1表示按行向量处理,求多个行向量的范数
'''
matrix_a like :
array([[12., 40.],
[80., 22.],
[10., 4.]], dtype=float32)
matrix_b like:
array([[0., 0.],
[0., 0.],
[0., 0.]])
if axis = 1,即按行求范数
return array([41.76122604, 82.96987405, 10.77032961])
or axis = 0,按列求范数
returnarray([81.51073549, 45.82575695])
'''
return np.linalg.norm(matrix_a - matrix_b,axis = ax)
def fit(self,X_train):
self.X_train = X_train
# X_train is a np.array
# Center_point 是一个n_clusters行,X_train.shape[1]列的矩阵
self.Center_point = np.zeros((self.n_clusters,self.X_train.shape[1]),dtype = np.float32)# 存放随机初始化的中心点
# print(self.Center_point)
# 随机获得中心点
for i in range(self.X_train.shape[1]):# 面对多维数据集
# print(i)
self.Center_point[:,i] = np.random.choice(self.X_train[:,i],size = self.n_clusters)
# Center_point 的第i列从 X_train的第i列中随机抽取长度为 n_clusters
# print('第{}列:{}'.format(i,self.Center_point[:,i]))
self.Center_point_old = np.zeros(self.Center_point.shape,dtype = np.float32)# 初始化
# 用于保存数据所属的中心点
self.clusters = np.zeros(len(self.X_train),dtype = np.int)
# 迭代标识位,通过计算新旧中心点的距离
# self.iteration_flag = self.dist(self.Center_point,self.Center_point_old,1)
self.iteration_flag = np.ones(self.n_clusters)
# 记录迭代次数
self.n_iter = 1
# 若中心点不再变化 or 循环次数超过300次,则退出循环
print('-'*25,'The kmeans is running...','-'*25)
while self.iteration_flag.any() != 0 and self.n_iter < self.max_iter:
# 同时满足两个条件则继续循环
# iteration_flag like:array([0,0,0]) 则会退出循环
# 循环计算每个点对应的最近中心点
for i in range(len(self.X_train)):
# 计算出每个点与中心点的距离
distances = self.dist(self.X_train[i],self.Center_point,1)#x[i] like : array([17.93671, 15.78481])
# distances like :array([44.3666806 , 81.91375025, 10.73731025])
# 其中第一个值是x[i] 到 Center_point中第一个点的距离
# 记录x[i] 离Center_point中最近的点
culuster = np.argmin(distances)# np.argmin(a)返回 a 中最小元素的索引
# 记录每个样例点与那个中心点距离最近
self.clusters[i] = culuster
# 用深度拷贝将当前的中心点保存
self.Center_point_old = deepcopy(self.Center_point)
'''
为什么用深度拷贝?
d = Center_point
d like:array([[12., 40.],
[80., 22.],
[10., 4.]], dtype=float32)
Center_point like:
array([[12., 40.],
[80., 22.],
[10., 4.]], dtype=float32)
Then
Center_point[0] = np.array([1,1])
d =
array([[ 1., 1.],
[80., 22.],
[10., 4.]], dtype=float32)
'''
# print(self.Center_point_old)
# 从属于同一中心点放到一个数组中,然后按照列的方向取平均值更新中心点
for i in range(self.n_clusters):
# 第 i 个类簇
points = [self.X_train[j] for j in range(len(self.X_train)) if self.clusters[j] == i]
if points == []:# 如果某一类并没有分到数据点,points = [],那么np.mean()后会返回nan,影响后续计算
# In: np.mean([])
# Out: nan
self.Center_point[i] = np.zeros(self.X_train.shape[1],dtype = np.float32)
else:
# 更新中心点
self.Center_point[i] = np.mean(points,axis = 0)# 按照列的方向取平均值
print(u'**循环第%d次**'%self.n_iter)
self.n_iter += 1
# 更新新旧中心点的距离
self.iteration_flag = self.dist(self.Center_point,self.Center_point_old,1)
print("新中心点与旧点的距离:", self.iteration_flag)
self.labels_ = self.clusters# 存放数据类别
self.Intra_class_spacing()# 运行该函数,给self.Intra_Dis 赋值
self.score = self.Inter_class_spacing() / self.Intra_Dis # 衡量聚类结果
# self.DBI = self.Davies_Bouldin()# 计算DBI系数
def predict(self,X_test):
'''
根据当前的中心点
对X_test进行预测
标签本身并没有先验意义
'''
clusters_pred = np.zeros(len(X_test))# 存放类标
for i in range(len(X_test)):# 循环计算每个点对应的最近中心点
distances = self.dist(X_test[i],self.Center_point,1)# 计算距离
cluster = np.argmin(distances)# 得出类别,其实就是索引
clusters_pred[i] = cluster
return clusters_pred
def Intra_class_spacing(self):
'''
计算类内间距
return like :{0: 17.75349746798756, 1: 18.41602776546014, 2: 17.605171601877746}
0类 类内间距:17.75... 1类 类内间距:18.41..... 2类 类内间距:17.6.....
'''
Intra_dic = {}
Intra_dis = 0.0
for i in range(self.n_clusters):
# 取出第 i 类的数据点
points = [self.X_train[j] for j in range(len(self.X_train)) if self.clusters[j] == i]
if points == []:# 健壮性
continue
else:
dis = 0.0
temp = 0.0
for point in points:# 计算每一条数据与同类其他所有数据的距离
dis += np.sum(self.dist(point,points))# 求和
# print(points)
# 距离求和 除以 该类样本数 的平方
temp = dis / len(points) ** 2
Intra_dic[i] = temp# 第 i类的类内距离存放在字典中
Intra_dis += temp# 将所有类内距离相加
self.Intra_Dis = Intra_dis / float(self.n_clusters)# 取均值封装
return Intra_dic
def Inter_class_spacing(self):
'''
计算类间间距
'''
Inter_dis = 0.0
count = 0# 计数器
# pass
# 比如聚成3 类,即n_clusters = 3
# 那么i = 0,j = [0,1,2,3),计算0-1类间的距离,0-2类间的距离
# 那么i = 1,j = [1,2,3),计算1-2类间的距离
# 那么i = 2,j = [2,3),不计算
for i in range(self.n_clusters):
for j in range(i + 1,self.n_clusters):
if i != j:
count += 1
# 取出第 i 类的数据点
points_i = [self.X_train[k] for k in range(len(self.X_train)) if self.clusters[k] == i]
# 取出第 j 类的数据点
points_j = [self.X_train[k] for k in range(len(self.X_train)) if self.clusters[k] == j]
if points_i == [] or points_j == []:# 如果某一类没有分配到数据点,在k值较大时会有这种情况,此时分母就为0
continue
else:
dis = 0.0# 存放距离的中间变量
for point in points_i:# 计算 i类 每一条数据与 j类 所有数据的距离
dis += np.sum(self.dist(point,points_j))
temp = np.sum(dis) / (len(points_i) * len(points_j))
Inter_dis += temp# 将所有类间距离相加
return Inter_dis / float(count)# 取平均
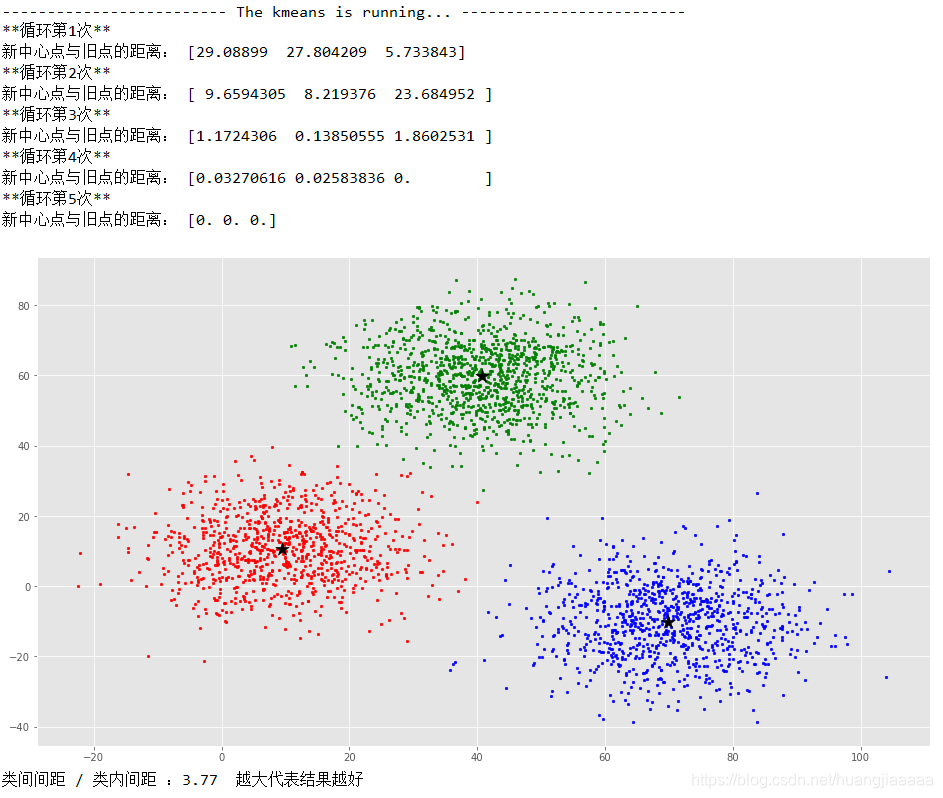
先跑一下正常的二维数据集,下面的接在上面代码下面
if __name__ == '__main__':
# 导入数据集
path = r'F:\大三下\李艳老师数据挖掘实践\实验八\KMeans数据集.csv'
data = pd.read_csv(path,header = None)
#print(data.shape)
#print(data.head())
X_train = np.array(data,dtype = np.float64)
# 建模
kmeans = KMeansCluster(n_clusters = 3,max_iter = 30)
kmeans.fit(X_train)
# 结果可视化
colors = ['r','g','b','y','c','m']
fig,ax = plt.subplots()
# 不同的子集用不同的颜色
for i in range(kmeans.n_clusters):
points = np.array([X_train[j] for j in range(len(X_train)) if kmeans.clusters[j] == i])
ax.scatter(points[:,0],points[:,1],s = 7,c = colors[i])
ax.scatter(kmeans.Center_point[:, 0], kmeans.Center_point[:, 1], marker='*', s=200, c='black')
plt.show()
print('类间间距 / 类内间距 :{:.2f} 越大代表结果越好'.format(kmeans.score))
运行结果
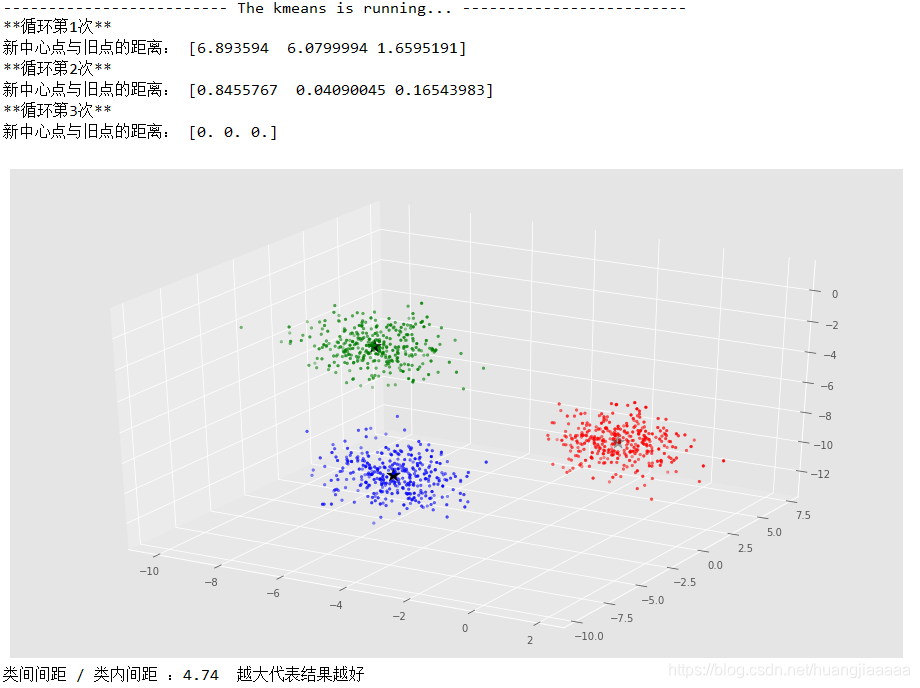
再尝试一下三维数据
if __name__ == '__main__':
# 三维数据
X,y = make_blobs(n_samples = 1000,n_features = 3,random_state = 1)
kmeans = KMeansCluster(n_clusters = 3,max_iter = 30)
kmeans.fit(X)
#定义坐标轴
fig = plt.figure()
ax = plt.axes(projection='3d')
colors = ['r','g','b','y','c','m']
## 不同的子集用不同的颜色
for i in range(kmeans.n_clusters):
points = np.array([X[j] for j in range(len(X)) if kmeans.clusters[j] == i])
ax.scatter3D(points[:,0],points[:,1],points[:,2],s = 7,c = colors[i])
ax.scatter3D(kmeans.Center_point[:, 0], kmeans.Center_point[:, 1],kmeans.Center_point[:,2], marker='*', s=200, c='black')
plt.show()
print('类间间距 / 类内间距 :{:.2f} 越大代表结果越好'.format(kmeans.score))
运行结果
KMeans无法识别具有复杂形状的簇
if __name__ == '__main__':
# KMeans无法识别具有复杂形状的簇
from sklearn.datasets import make_moons
X,y = make_moons(n_samples = 5000,noise = 0.05,random_state = 1)
# 将数据聚类成2个簇
kmeans = KMeansCluster(n_clusters = 3,max_iter = 100)
kmeans.fit(X)
# 结果可视化
colors = ['r','g','b','y','c','m']
fig,ax = plt.subplots()
# 不同的子集用不同的颜色
for i in range(kmeans.n_clusters):
points = np.array([X[j] for j in range(len(X)) if kmeans.clusters[j] == i])
ax.scatter(points[:,0],points[:,1],s = 1,c = colors[i])
ax.scatter(kmeans.Center_point[:, 0], kmeans.Center_point[:, 1], marker='*', s=200, c='black')
plt.show()
print('k = {}时 *类间间距 / 类内间距 :{:.2f}* 越大代表结果越好'.format(kmeans.n_clusters,kmeans.score))
运行结果















 3438
3438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









