









 本文详细介绍如何在微信小程序中实现用户定位及到指定位置的导航功能。通过使用map组件和wx.getLocation、wx.openLocation API,结合app.json权限配置,实现了从用户当前位置到目的地的路径导航。
本文详细介绍如何在微信小程序中实现用户定位及到指定位置的导航功能。通过使用map组件和wx.getLocation、wx.openLocation API,结合app.json权限配置,实现了从用户当前位置到目的地的路径导航。
一:实现定位及到指定位置导航所需组件及API
1:组件:map(地图组件)
2:API:wx.getLocation(Object object)(获取当前的地理位置、速度),wx.openLocation(Object object)(使用微信内置地图查看位置)
二:代码实现
前提:在app.json中加上:
"permission":{
"scope.userLocation": {
"desc": "获取位置"
}
},1:wxml
<view>
<map id="map"
longitude="{{longitude}}"
latitude="{{latitude}}"
scale="14"
markers="{{markers}}"
bindmarkertap="markertap"
bindregionchange="regionchange"
show-location
style="width: 100%; height: 300px;"
>
</map>
</view>
<view>
<button type="primary" bindtap="navigate">导航</button>
</view>2:js
//js
Page({
/**
* 页面的初始数据
*/
data: {
//设置标记点
markers: [
{
iconPath: "/images/ljx.png",
id: 4,
latitude: 31.938841,
longitude: 118.799698,
width: 30,
height: 30
}
],
//当前定位位置
latitude:'',
longitude: '',
},
navigate() {
使用微信内置地图查看标记点位置,并进行导航
wx.openLocation({
latitude: this.data.markers[0].latitude,//要去的纬度-地址
longitude: this.data.markers[0].longitude,//要去的经度-地址
})
},
onLoad() {
//获取当前位置
wx.getLocation({
type: 'gcj02',
success: (res) => {
console.log(res)
this.setData({
latitude: res.latitude,
longitude: res.longitude
})
}
})
}
})根据如上即可实现自身定位及到指定位置的导航,如下:
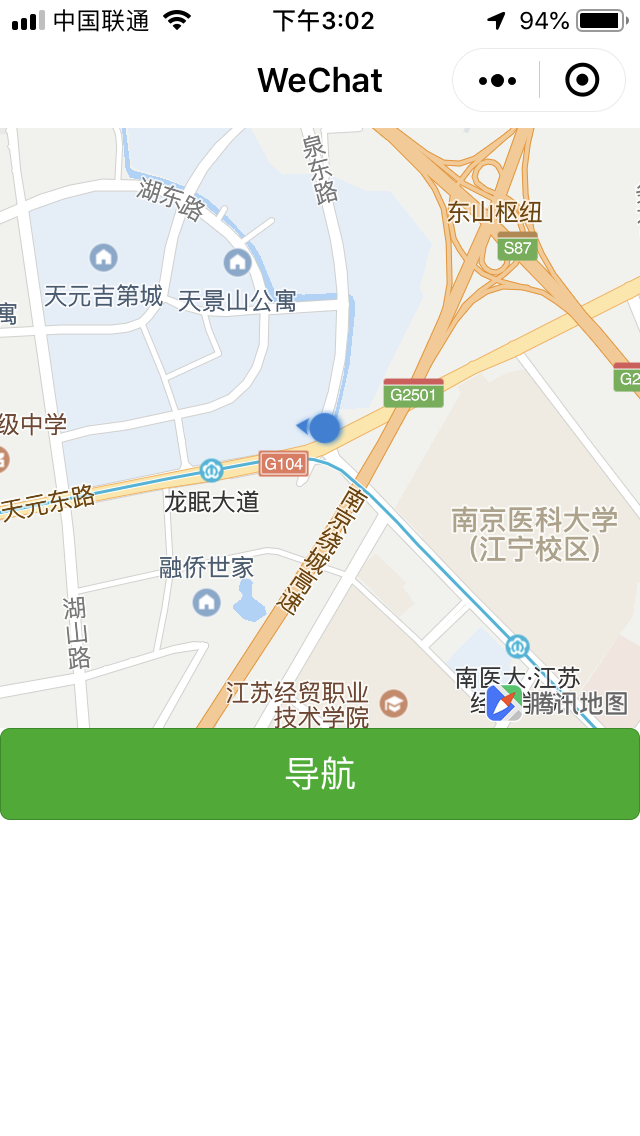
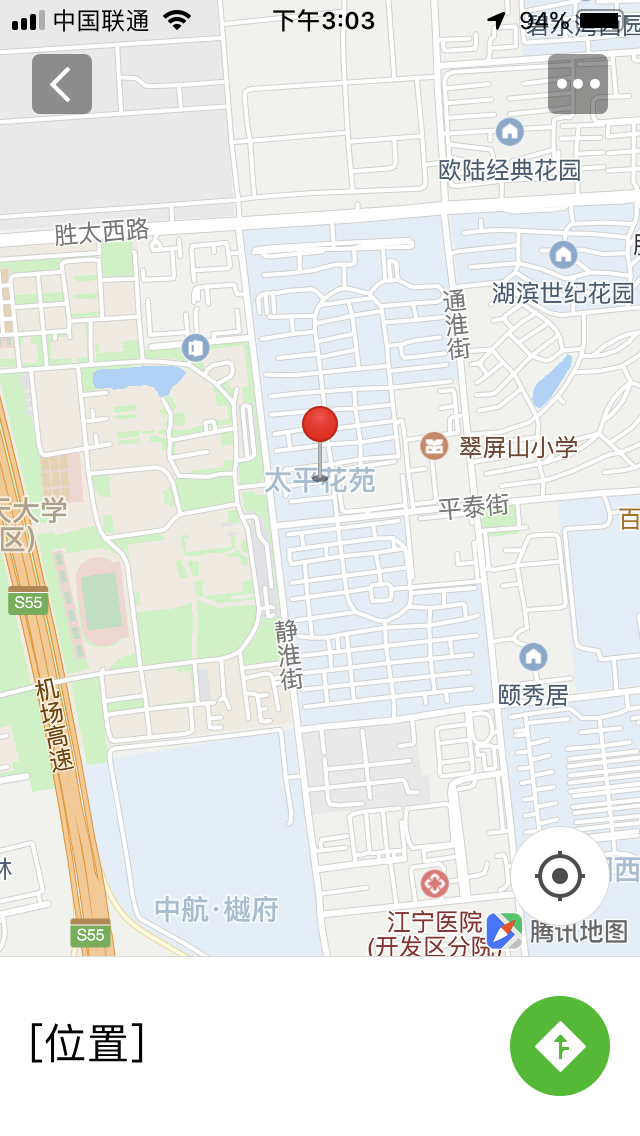
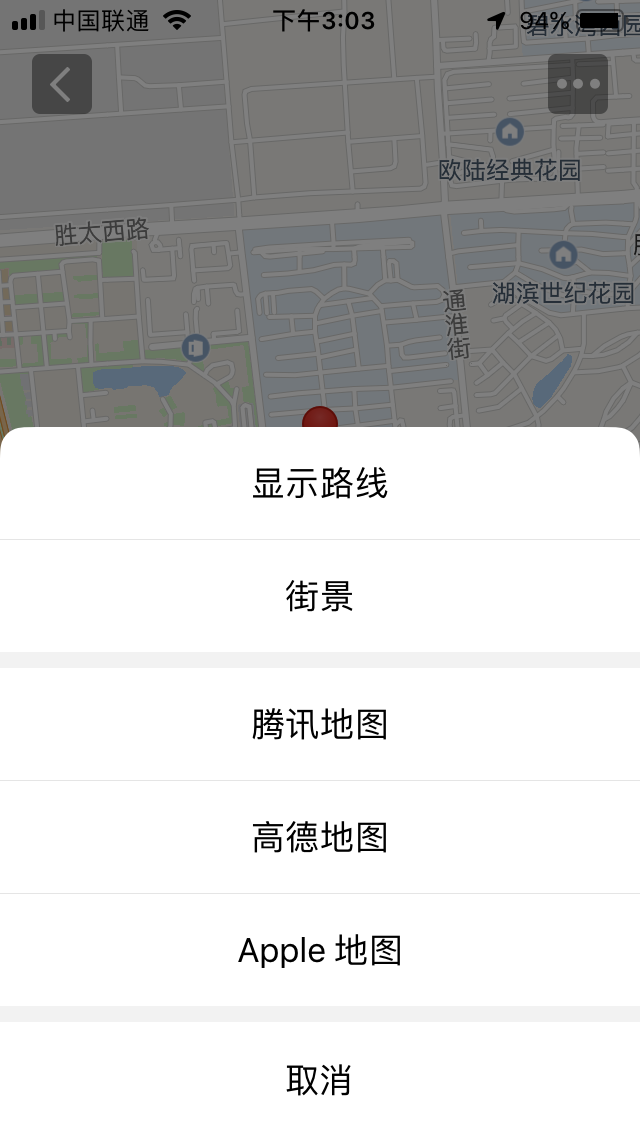
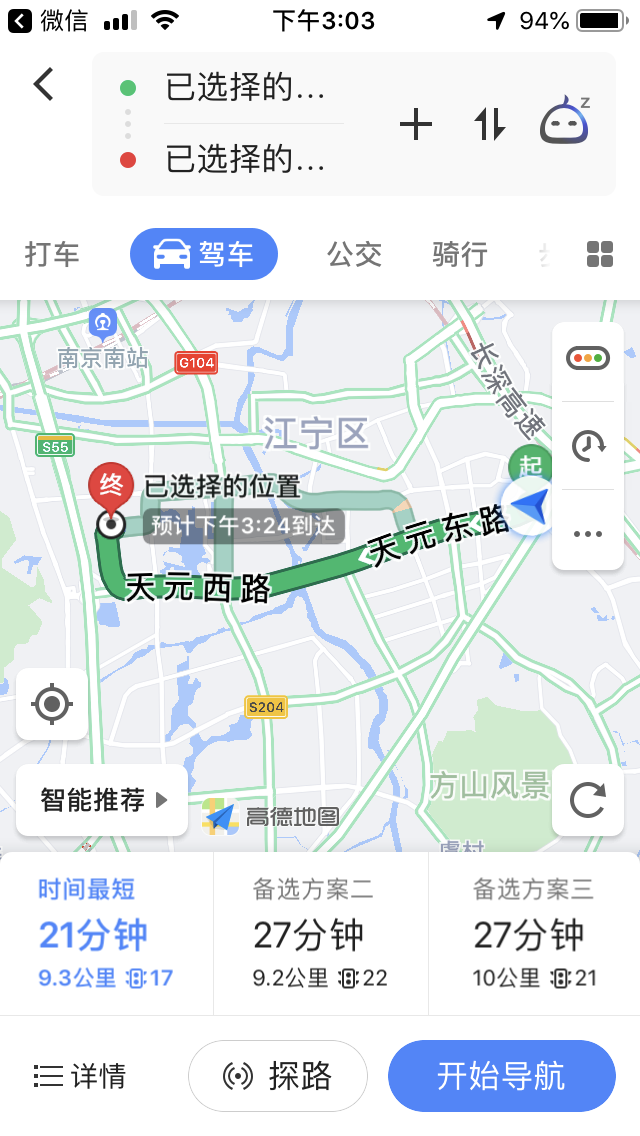



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











