








本文是翻译节选,如需要请找原论文
作者:SHILIN HE, Microsoft Research(一作)
日志是由软件源代码中的日志语句生成的半结构化文本。近几十年来,软件日志在许多软件系统的可靠性保证机制中已经成为必要的,因为它们通常是记录软件运行时信息的唯一可用数据。随着现代软件的大规模发展,日志的数量迅速增加。为了使现代软件日志在可靠性工程中得到有效和高效的应用,对日志自动化分析进行了大量的研究。本调查详细介绍了自动化日志分析研究的概况,包括如何自动化和辅助日志语句的编写、如何压缩日志、如何将日志解析为结构化事件模板,以及如何利用日志来检测异常、预测故障和促进诊断。此外,我们调查了发布开源工具包和数据集的工作。基于对最近进展的讨论,我们提出了几个在现实世界和下一代自动化日志分析方面有希望的未来方向。
软件日志被广泛应用于各种可靠性保证任务中,因为它们通常是记录软件运行时信息的唯一可用数据。此外,日志在数据驱动的工业决策中也发挥着不可或缺的作用。通常,日志是由源代码中的日志语句(例如printf(), logger.info())打印的半结构化文本。如下图,日志消息的前几个单词(例如,“Wombat”)是由相应的日志框架(例如,SLF4J)决定的,它们是结构化的。相反,其余的单词(例如“50度”)是非结构化的,因为它们是由开发人员编写来描述特定的系统运行时事件的。

典型的日志分析管理框架。
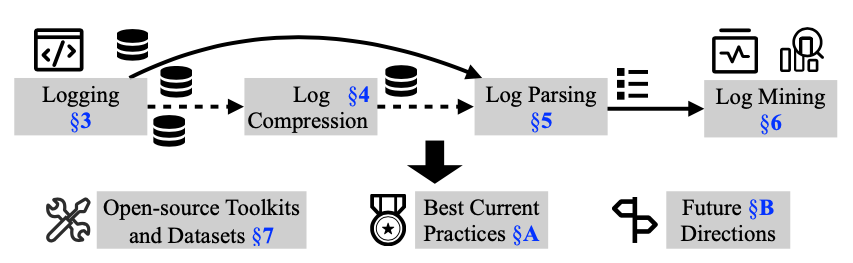
在系统运行过程中,软件日志被收集并使用文件压缩工具包(如WinRAR/zip)作为普通文件进行压缩。此外,开发人员还将收集到的日志用于各种可靠性保证任务(例如,日志挖掘),例如异常检测。 几十年前,这些过程是基于开发人员指定的特定规则。例如,要提取与任务相关的特定信息(例如,线程ID),开发人员需要为自动日志解析设计regex(即正则表达式)规则进行解析。传统的异常检测过程也依赖于人工构建的规则。这些日志分析技术在一开始是有效的,因为大多数广泛使用的软件系统都是小而简单的。
然而,随着现代软件的规模越来越大,结构越来越复杂,传统的基于专门领域知识或手工构建和维护规则的日志分析变得低效和无效。在许多实践中,当同一组的许多高级开发人员共享一些最佳日志记录实践时,大多数新开发人员或来自不同项目的开发人员基于领域知识和特别设计编写日志记录语句。因此,运行时日志的质量在很大程度上是不同的。软件日志的数量迅速增加(例如,50 GB/h)。因此,手工挖掘规则(例如,日志事件模板或异常模式)变得更加困难。随着Web服务和源代码共享平台(如Github)的流行,软件可以由全球数百名开发人员编写。应该维护规则的开发人员通常不知道原始日志记录的目的,这进一步增加了手动维护规则的难度。由于敏捷软件开发概念的广泛采用,新的软件版本通常以短期的方式出现。因此,相应的日志语句也会频繁更新(例如,每个月有数百条新的日志语句),开发人员很难手动更新规则。
为了应对这些挑战,研究者和实践者在最近几十年完成了大量的工作。特别是,从2003年开始,一系列的研究工作致力于从软件日志中自动构建规则和提取关键信息,包括日志解析[A data clustering algorithm for mining patterns from event logs]、异常检测[A data clustering algorithm for mining patterns from event logs]和失败预测[Critical event prediction for proactive management in large-scale computer clusters]的首批工作。此外,同年,Hätönen等[Comprehensive log compression with frequent patterns]提出了第一种日志特定压缩技术。随后,许多实证研究作为自动化测井分析中一些疑难问题的第一步,包括2009年Jiang等[Understanding customer problem troubleshooting from storage system logs]首次对故障诊断进行研究,2012年Yuan等[Characterizing logging practices in open-source software]首次对log实践进行探索,2014年Fu等[Where do developers log? an empirical study on logging practices in industry]首次对log实践进行工业性研究。近年来,机器学习和深度学习算法被最先进(SOTA)的论文广泛采用,如测井实践中的基于深度学习的“what to log”方法[Where shall we log?: studying and suggesting logging locations in code blocks]和异常检测中的Deeplog[DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning]。除了机器学习,并行化在最近的各种论文中也被使用,例如日志压缩中的Logzip[Logzip: Extracting Hidden Structures via Iterative Clustering for Log Compression]和日志解析中的POP[Towards Automated Log Parsing for Large-Scale Log Data Analysis]。
这些跨多个核心方向的自动化日志分析研究极大地提高了软件日志系统使用的有效性和效率。然而,研究方向和最新论文的多样性和丰富性,不可避免地会阻碍非专家想要了解SOTA并提出进一步的改进建议。为了解决这一问题,本文调查了过去23年158篇涉及各种日志分析主题的论文。正在探索的论文主要来自三个相关领域的顶级场景:软件工程(如ICSE)、系统(如SOSP)和网络(如NSDI)。因此,读者可以深入了解SOTA方法的优点和局限性,并对现有的开源工具包和数据集有一个粗略的了解。此外,本文总结的见解和挑战可以帮助从业者理解自动化日志分析技术在实践中的潜在用途,并认识到学术界和工业界在这一领域的差距。
如图所示,我们从以下七个方面介绍了自动化日志分析的关键研究成果,此外,我们将这些出版物按研究重点分为五类:日志记录、日志压缩、日志解析、日志挖掘和实证研究。
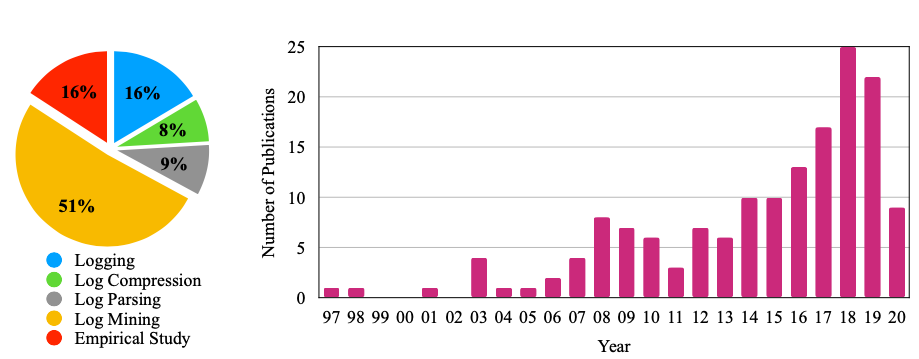
很大一部分(大约一半)的研究工作致力于日志挖掘。原因有两方面:
首先,日志挖掘是一项综合任务,由许多子任务(如异常检测、故障诊断)组成。每个子任务都有巨大的研究探索空间,因此吸引了众多的研究研究;其次,除日志挖掘以外的研究领域相对成熟。此外,由于日志与工业实践的关系更为密切,在过去的几十年里,日志也得到了广泛的研究。此外,许多日志研究任务是实证研究,我们在不同的章节分别进行了讨论。
日志记录
Logging的任务是使用适当的描述和必要的程序变量构造日志语句,并将日志语句插入到源代码中的正确位置。日志记录已经引起了学术界[Industry practices and event logging: assessment of a critical software development process, A large-scale study of failures in high-performance computing systems,Detecting large-scale system problems by mining console logs]和工业界[Studying the characteristics of logging practices in mobile apps: a case study on F-Droid]的广泛关注,因为日志记录是所有后续日志挖掘任务的基本步骤。
日志记录机制和库
日志记录机制:日志机制是由开发人员或给定的软件平台实现的一组日志语句及其激活代码[ndustry practices and event logging: assessment of a critical software development process]。图1显示了两个示例日志语句和程序执行期间收集的日志。每次调用setTemperature方法时,都会执行第3行中的日志记录语句,没有特定的激活代码。第5行的日志记录语句由第4行的激活代码if (temperature.intValue() > 50)控制。根据收集的数据,激活日志语句最广泛采用的编码模式是if (condition) then log error()。
日志库:为了提高灵活性,工业开发人员经常使用日志库[Studying the use of Java logging utilities in the wild,Industry practices and event logging: assessment of a critical software development process],这是一种便于日志记录并提供高级特性(例如,线程安全、日志归档配置和API分离)的软件组件。为此,已经开发了许多开源日志库(如Log4j , SLF4J , AspectJ , spdlog)。
日志记录方法综述:
| 问题 | 方向 | 目标 |
|---|---|---|
| where-to-log | 诊断
性能 | 建议在源代码中适当放置日志语句[Log20: Fully Automated Optimal Placement of Log Printing Statements under Specified Overhead Threshold,Learning to log: helping developers make informed logging decisions,The Game of Twenty Questions: Do You Know Where to Log? Be conservative: enhancing failure diagnosis with proactive logging];研究工业中的logging实践[Where do developers log? an empirical study on logging practices in industry, Studying software logging using topic models ]。
最小化或减少性能开销[Log 2 : a cost-aware logging mechanism for performance diagnosis, Be conservative: enhancing failure diagnosis with proactive logging]。
|
| what-to-log | 诊断
维护
性能 | 增强现有的日志代码以帮助调试[Improving software diagnosability via log enhancement];在日志[Which Variables Should I Log,Which log level should developers choose for a new logging statement, Characterizing the natural language descriptions in software logging statements ]中建议适当的变量和文本描述。
判断一个日志语句在将来是否可能发生变化[ Examining the stability of logging statements];描述和检测重复的日志代码[Dlfinder: characterizing and detecting duplicate logging code smells]。
研究手机应用中登录的性能开销和能量影响[An exploratory study on assessing the energy impact of logging on Android applications];当系统出现异常时,自动修改系统的日志级别[PADLA: a dynamic log level adapter using online phase detection]。 |
| how-to-log | 诊断
维护
性能 | 描述日志代码中的反模式[ Understanding Log Lines Using Development Knowledge];优化logging机制的实现,以促进故障诊断[ Troubleshooting Transiently-Recurring Errors in Production Systems with Blame-Proportional Logging]。
描述并检测日志代码[Guiding log revisions by learning from software evolution history,Characterizing and detecting anti-patterns in the logging code]中的反模式;描述日志语句的维护特征并确定其优先级[Logging library migrations: a case study for the apache software foundation projects];研究logging特征与代码质量的关系[Studying the relationship between logging characteristics and the code quality of platform software];提出新的日志的抽象或编程范式[Aspect-Oriented Programming,The fuzzylog: a partially ordered shared log]。
优化日志代码的编译和执行[NanoLog: a nanosecond scale logging system]。 |
日志压缩
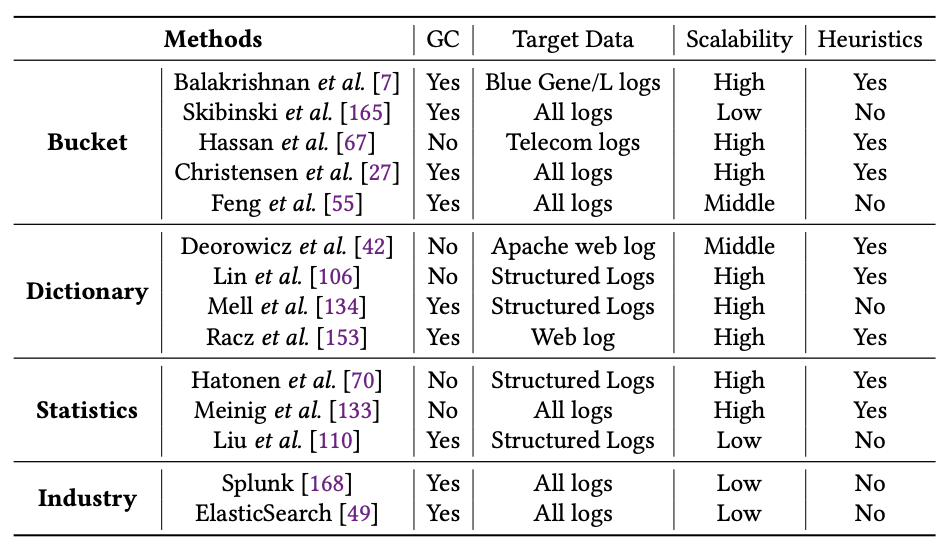
日志解析
日志采集后,日志消息将被输入到不同的下游日志挖掘任务(如异常检测)中进行进一步分析。然而,大多数现有的日志挖掘工具[Identifying impactful service system problems via log analysis,Detecting large-scale system problems by mining console logs]需要结构化输入数据(例如,结构化日志事件列表或矩阵)。因此,自动化日志分析的关键步骤是将半结构化的日志消息解析为结构化的日志事件。
日志消息由消息头和消息内容组成。消息头部由日志记录框架确定,因此相对容易提取,例如详细级别(例如,“信息”)。相比之下,很难从消息内容中提取关键信息,因为它主要是由开发人员用自由格式的自然语言编写的。通常,消息内容包含常量和变量。常量是由开发人员编写的固定文本(例如,“接收到”)并描述系统事件,而变量是携带动态运行时信息的程序变量的值。
离线版本工具:
频繁模式挖掘:SLCT (Simple Logfile Clustering Tool)[A data clustering algorithm for mining patterns from event logs]是第一篇关于日志自动解析的研究论文。SLCT共通过两次,获得关联词。在第一轮中,SLCT统计所有标记的出现次数,并记录下频繁出现的单词。第二遍使用这些频繁词来找出相关的频繁词。最后,对于一个日志消息,如果它包含一个关联频繁词的模式,这些词将被视为常量并用于生成事件模板。
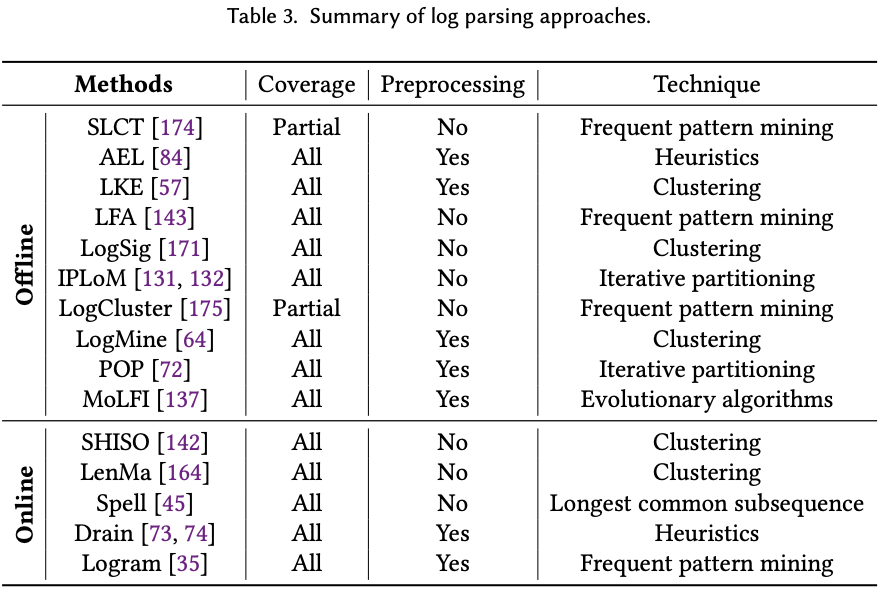
聚类:LogCluster[LogCluster — A data clustering and pattern mining algorithm for event logs]类似于SLCT[A data clustering algorithm for mining patterns from event logs]。不同的是,LogCluster通过聚类算法允许参数的长度可变。因此,与SLCT相比,LogCluster能够更好地处理参数长度灵活的日志消息。例如,“Download Facebook and install”和“Download what App and install”具有相同的事件模板“Download <*> and install”,而参数(即应用程序名称)的长度是灵活的。LKE (Log Key Extraction)[Execution Anomaly Detection in Distributed Systems through Unstructured Log Analysis]是微软公司开发的。LKE算法采用分层聚类算法,采用自定义加权编辑距离度量。此外,利用启发式规则对聚类进行进一步划分。LogSig[LogSig: generating system events from raw textual logs]是比LKE更近的基于聚类的解析器。LogSig没有直接对日志消息进行聚类,而是将每个日志消息转换为一组词对,并基于相应的词对对日志进行聚类。LogMine[ LogMine: fast pattern recognition for log analytics]采用了聚类算法。它在map-reduce框架中实现,以提高效率。
启发式。AEL[Abstracting Execution Logs to Execution Events for Enterprise Applications]使用了一系列专门的启发式规则。例如,对于所有像“word=value”这样的对,AEL将“value”视为一个变量,并用“$v”符号替换它。
进化算法:MoLFI[A search-based approach for accurate identification of log message formats]将日志解析定义为一个多目标优化问题,并提出了一种基于进化算法的方法。
迭代分区方式:IPLoM[Clustering event logs using iterative partitioning]包含三个步骤,并以分层的方式将日志消息分成组。(1)按日志消息长度划分分区。(2)通过标记位置划分。包含唯一单词数量最少的位置是“标记位置”。3)映射分区。利用启发式准则,搜索两个标记位置上的唯一标记集之间的映射关系。POP[Towards Automated Log Parsing for Large-Scale Log Data Analysis]是一个并行日志解析器,它利用分布式计算来加速大规模软件日志的解析。POP可以在7分钟内解析2亿条HDFS日志消息,而大多数解析器(例如LogSig)都无法在合理的时间内终止。
日志挖掘
日志挖掘利用统计、数据挖掘和机器学习技术来自动探索和分析大量日志数据,以收集有意义的模式和有意义的趋势。提取的模式和知识可以指导和促进软件系统的监视、管理和故障排除。
日志挖掘为何流行:
此外,检查软件故障的日志通常需要工程师掌握有关软件的知识。然而,现代软件系统通常由不同工程师开发的多个组件组成,导致产生异构日志,单个工程师无法解决故障。此外,由于现代软件系统的高度复杂性,故障可能源于各种来源的软件和硬件问题。例如软件bug、硬件损坏、操作系统崩溃、服务异常等。此外,通过检查日志及时找到问题的根本原因,高度依赖于工程师的专业知识和经验。然而,这些知识往往没有很好地积累、组织和记录。因此,对自动日志挖掘的复杂方法的需求很高。
日志挖掘流程
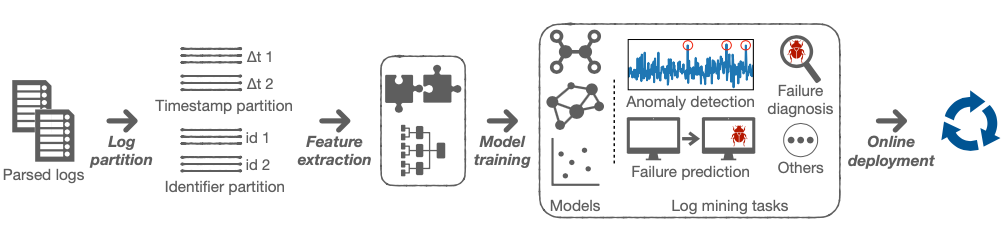
日志区分
现代软件系统通常采用微服务体系结构,并包括在多线程环境中运行的大量模块。不同的微服务或模块经常将它们的执行日志聚合到单个日志文件中,这阻碍了日志挖掘的自动化。为了解决这个问题,应该将交错的日志划分为不同的组,每个组代表单个系统任务的执行。划分后的日志组是构建日志挖掘模型之前进行特征提取的基本单元。
时间戳:它记录每个日志的发生时间,这是许多日志库支持的基本功能,如Log4j。通过正则表达式,可以在日志解析阶段轻松地从原始日志中提取不同格式的时间戳。基于时间戳的日志划分通常采用固定窗口和滑动窗口两种策略。固定窗口具有预定义的窗口大小,这意味着用于拆分按时间顺序排序的日志的时间跨度或时间间隔(例如,30分钟)。滑动窗口是固定窗口的延伸,允许两个连续的固定窗口之间的重叠。滑动窗口具有两个属性,即窗口大小和步长大小。步长表示窗口沿时间轴的转发距离以生成日志分区,通常小于窗口大小。
日志标识符:它是标识系统的一系列相关操作或消息交换的令牌。例如,HDFS日志采用block_id来记录对特定块的操作(如分配、复制和删除)。常见的日志标识包括用户ID、任务/会话/作业ID、变量/组件名称等,可以通过日志解析来提取。与时间戳相比,日志标识是一种更清晰、更明确的日志划分信号。
特征提取:为了自动分析日志,日志分区中的文本日志应该转换为适合机器学习算法的适当格式。通过文献回顾,我们确定了两类基于日志的特征,即数值特征和图形特征。特别是,数值特征是日志分析领域中广泛使用的主流特征。数值特征:它表示日志的统计属性,包括可以直接从日志中提取的数值和分类字段。它将对数分区的信息传递到数值向量表示中。特别是,现有的大多数工作所采用的数值特征都是相似的,并具有一些典型的形式。在下文中,我们简要总结了四种类型的此类功能。
- 日志事件序列:记录系统活动的日志事件序列。具体地,每个元素可以简单地是例如通过word2vec算法[Distributed Representations of Words and Phrases and their Compositionality]学习的日志事件ID或日志嵌入向量。
- 日志事件计数向量:记录日志分区中日志事件发生情况的特征向量,每个特征表示一个日志事件类型,该值统计出现的次数。·参数值向量:记录日志中出现的参数(即日志解析提取的变量)的值的向量。
- 特殊功能:从日志中提取的一组相关且具有代表性的功能,这些功能是使用对象软件系统和问题上下文的领域知识定义的。例如,Zhou[Latent error prediction and fault localization for microservice applications by learning from system trace logs]从系统跟踪日志中手动识别各种类型的功能,包括配置(例如,内存限制、CPU限制)、资源(例如,内存消耗、CPU消耗)等。这些功能描述系统的典型健康状态。
图特征:为了利用日志发现系统组件和事件之间的分层和顺序关系(例如,依赖性和同现性),图特征通常产生表征系统行为的有向图模型,例如,进程的执行路径。图特性是各种下游日志挖掘任务(如监视[CloudSeer: Workflow Monitoring of Cloud Infrastructures via Interleaved Logs]和诊断[Using finite-state models for log differencing,Statistical log differencing,Anomaly Detection Using Program Control Flow Graph Mining From Execution Logs])的基础。例如,基于日志的行为差异[Experience Report: Log-Based Behavioral Differencing]可以识别从系统正常行为派生的系统执行,这在系统演化、测试和安全方面有各种应用[Statistical log differencing]。在这一部分中,我们简要介绍了现有的用于图特征提取的算法,这些算法大致可以分为两类。
第一工作利用日志中标识的对象,例如进程ID和系统组件名称,来构造系统状态监控的图。由于对象往往表现出复杂的层次关系,因此通常需要更复杂的算法来划分日志。例如,为了表示日志中的执行结构和对象层次,Zhao等[Non-intrusive performance profiling for entire software stacks based on the flow reconstruction principle]考虑了不同对象之间1:1、1:n和n:m的映射关系,构造了一个堆栈结构图。为了解决唯一标识符常常不可用的问题,Yu等人[CloudSeer: Workflow Monitoring of Cloud Infrastructures via Interleaved Logs]提出基于一组通用标识符对交错日志进行分组。每个日志包含一个标识符集,它作为图的状态节点,通过检查不同标识符集的子集和超集关系来添加转换。
另一项工作利用日志事件的基本统计分布,例如日志事件的顺序、相关日志事件的时间和空间局部性,来构建用于系统行为分析的各种图。特别是,一些工作旨在从日志跟踪中恢复准确的行为模型。因此,日志分区要求标识符能将与程序执行相关联的一组事件绑定在一起。例如,Amar等人[Using finite-state models for log differencing]提出了k-Tail的两种变种,即2KDiff和nKDiff,以构造用于对数差分的有限状态机(FSM)。2KDiff计算并突出显示包含一组分区日志的两个日志文件之间的差异;而nKDiff能够一次对多个日志文件进行比较。后来,包等人又提出了自己的看法[Statistical log differencing]扩展了他们的工作,提出了s2KDiff和snKDiff,它们考虑了不同行为的频率。Busany等人[Behavioral log analysis with statistical guarantees]通过从日志中提取有限状态自动机(FSA)模型或时态属性,研究了现有行为日志分析算法的可扩展性问题。我们建议读者参考这篇论文以了解更多相关研究。
然而,如前所述,每个执行跟踪的唯一标识符并不总是可用的,尤其是在分布式应用程序和系统中。因此,一些工作试图使用交错日志来挖掘行为模型。例如,Lou等人[Mining program workflow from interleaved traces]使用统计推理来学习日志事件之间的时间依赖关系,这一点也在包括[Leveraging existing instrumentation to automatically infer invariant-constrained models]的类似工作中进行了研究。Nandi等人[Anomaly Detection Using Program Control Flow Graph Mining From Execution Logs]计算最近邻组,以更准确地捕捉日志事件的时间共现。由此得到的模型是一个跨越分布式组件的程序控制流图(CFG)。具体地,使用Jaccard相似性或贝叶斯条件概率方法来计算两个分量之间的相关性。Du等人[DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning]描述了通过FSA模型捕获服务执行的两种方法。第一种方法利用训练好的日志异常检测模型,该模型的预测编码了任务执行的底层路径。第二种方法建立一个矩阵,其中每个条目表示在预定距离内一起出现的两个对数关键字的共现概率。
模型训练:在这个过程中,根据手头的问题选择合适的算法,并基于提取的特征训练选定的模型。已经提出了各种机器学习算法,我们将在以下部分中留下更多细节。此步骤通常以离线方式进行。此外,各种日志挖掘任务的一个基本假设是,大多数日志应该表现出符合系统正常行为的模式。例如,在异常检测中,训练不同的模型从不同的角度捕捉各种模式,并用于检测缺乏期望属性的异常。
在线部署:一旦模型被离线训练,它就可以被部署到现实世界的软件系统中,以执行各种日志挖掘任务。例如,可以将异常检测模型集成到软件产品中,以检测恶意系统行为并实时发出警报。为了应对系统升级引起的模式变化的挑战,几项研究[Deeplog,]支持在线更新先前训练的模型,以适应前所未有的日志模式。
异常检测
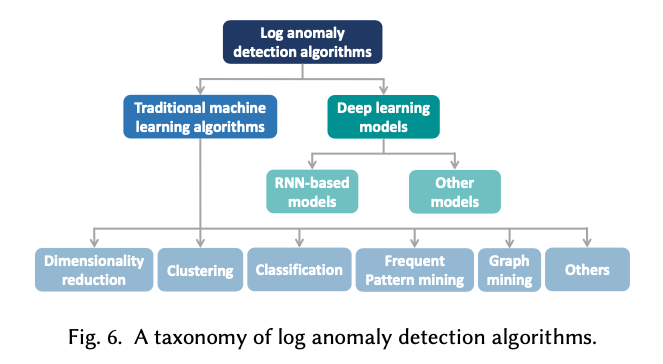
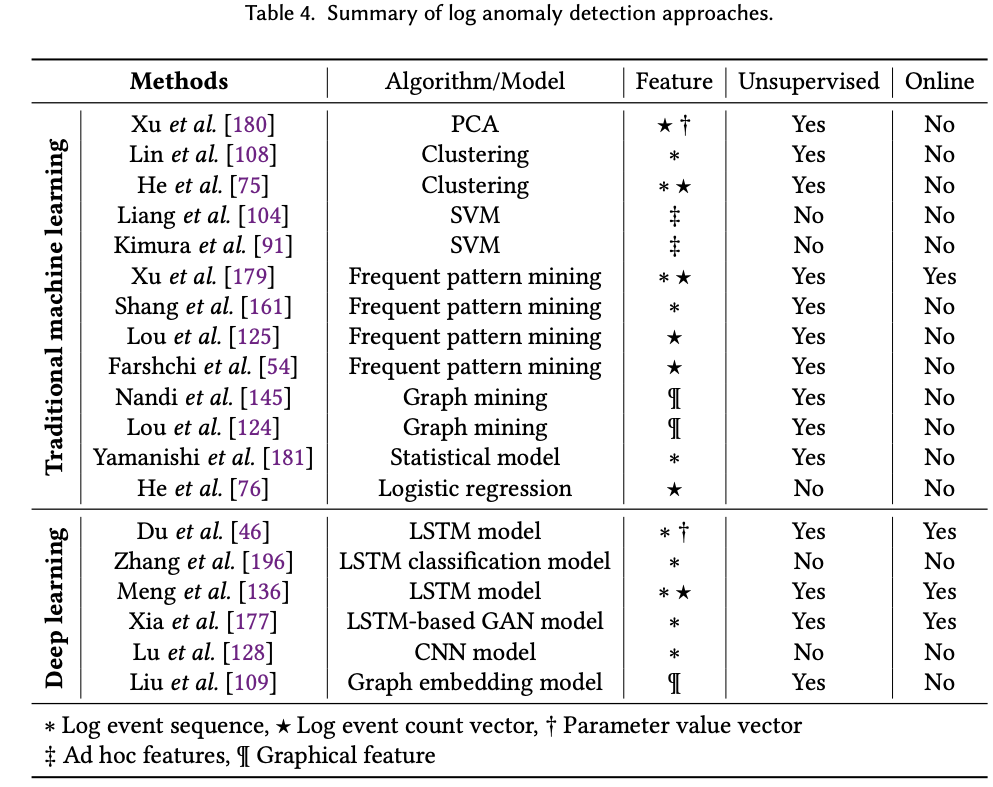
问题程序化:异常检测的任务是识别不符合预期行为的系统异常模式的日志数据。典型的异常通常表明软件系统中可能出现的错误、故障或故障。在本节中,我们将根据这一领域的研究方法对现有的研究工作进行详细阐述。如图6所示,我们将这些方法分为两大类:传统的机器学习算法和深度学习模型。下表列出了调查的方法以及几个有趣的属性。具体来说,我们总结了一种方法使用的算法/模型和特征,以及每种方法是否无监督和。特别是,无监督方法不需要对模型训练进行标签;
传统机器学习算法:
传统的机器学习算法通常在实践者明确提供的特征之上执行,例如日志事件计数向量。特别的是,异常检测任务可以形式化为不同的类型,并使用不同的算法来解决,如聚类、分类、回归等。
降维算法:它将高维数据转化为低维表示,使原始数据的某些有意义的属性在低维空间中得以保留。主成分分析(PCA)是这类算法中最流行的一种。通过将数据点投影到前k个主成分上,如果投影距离大于阈值,就可以识别出异常。PCA首先由Xu等人[Detecting large-scale system problems by mining console logs]应用于从控制台日志中挖掘系统问题。特别地,构造了日志事件计数向量和参数值向量,并输入到PCA模型中进行异常检测。
聚类算法:基于聚类的异常检测是一种无监督的方法,它将基于日志的特征向量分组到不同的聚类中,使同一聚类中的向量更加相似(并且与其他聚类中的向量尽可能地不相似)。包含很少数据实例的集群往往是异常的。例如,Lin等人[Log clustering based problem identification for online service systems]提出了LogCluster,它将日志序列聚类,并推荐一个具有代表性的序列,以帮助开发人员快速识别潜在的问题。通过计算聚类质心来选择具有代表性的序列。此外,He等人[Identifying impactful service system problems via log analysis]提出了Log3C框架,将系统kpi纳入对服务系统有影响的问题的识别中。特别是,他们提出了一种级联聚类算法,可以快速地将大量的日志序列分组。他们最后使用多元线性回归模型来确定导致KPI下降的影响问题。
分类算法:基于分类算法的异常检测将对数划分分为正常和异常两种类型,其中异常实例是根据某些统计性质从正常实例中派生出来的。支持向量机(SVM)是一种常用的用于日志异常检测的监督分类方法。在[Failure Prediction in IBM BlueGene/L Event Logs]中,Liang等人通过识别六种类型的特征,包括时间窗口中的事件数、累计事件数等,对日志分区进行向量化。基于这些特征,他们应用四种分类模型进行异常检测。包括支持向量机和最近邻预测器。此外,Kimura等人[Proactive failure detection learning generation patterns of large-scale network logs]基于日志的频率、周期性、突发性以及与维护和故障的相关性等特征,提出了一种主动故障检测的日志分析方法。采用高斯核支持向量机模型进行故障检测。
频繁模式挖掘算法:它的目的是在一个日志数据集中发现最频繁的项目集和子序列,以表征系统的正常行为。不符合频繁模式的数据实例将被报告为异常。特定日志事件的存在和日志事件的顺序都可以构成模式。例如,Xu等人[Online System Problem Detection by Mining Patterns of Console Logs]挖掘了经常同时出现的日志消息集,以检测在线设置中的异常执行跟踪。与离线方法相比,在线模式匹配可以快速识别良性的系统执行,从而在准确性和效率之间取得平衡。类似地,Lim等人[A log mining approach to failure analysis of enterprise telephony systems]搜索通常与不同失败类型相关的项目集。这样的项目集可以帮助开发人员预测和描述失败。其他方法通过日志事件挖掘顺序模式来发现异常或bug[CloudRaid: hunting concurrency bugs in the cloud via log-mining]。
此外,Lou等人[Mining invariants from console logs for system problem detection]首先考虑在日志消息中挖掘不变量来进行系统异常检测。推导出两种不同日志消息数量之间关系的不变量:(1)文本日志中描述等价关系的不变量;(2)不变量为线性方程,即线性无关关系。Farshchi等人[Experience report: Anomaly detection of cloud application operations using log and cloud metric correlation analysis]提出了一种类似的方法,挖掘日志事件和云系统度量变化之间的相关性和因果关系。具体来说,他们采用了一种基于回归的方法来学习一组对线性关系建模的断言。然后通过监视日志事件流并检查度量是否符合断言来执行异常检测。
图挖掘。这组方法主要使用图特征,即各种图形模型(第6.2节)来识别复杂系统的行为变化,这些变化可用于及早发现异常并允许采取主动行动进行纠正。
其他的统计模型。还有一些算法不属于上述类别。例如,Yamanishi等人采用混合隐藏马尔可夫模型来监测syslog行为。该模型采用在线折扣学习算法,通过动态选择最优混合组分的数量来学习。异常分数的分配使用通用测试统计,其阈值可以动态优化。He等采用逻辑回归模型检测异常。他们采用事件计数向量作为特征,用一组标记数据对模型进行训练。当逻辑斯蒂函数估计的概率大于0.5时,测试实例被声明为异常。Nagaraj等人通过查找一组相互关联的日志事件发生和在日志集之间显示出最大分歧的变量值,诊断了大规模分布式系统的性能问题。具体来说,他们首先根据某些性能指标(例如,运行时)将日志分成两组。然后,他们通过t-检验推荐了对性能差异贡献最大的日志事件或状态变量。
深度学习模型
深度学习使用多层体系结构(即神经网络)来逐步从输入中提取特征,其中不同的层处理不同层次的特征提取。由于神经网络在复杂关系建模方面的卓越能力,它在基于日志的异常检测中得到了广泛的应用。在文献中,我们观察到很大一部分论文采用了递归神经网络(RNN)模型及其变体。因此,我们将深度学习模型分为基于RNN的模型和其他模型
基于RNN的模型 属于RNN家族的模型(如LSTM模型和GRU模型)通常用于自动学习日志数据中的序列模式。当日志模式偏离模型的预测时,就会出现异常。例如,Du等人提出了DeepLog,它利用LSTM模型通过预测给定一系列先前日志事件的下一个日志事件来学习系统的正常执行模式。但是,某些异常可能表现为参数值不规律,而不是偏离正常执行路径。因此,DeepLog还应用了LSTM模型来检查参数值向量的有效性。许多现有的研究假设日志数据随着时间的推移是稳定的,并且不同的日志事件集是固定的和已知的。然而,Zhang et al.[Robust log-based anomaly detection on unstable log data]发现日志数据通常包含以前未见过的日志事件或日志序列,表现出日志不稳定。为了解决这一问题,他们提出了LogRobust,通过利用现有的词向量来提取日志事件的语义信息,然后应用双向LSTM模型来检测异常。
在获取日志的语义方面,Meng et al.[LogAnomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs]发现现有的word2vec模型不能很好地区分同义词和反义词。因此,他们训练了一个词嵌入模型来显式地考虑同义词和反义词的信息。孟等人[A Semantic-aware Representation Framework for Online Log Analysis]通过提出一种面向在线日志分析的语义感知表示框架,进一步扩展了他们的工作。对特定于日志的词嵌入和词汇表外(OOV)问题都进行了讨论。最近,Zuo et al.[An Intelligent Anomaly Detection Scheme for Micro-Services Architectures With Temporal and Spatial Data Analysis]结合事务级主题建模学习log embeding,其中,事务是在时间窗口中顺序发生的一组日志。为了解决标签不足的问题,Chen等人[Cross-system log anomaly detection for software systems]应用迁移学习在两个软件系统之间共享异常知识。具体地说,他们首先在具有足够异常标签的数据上训练LSTM模型来提取序列日志特征,然后将这些特征馈送到完全连通的层中进行异常分类。接下来,使用来自另一个标签有限的系统的日志对LSTM模型进行微调,而全连接层是固定的。
其他深度学习模型 除了基于RNN的模型,其他模型体系结构在检测日志异常方面也发挥了作用。例如,夏等人[LogGAN: a Log-level Generative Adversarial Network for Anomaly Detection using Permutation Event Modeling]提出了一种基于LSTM的生成性对抗网络LogGAN。像所有GAN风格的模型一样,LogGAN包括一个生成器和一个鉴别器。生成器试图捕获真实训练数据的分布,并合成可信的例子;而鉴别器试图从真实和合成的数据中区分虚假实例。探讨了卷积神经网络(CNN)用于异常检测的可行性。具体地说,Lu等人[Detecting Anomaly in Big Data System Logs Using Convolutional Neural Network]首先利用词嵌入技术将日志编码成二维特征矩阵,然后在此基础上应用具有不同过滤器的CNN模型进行异常检测。刘等人[Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise]提出了一种基于图嵌入的网络威胁检测方法log2vec。具体地说,他们首先使用启发式规则将日志转换为异构图,然后通过图表示学习方法学习每个日志条目的嵌入。基于嵌入向量,日志被分组成簇,其大小小于阈值将被报告为恶意。
故障预测
问题公式化: 异常检测的目的是检测可能或不可能导致故障的异常状态或意外行为模式。与此不同的是,故障预测尝试主动生成早期警告,以防止服务器故障,这通常会导致不可恢复的状态。异常检测和故障预测的目的和作用不同,但两者都很重要。因此,研究失效预测技术对可靠性工程具有重要意义。一般情况下,当软件系统偏离了所要求的系统功能[Dependable computing: concepts, limits, challenges]时,就会发生故障,并且通常会出现人类可感知的症状。该故障可能会导致意想不到的结果和用户不满,特别是对于大型软件系统。传统的故障管理方法(如异常检测)大多是被动的,在故障发生后才进行处理。相反,故障预测的目的是在故障发生前主动预测故障。一种常见的做法是利用有价值的日志来主动预测失败。例如,在[PreFix: Switch Failure Prediction in Datacenter Networks]中,数据中心网络中的交换机故障是根据当前状态和精心策划的历史硬件故障案例来预测的。通常,预测模型的输入数据是系统日志,它记录了系统的状态、配置的变化、运行维护等。
根据故障来源的不同,故障预测主要可以分为两种场景:a)同构系统(如高性能计算(HPC)系统)的独立故障预测。现有的大多数方法都集中在如何利用顺序信息来预测单个组件的故障,即基于顺序的方法。b)预测异构设备或组件集合导致的中断,这在大规模云系统中广泛存在。主流的方法倾向于探索多个异构组件之间的关系中的有用线索,并通过关系挖掘算法进行预测。
故障诊断
问题透出:与通常形式化的分类任务异常检测和故障预测不同,故障诊断的目标是识别导致影响最终用户的故障的根本原因。它往往与根本原因分析密切相关。具体来说,虽然异常检测和故障预测可以准确地确定问题是否已经发生或将会发生,但检测到问题或故障与消除之间存在着巨大的差距。要彻底解决这些问题,故障诊断是至关重要的一步,但诊断过程是出了名的昂贵和低效。据报道,故障诊断花费超过1000亿美元,开发人员将超过一半的时间用于调试。按照[Dependable computing: concepts, limits, challenges中定义的错误、故障和失败的概念,故障诊断旨在识别导致软件系统中用户感知损害的故障。在广泛的故障诊断领域,基于日志的故障诊断现在是软件开发人员的标准实践。然而,故障诊断非常具有挑战性。现代软件系统的复杂性迅速增长,不同的服务、软件和硬件紧密耦合。错误、故障和人类观察到的症状之间的关系过于复杂,无法正确、有效地加以区分。此外,随着软件系统越来越成熟,故障越来越难以检测和诊断,从可察觉的软件功能问题到不可察觉的问题[Failure Diagnosis of Complex Systems],例如:,性能问题[Performance debugging for distributed systems of black boxes,Toward Fine-Grained, Unsupervised, Scalable Performance Diagnosis for Production Cloud Computing Systems,Comprehending performance from real-world execution traces: a device-driver case]。
为了应对这些挑战,近几十年来,自动化诊断过程的技术得到了广泛的发展,例如,使用信息日志[Diagnosing the root-causes of failures from cluster log files]。Jiang等人[83]在现实案例中首次提供了基于日志的问题故障排除的特征研究之一。他们得出的结论是,问题排除既耗时又具有挑战性,而日志可以极大地促进这一点。此外,他们呼吁工程师采用自动化方法来加快问题解决的时间,这也是本次调查的重点。同样,Zhou等人[201]实证研究了微服务系统中的故障和调试实践。结果表明,适当的跟踪和可视化技术可以提高诊断效率,这也提示了对智能化日志分析的强烈需求。其他实证研究包括使用高性能计算(HPC)系统[48]、云管理系统[34]、web服务器[78]和工业空中交通管制系统[30]中的日志来理解故障。
在本节中,我们回顾了基于日志的自动故障诊断的最新工作。特别是,这些研究主要集中在故障诊断负担较重的大型软件系统,如通用分布式系统、存储系统、大数据系统、微服务等。由于特性和功能可能不同,这些系统表现出不同的故障行为。然而,故障诊断的总体方法仍然共享类似的技术,可以分为四类,即,执行回放、基于模型、基于统计和基于检索的方法。也有利用轨迹诊断硬件故障的研究(如[Trace-based microarchitecture-level diagnosis of permanent hardware faults]),但不在本研究范围内。
执行回放的方法:传统的基于规则的方法严重依赖一组预定义规则(例如,以“if-then”格式)从专家知识中诊断故障。然而,这些方法不能很好地推广到规则中不包括的未见故障。
基于模型的方法:基于模型的方法利用日志为软件系统构建参考模型(例如,执行路径),然后检查哪些日志事件违反了参考模型。简而言之,它为正常的软件系统执行建立标准,并通过检测可能的不一致来诊断失败。
统计数据的方法:由于软件系统生成日志来记录正常和异常的执行情况,因此可以直观地使用一些统计技术(例如,统计分布、相关分析)来捕获日志和随之而来的失败之间的关系。
摘要方法:在实践中,以前发生的故障是有价值的,因为它们可以帮助开发人员更好地诊断新发生的故障。如名称所示,基于检索的方法在知识库中检索类似的失败,知识库由历史失败组成,或者由测试环境中注入的错误填充。
同样,CAM[What Causes My Test Alarm? Automatic Cause Analysis for Test Alarms in System and Integration Testing]在系统测试和集成测试中对测试告警的原因分析也采用了同样的思路。通过词频逆文档频率(TF-IDF)提取测试日志项,利用K近邻(KNN)算法寻找相似属性向量,实现故障匹配。
其他log挖掘
还有其他有价值的主题来扩展日志挖掘文献。在本节中,我们主要介绍两个可靠性工程任务:基于规范的挖掘和基于日志的软件测试。
基于规范的挖掘。规范挖掘是从程序执行跟踪中提取规范(例如,程序不变量)的任务。典型规范对程序执行的顺序(排序约束)和程序值(值约束)施加约束[Mining modal scenario-based specifications from execution traces of reactive systems]。这样的规范在系统理解、验证和演化中扮演着重要的角色。
基于log的软件测试:基于日志的软件测试旨在通过生成的日志数据来激发被测试软件的整体工作流程。许多现有的工作通过提出各种基于状态机的形式来解决这个问题,类似于6.2节中介绍的技术。[Testing using log file analysis: tools, methods, and issues]的一项开创性工作讨论了使用正式日志分析器来提高软件可靠性的可行性。大多数基于日志的测试方法利用来自日志文件的线索来提高测试的覆盖率或完整性,Chen等人设计了一个名为LogCoCo的框架[An automated approach to estimating code coverage measures via execution logs],使用现成的执行日志来评估代码覆盖率。Chen等人[An experience report of generating load tests using log-recovered workloads at varying granularities of user behaviour]通过从大规模系统中提取具有代表性的用户行为,推导出状态机框架来进行工作量测试。Cohen等人[Have We Seen Enough Traces? (T)]提出了一个称为日志置信度的概念,用来评估任何基于日志的动态规范挖掘任务的完整性。
开源工具包和数据集
近年来,对日志自动分析的研究越来越多。与此同时,许多日志管理工具已经开发出来,以促进实际工业部署。在本节中,我们将回顾用于自动化日志分析的现有开源工具和数据集。为了选择合适的工具,我们定义了以下标准:首先,我们没有考虑商业测井分析工具,如Splunk[www.splunk.com]和Loggly [www.loggly.com];其次,所选择的工具应涵盖本文中提出的多个测井分析阶段。仔细搜索之后,我们整理了一个开源日志分析工具包列表,如表所示。这些日志分析工具包括:GrayLog、GoAccess、Fluentd、Logstash、Logalyze、Prometheus、Syslog-ng和LogPAI。通常,这些工具支持日志收集、搜索、路由、解析、可视化、警报和自动化分析等关键特性。在这些工具中,LogPAI是一个基于纯研究成果的开源项目,而其他工具则打包为开源企业产品。此外,大多数现有工具都专注于日志挖掘(例如,日志解析)之前的阶段,并将结果(例如,可视化)呈现给开发人员进行手动分析。特别是LogPAI提供了一组自动化的日志分析工具,如日志解析和异常检测。

除了开源工具包,从各种软件系统收集的大量日志数据集也可用于学术界的研究研究。表5显示了公共日志数据集及其描述。Loghub[Loghub: A Large Collection of System Log Datasets towards Automated Log Analytics.]维护着大量的日志收集,可以自由地用于研究目的。一些日志数据集是以前研究中发布的生产数据,而其他数据集是在实验室环境中收集的。另一项研究[How Bad Can a Bug Get? An Empirical Analysis of Software Failures in the OpenStack Cloud Computing Platform]提出了在OpenStack云管理系统中注入故障产生的错误日志。计算机故障数据存储库(CFDR)主要关注各种大型生产系统中的组件故障日志。除了这些日志数据集之外,还有为其他目的收集的日志,比如安全和web搜索。SecRepo是一个精心策划的安全数据列表,如恶意软件和系统日志。EDGAR数据集包含Apache日志,通过互联网搜索记录用户访问统计数据。
结论
近年来,原木分析技术蓬勃发展。鉴于软件日志在可靠性工程中的重要性,对高效、有效的日志分析做出了大量的努力。这个调查主要探讨了自动日志分析框架中的四个主要步骤:日志记录、日志压缩、日志解析和日志挖掘。此外,我们还介绍了可用的开源工具包和数据集。我们的文章让外来者进入这个有前途的实用领域,让专家填补他们知识背景的空白。基于对这些最新进展的调查,我们提出了新的见解,并讨论了未来的几个方向,包括如何使自动化日志分析在现代敏捷和分布式开发风格下更加可行,以及下一代日志分析框架的概念。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









