







大众点评商家信息爬取
首页信息:http://www.dianping.com/
我是按照城市----商家出售的商品类型----分页----商家----爬取
城市:
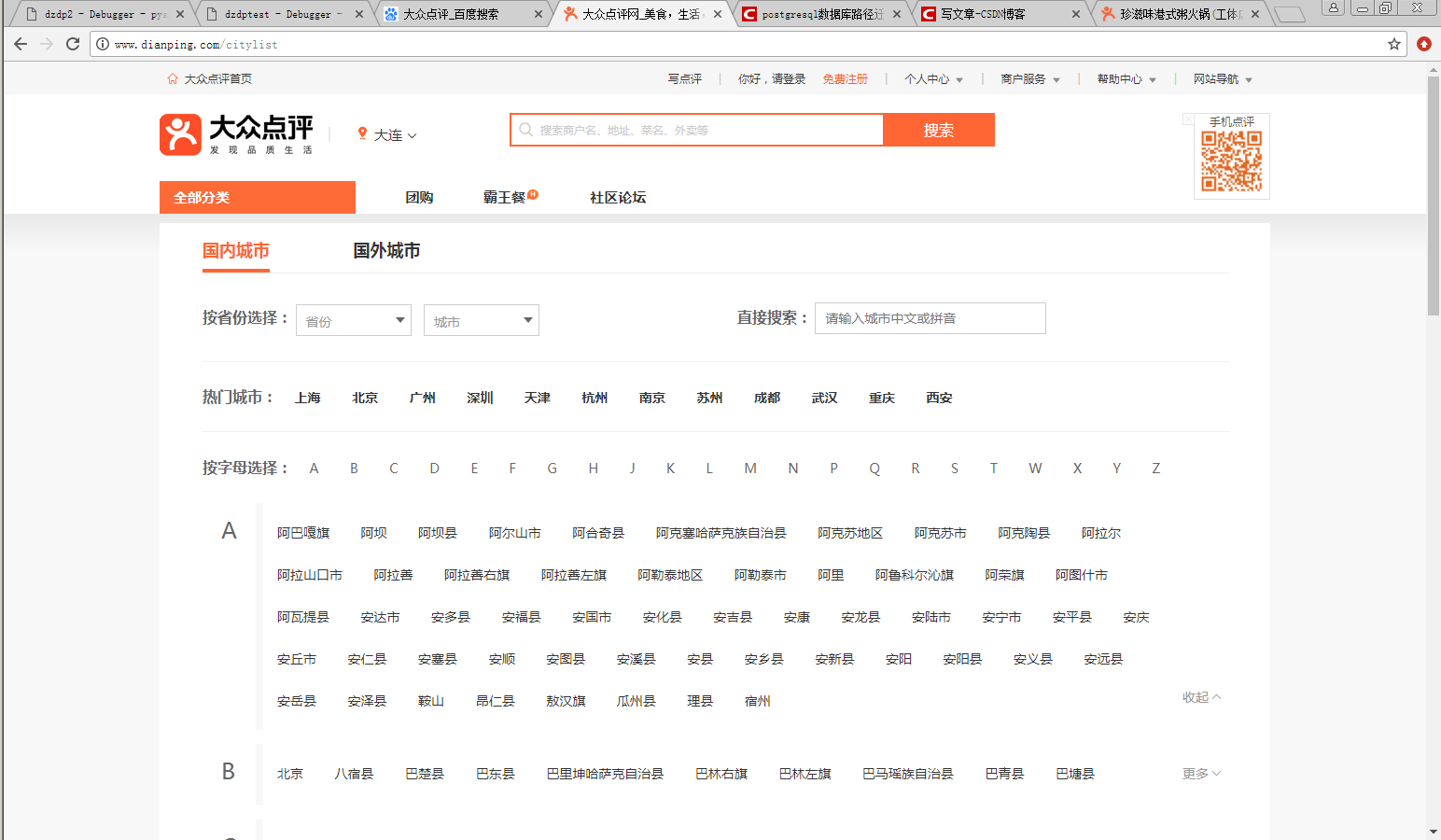
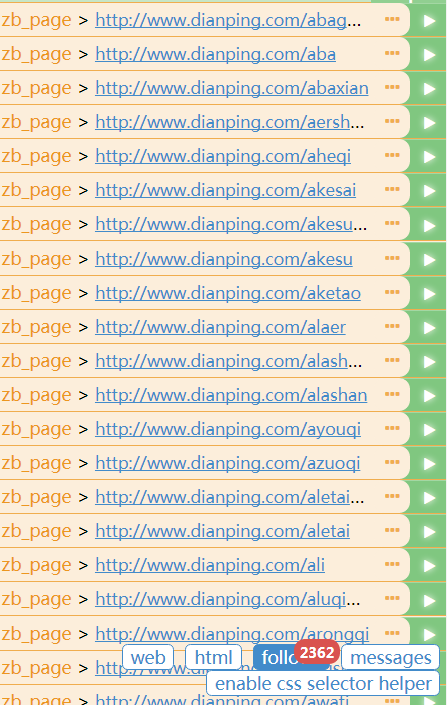
出售商品类型:

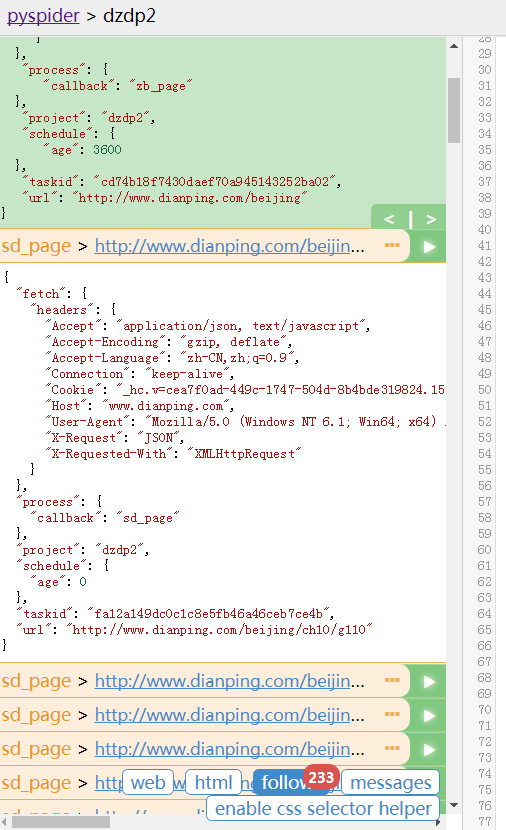
分页:(应该是反爬,所以最多只能看到50页的内容,但能按照现在的规则爬取,我估算了一下应该能有千万左右的商家数据)
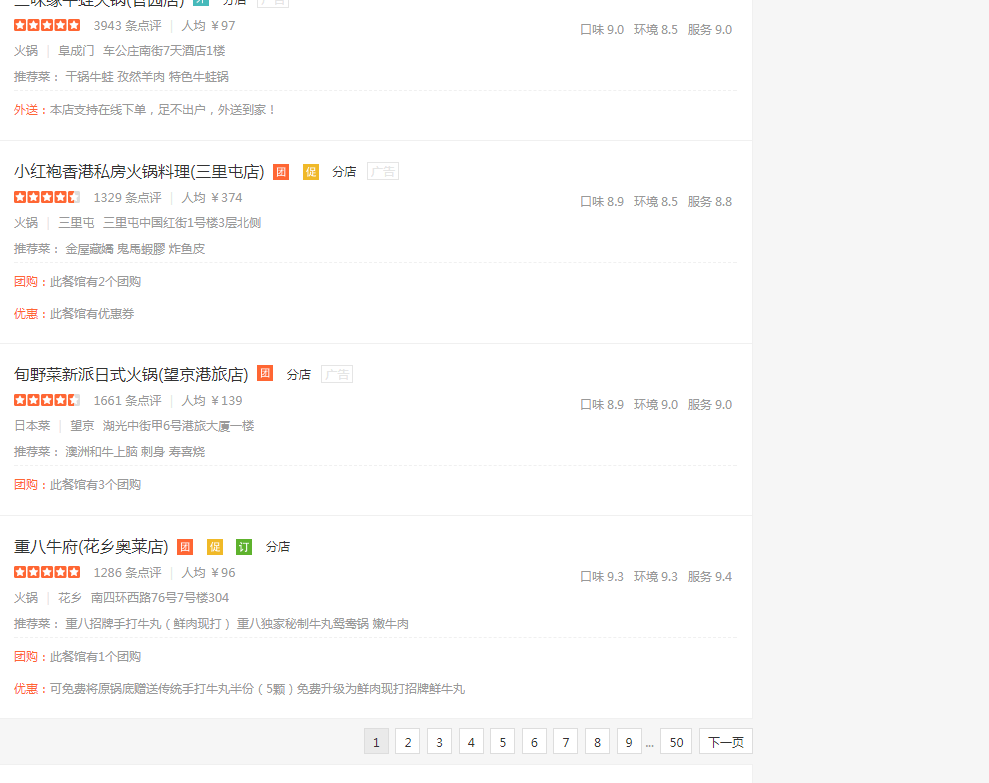
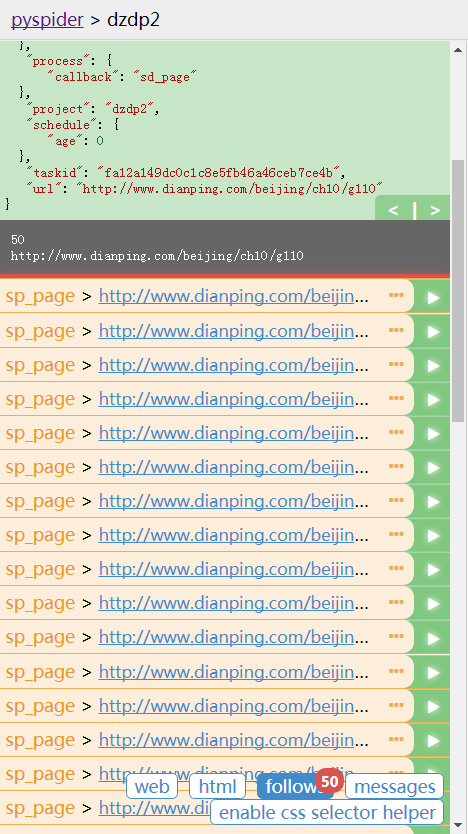
商家:
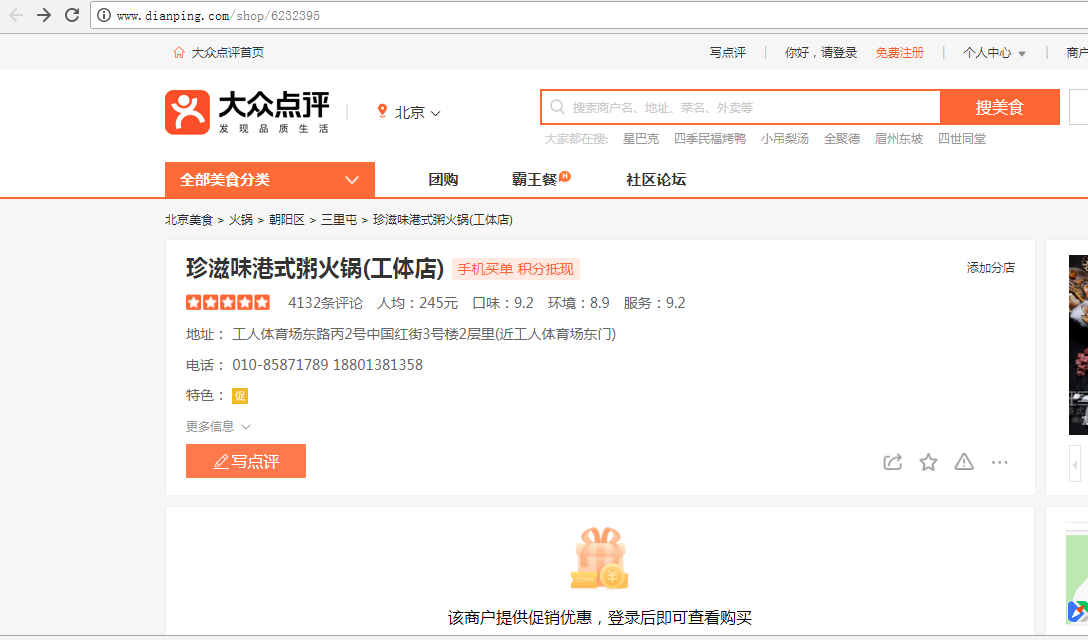
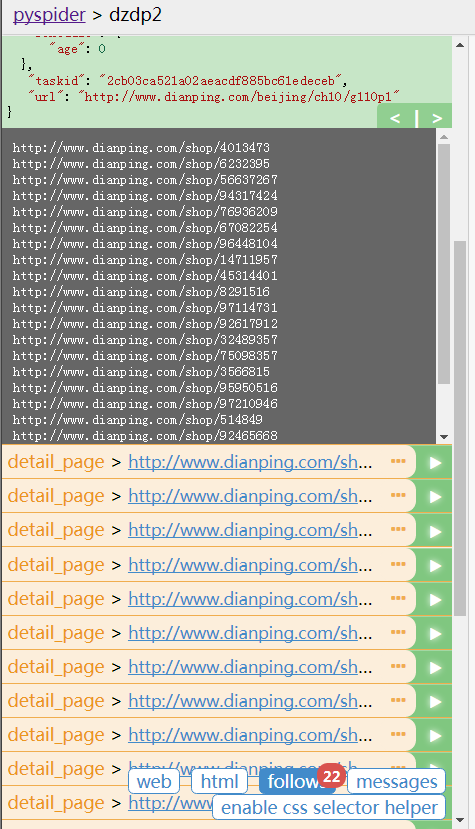
不太会语言描述,但上面就是大致的思路0.0
下面就是代码了(上面的导包有一部分是我往postgresql存数据写的,代码里也有一部分,但不影响正常执行,想试一下存数据的可以直接用,把return注了,把最下面的sql解了就ok)
from pyspider.libs.base_handler import *
import json
import re
from abc import abstractclassmethod
import psycopg2
class Handler(BaseHandler):
crawl_config = {
'headers': {
'Accept':'application/json, text/javascript',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie':'_hc.v=cea7f0ad-449c-1747-504d-8b4bde319824.1519608303; s_ViewType=10; cy=19; cye=dalian; __utma=1.848624062.1520491806.1520491806.1520491806.1; __utmc=1; __utmz=1.1520491806.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmb=1.9.10.1520491806',
'Host':'www.dianping.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'X-Request':'JSON',
'X-Requested-With':'XMLHttpRequest'
}
}
@every(minutes=1 * 30)
def on_start(self):
self.conn = psycopg2.connect(dbname="postgres", user="postgres",password="root", host="127.0.0.1", port="5432")
self.conn.autocommit = True
print("已打开数据库链接")
self.crawl('http://www.dianping.com/citylist',callback=self.cs_page)
def on_finished(self):
if hasattr(self, 'conn'):
self.conn.close()
print("数据库链接已关闭!")
@config(age=1 * 1 * 60 * 60)
def cs_page(self, response):
for each in response.doc('#main > div.main-citylist > ul > li > div.terms > div > a').items():
if re.match("http://www\.dianping\.com(/[0-9a-zA-Z]+){1}",each.attr.href):
self.crawl(each.attr.href, callback=self.zb_page)
@config(age=1 * 1 * 60 * 60)
def zb_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://www\.dianping\.com(/[0-9a-zA-Z]+){1}/ch\d+/g\d+",each.attr.href):
self.crawl(each.attr.href, callback=self.sd_page)
#获取分页数据
@config(age=0)
def sd_page(self, response):
#获取总页数
page_count = response.doc('.PageLink').text().split(' ')[-1]
print(page_count)
page_now = 1
shopurl = response.url
print(shopurl)
#获取每页的链接
if page_count:
while(page_now <= int(page_count)):
url = shopurl+'p'+str(page_now)
#print(url)
page_now = page_now+1
self.crawl(url, callback=self.sp_page)
else:
page_count = 1
self.crawl(shopurl, callback=self.sp_page)
#拿到每页店铺链接
@config(age=0)
def sp_page(self, response):
for each in response.doc('#shop-all-list > ul > li > div.txt > div.tit > a').items():
if re.match("http://www\.dianping\.com/shop/[0-9]+",each.attr.href):
print(each.attr.href)
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return{
"dzdp_url" : response.url,
"dzdp_dpmc" : response.doc('#basic-info > h1').text().split('\n')[0],
"dzdp_rjxf":response.doc('#avgPriceTitle').text(),
"dzdp_pls" : response.doc('#reviewCount').text(),
"dzdp_dz" : response.doc('#basic-info > div.expand-info.address > span.item').text(),
"dzdp_pf" : response.doc('#comment_score > span').text(),
"dzdp_dh" : response.doc('#basic-info > p > span.item').text(),
}
#dzdp_id = self.task['taskid']
#dzdp_url = response.url
#if not hasattr(self, 'conn'):
#self.conn = psycopg2.connect(dbname="postgres", user="postgres",password="root", host="127.0.0.1", port="5432")
#self.conn.autocommit = True
#print("已重新获取数据库链接")
#cursor = self.conn.cursor()
#sql = "INSERT INTO dzdp(dzdp_id,dzdp_url,dzdp_dpmc,dzdp_time,dzdp_rjxf,dzdp_pls,dzdp_dz,dzdp_pf,dzdp_dh) VALUES('" + dzdp_id + "','" + dzdp_url + "','" + dzdp_dpmc + "',now(),'" + dzdp_rjxf + "','" + dzdp_pls + "','"+ dzdp_dz + "','" + dzdp_pf + "','" + dzdp_dh + "');"
#print(sql)
#cursor.execute(sql)
#cursor.close()
#print("数据保存成功")
以前写的了,没登录cookie,没解决多次访问验证码,没写代理IP池,也没异步(所以没有菜单和工商信息)。就当是初学者的笔记吧。















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









