






阅读文本大概需要3分钟。
上篇《分布式爬虫管理平台Crawlab开发搭建》把爬虫的管理后台搭建起来了;捣鼓一番发现要真正爬取数据还有下不少的功夫。这篇看看怎么搭建python+scrapy环境。
0x01:安装Python3
下载python安装包,具体版本根据自己的系统要求
https://www.python.org/downloads/windows/
下载安装完成后直接cmd输入python,可正常查看版本
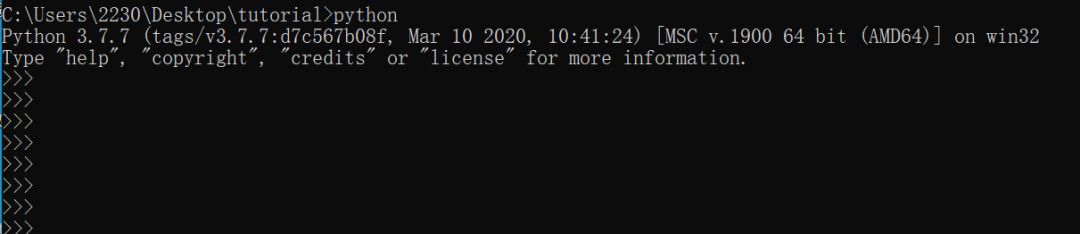
注:安装过程中请注意一定要请勾选pip安装并加入到环境变量中,否则后续无法正常安装第三方类库。
0x02:安装爬虫所需的一些常用类库
安装 selenimu 自动化web包,cmd进入任意目录,执行
pip install selenium
安装 pymysql 连接mysql包,cmd进入任意目录,执行。方便以后把爬取的数据插入数据库
pip install pymysql
安装 pillow 图片处理包
pip install pillow
备注:pillow官网
https://pillow.readthedocs.io/en/latest/installation.html
安装 pypiwin32 操作底层dll包
pip install pypiwin32
安装 requests 发送web请求包
pip install requests
安装 scrapy 爬虫框架包
pip install scrapy
备注:安装爬虫框架必须依赖的第三方类库Twisted,在使用pip安装时会出现下载文件失败而无法安装问题,可以先下载Twisted安装文件。然后使用pip install安装Twisted。
pip install 下载Twisted文件绝对路径
下载地址如下(下载与Python版本匹配的whl文件):
https://www.lfd.uci.edu/~gohlke/pythonlibs/
安装解析网页内容包
pip install bs4
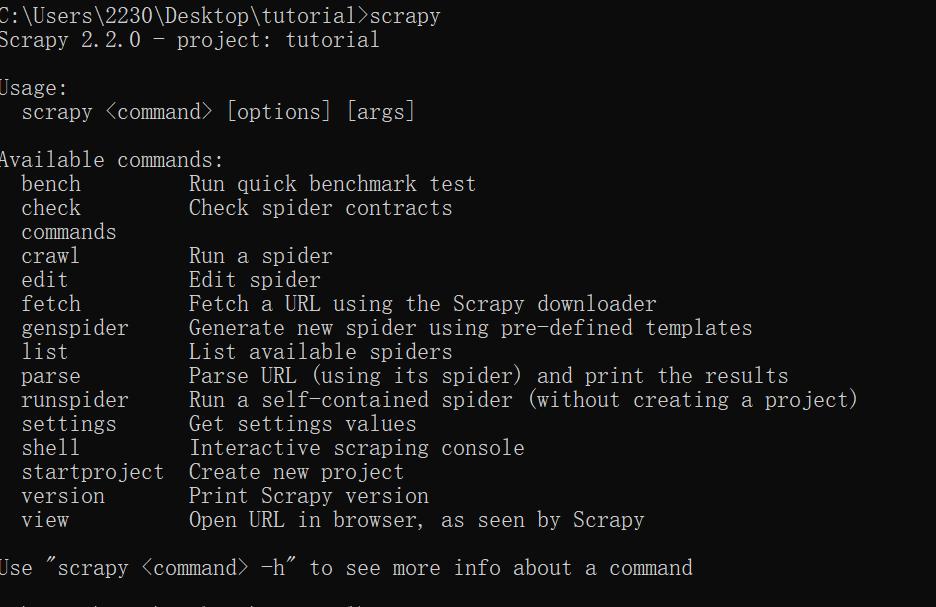
0x03:验证scrapy 是否安装成功
进入cmd,输入 scrapy 查看scrapy是否安装成功
0x04:创建爬虫项目
创建项目,只需一行命令即可创建名为 tutorial 的Scrapy项目:
scrapy startproject tutorial
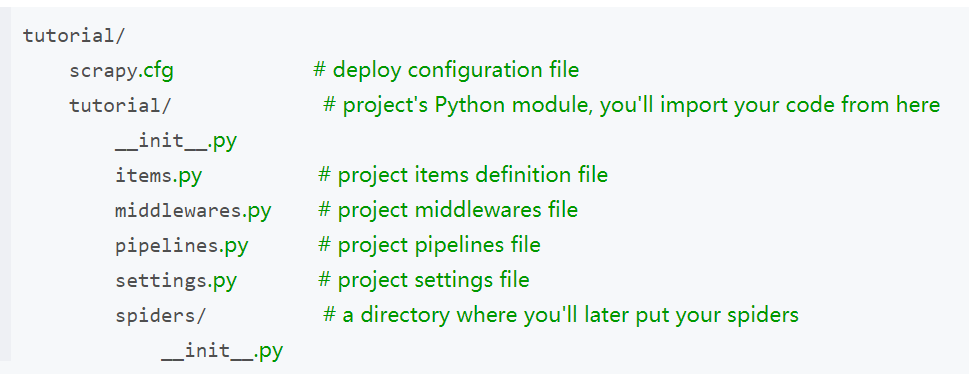
tutorial项目的目录结构大概如下:
创建爬虫的模板文件
进入 ./tutorial/tutorial 执行:
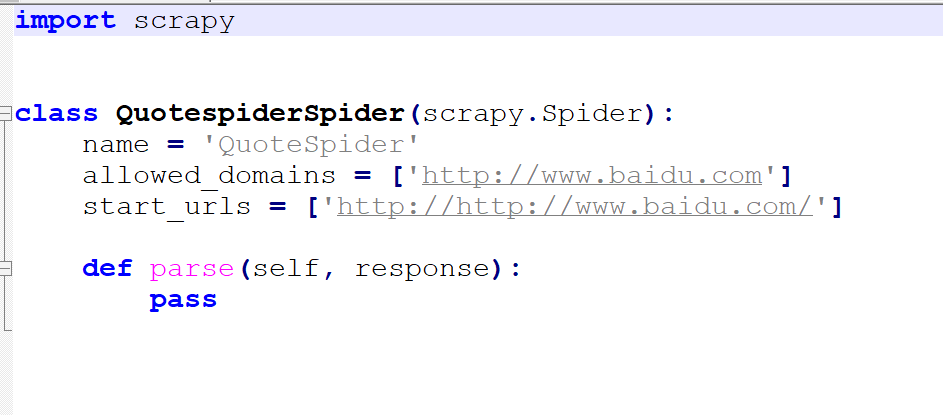
scrapy genspider QuoteSpider "http://www.baidu.com"
QuoteSpider是文件名,http://www.baidu.com是要爬取的域名, ./tutorial/tutorial/spiders 目录下生成一个QuoteSpider.py文件。文件内容如下:
修改一下QuoteSpider.py文件:
import scrapy
class QuotespiderSpider(scrapy.Spider):
name = 'QuoteSpider'
# 允许爬取的域名
# allowed_domains = ['landchina.mnr.gov.cn']
start_urls = ['http://landchina.mnr.gov.cn/scjy/tdzr/index_1.htm']
def parse(self, response): # resonse相当于从网络中返回内容所存储的或对应的对象
fname = response.url.split('/')[-1] # 定义文件名字,把response中的内容写到一个html文件中
with open(fname, 'wb') as f: # 从响应的url中提取文件名字作为保存为本地的文件名,然后将返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % fname) # self.log是运行日志,不是必要的
这个代码很简单就是爬取一个页面,并保存到文件中。
执行tutorial爬虫项目,在cmd目录中执行
scrapy crawl QuoteSpider
执行日志如下
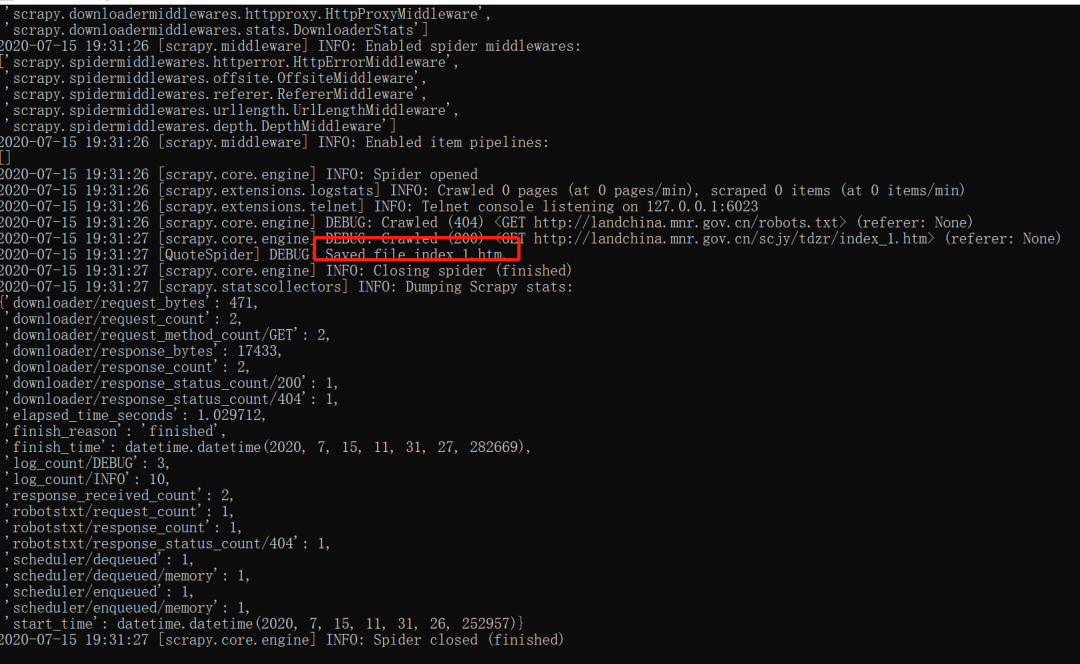
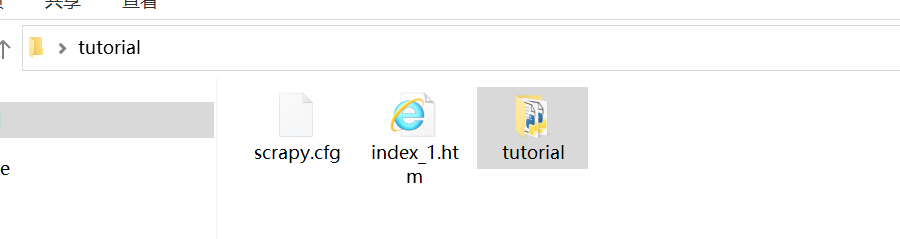
可以在 tutorial 目录下看的 index_1.htm 文件;该文件就是爬取到的内容。
☆
往期精彩
☆
02 Nacos源码编译
03 基于Apache Curator框架的ZooKeeper使用详解
关注我
每天进步一点点

喜欢!在看☟
















 1133
1133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











