






阻塞队列blockingQueue实战及其原理分析 下
阻塞队列源码分析
SynchronousQueue
SynchronousQueue是一个没有数据缓冲的BlockingQueue,生产者线程对其的插入操作 put必须等待消费者的移除操作take。
SynchronousQueue 最大的不同之处在于,它的容量为 0,所以没有一个地方来暂存元素,导致每次取数据都要先阻塞,直到有数据被放入;同理,每次放数据的时候也会阻塞,直到有消费者来取。 需要注意的是,SynchronousQueue 的容量不是 1 而是 0,因为 SynchronousQueue 不需 要去持有元素,它所做的就是直接传递(direct handoff)。由于每当需要传递的时候, SynchronousQueue 会把元素直接从生产者传给消费者,在此期间并不需要做存储,所以如果运用得当,它的效率是很高的。

应用场景
SynchronousQueue非常适合传递性场景做交换工作,生产者的线程和消费者的线程同步传 递某些信息、事件或者任务。
SynchronousQueue的一个使用场景是在线程池里。如果我们不确定来自生产者请求数量, 但是这些请求需要很快的处理掉,那么配合SynchronousQueue为每个生产者请求分配一个消费线程是处理效率最高的办法。Executors.newCachedThreadPool()就使用了 SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
构造方法
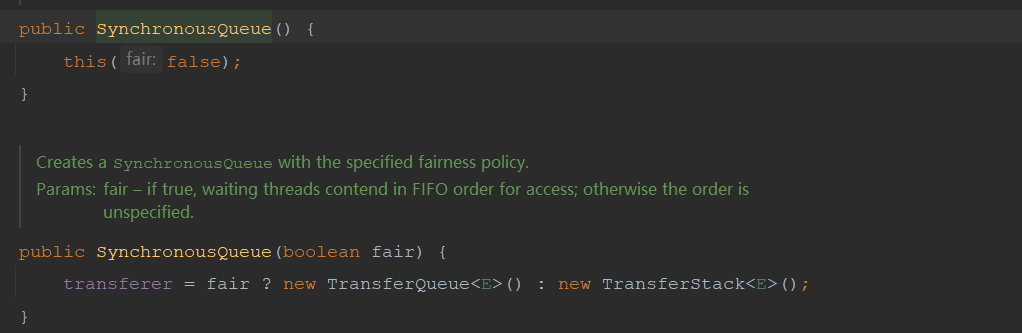
SynchronousQueue可以实现公平和非公平。默认是非公平。非公平底层使用到的是TransferStack,公平使用的是TransferQueue
看下put和take的方法
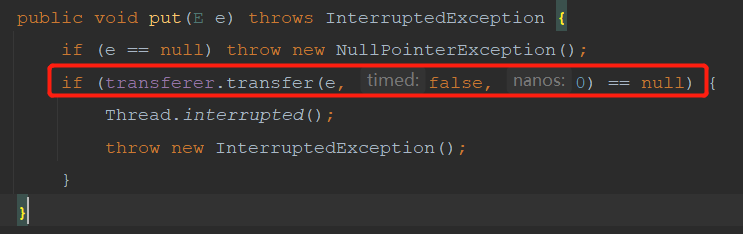
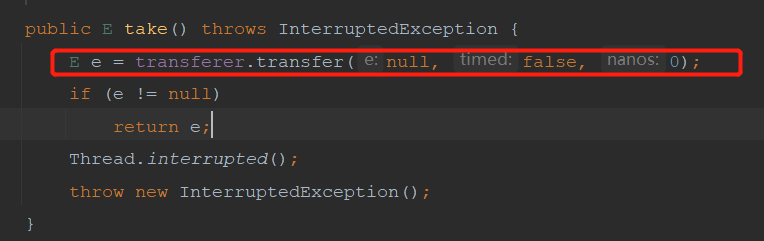

SynchronousQueue不管是公平还是非公平都是使用链表来实现。只不过公平的时候这链表的结构是队列的结构 先进先出 ,非公平的时候链表的结构是栈的结构,先进后出。
以公平为例先看下链表结构TransferQueue
static final class QNode {
//下一个节点的指针
volatile QNode next; // next node in queue
//存储的数据
volatile Object item; // CAS'ed to or from null
//调用的线程
volatile Thread waiter; // to control park/unpark
//表示入队true 还是出队false
final boolean isData;

在创建SynchronousQueue的时候就会new TransferQueue(),此时就会创建好一个链表QNode。回过头来看put方法中的transfer方法
E transfer(E e, boolean timed, long nanos) {
QNode s = null;
boolean isData = (e != null);//put放入的数据如果不是null 那么就为true 表示 入队
for (;;) {
//tail 和head 在构造方法中就构造出来了 tail == head == QNode h = new QNode(null, false);
QNode t = tail;
QNode h = head;
if (t == null || h == null) // saw uninitialized value
continue; // spin
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
//这部分各种判断 不重要
if (t != tail) // inconsistent read
continue;
if (tn != null) { // lagging tail
advanceTail(t, tn);
continue;
}
if (timed && nanos <= 0) // can't wait
return null;
if (s == null)
s = new QNode(e, isData);
if (!t.casNext(null, s)) // failed to link in
continue;
//CAS修改尾节点为 存放put进来元素的节点
advanceTail(t, s); // swing tail and wait
//重点:先是通过自旋阻塞,然后自旋到一定次数 还没有消费该元素 就会 通过park方法阻塞
Object x = awaitFulfill(s, e, timed, nanos);
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
if (!s.isOffList()) { // not already unlinked
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { // complementary-mode
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
}
advanceHead(h, m); // successfully fulfilled
//当有元素被消费后 经过上面各种if判断 最终会通过unpark方法唤醒阻塞的线程
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* e就是put放进来的元素 e没被消费的情况下 s存储的元素就是e*/
final long deadline = timed ? System.nanoTime() + nanos : 0L;
//获取当前线程
Thread w = Thread.currentThread();
//获取自旋次数 如果头节点的下一个节点不是s 那么次数为0 如果是的话次数=512
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
//判断当前线程的中断标志
if (w.isInterrupted())
s.tryCancel(e);
Object x = s.item;
//判断元素有没有被消费 x==e表示未消费
if (x != e)
//消费后直接返回
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
//先是自旋spins次 进行阻塞
if (spins > 0)
--spins;
else if (s.waiter == null)
//在节点中存放当前线程 因为线程要阻塞了 必须记录是哪个线程阻塞
s.waiter = w;
else if (!timed)
//自旋次数达到后 通过park方法阻塞
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
总结下来就是transfer方法中的进行入队阻塞所有生产者,通过自旋方式等待消费者消费,消费后唤醒其他阻塞的生产者。阻塞是通过自旋一定次数加上park方法阻塞。
take方法也是调用了transfer,逻辑也是一样的,如果元素为空,阻塞所有消费者,通过自旋等待生产者生产。
PriorityBlockingQueue
PriorityBlockingQueue是一个无界的基于数组的优先级阻塞队列,数组的默认长度是11,虽然指定了数组的长度,但是可以无限的扩充,直到资源消耗尽为止,每次出队都返回优先级别最高的或者最低的元素。默认情况下元素采用自然顺序升序排序,当然我们也可以通过构造函数来指定Comparator来对元素进行排序。需要注意的是PriorityBlockingQueue不能保证同优先级元素的顺序。
优先级队列PriorityQueue: 队列中每个元素都有一个优先级,出队的时候,优先级最高的先出。

应用场景
电商抢购活动,会员级别高的用户优先抢购到商品
银行办理业务,vip客户插队
PriorityBlockingQueue使用
public class PriorityBlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
//创建优先级阻塞队列 Comparator为null,自然排序
PriorityBlockingQueue<Integer> queue=new PriorityBlockingQueue<Integer>(3);
// 自定义Comparator
// PriorityBlockingQueue queue=new PriorityBlockingQueue<Integer>(
// 5, new Comparator<Integer>() {
// @Override
// public int compare(Integer o1, Integer o2) {
// return o2-o1;
// }
// });
Random random = new Random();
System.out.println("put:");
for (int i = 0; i < 5; i++) {
int j = random.nextInt(100);
System.out.print(j+" ");
queue.put(j);
}
System.out.println("\ntake:");
for (int i = 0; i < 5; i++) {
System.out.print(queue.take()+" ");
}
}
}
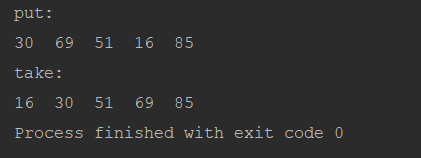
那么如何构造优先级队列?
如果是采用数组的话,哪怕是有序的数组
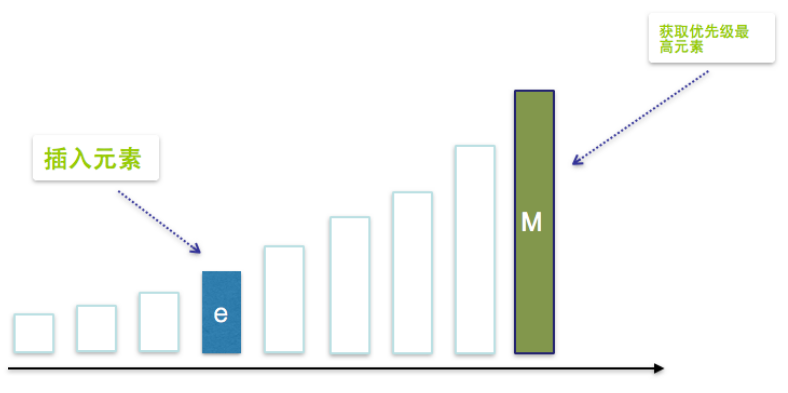
获取优先级最高元素,O(1)
删除优先级最高元素,O(1)
插入一个元素,需要两个步骤,第一步我们需要找出要插的位置,这里我们可以使用二分查找,成本为O(logn),第二步是插入元素之后,将其所有后继进行后移操作,成本为O(n),所有总成本为O(logn)+O(n)=O(n)。时间复杂度也不低。
PriorityBlockingQueue的底层用了一个二插堆和数组来实现。
大顶堆(最大堆):父结点的键值总是大于或等于任何一个子节点的键值;
小顶堆(最小堆):父结点的键值总是小于或等于任何一个子节点的键值。
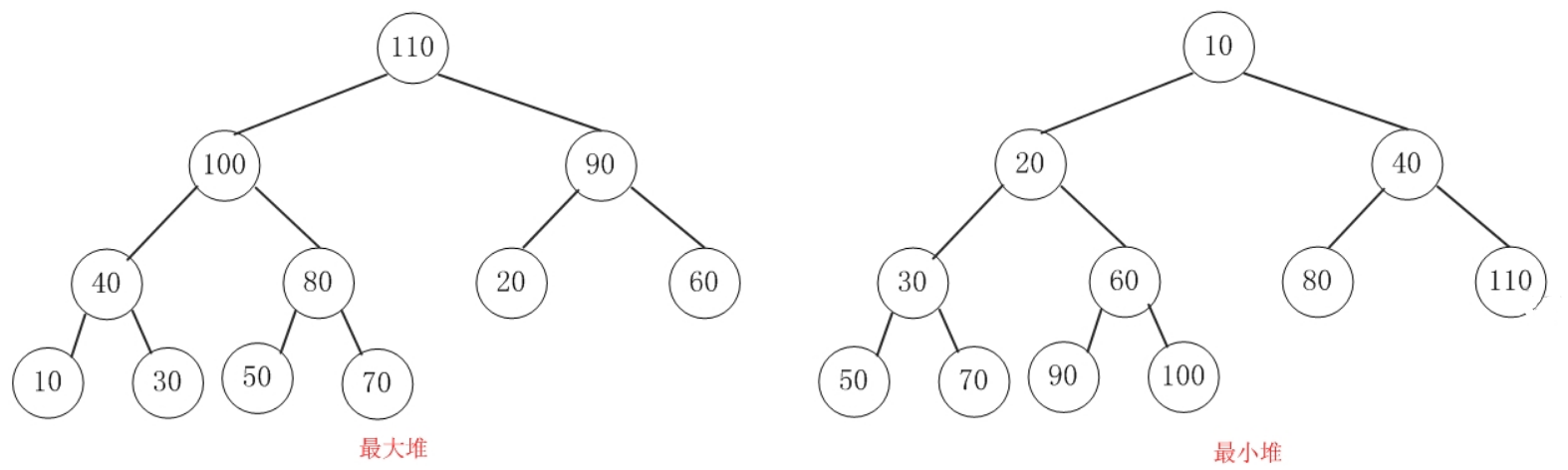
最小堆的节点算法:假设元素在数组中的下标为t,那么父节点、左右子节点的下标计算方式如下
parent(t) = (t-1)>>>1 这是移位操作 相当于 (t-1)/2
left(t) = t << 1+1 相当于 2t+1
right(t) = t << 1+2 相当于 2t+2
源码分析
重要属性
//初始容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
//数组的最大值 基本可以认为是无界
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//通过数组实现
private transient Object[] queue;
//数组长度
private transient int size;
//比较器
private transient Comparator<? super E> comparator;
//出队入队用的是同一把锁
private final ReentrantLock lock;
//因为是无界 所以不考虑放满的情况,只考虑数组为空的情况
private final Condition notEmpty;
构造方法

默认构造方法的初始容量就是11,没有实现任何比较构造器,默认就是最小堆的实现
入队put方法底层调用的是offer方法
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
int n, cap;
Object[] array;
while ((n = size) >= (cap = (array = queue).length))
//扩容机制
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null)
//最小堆实现
siftUpComparable(n, e, array);
else
//自定义比较器实现
siftUpUsingComparator(n, e, array, cmp);
//数组长度+1
size = n + 1;
//唤醒条件等待的线程 从条件队列转同步队列
notEmpty.signal();
} finally {
//解锁 唤醒同步队列中的等待线程
lock.unlock();
}
return true;
}
先来看下扩容机制
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
//意思是如果旧数组的长度小于64,则新数组的长度为旧的加2再加上旧的长度
//如果旧的长度大于64,新数组的长度扩大1.5倍
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
//如果超出最大值 抛出内存溢出异常
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // back off if another thread is allocating
Thread.yield();
//扩容的时候先加锁
lock.lock();
if (newArray != null && queue == array) {
//通过数组拷贝方式 扩容
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
主要是siftUpComparable(n, e, array);这个方法最小堆的算法实现。这是一个精髓点
//k:数组下标 x:put的元素 array:传入的数组
private static <T> void siftUpComparable(int k, T x, Object[] array) {
//获取到保存的值
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
//获取父节点的下标
int parent = (k - 1) >>> 1;
//获取父节点的值
Object e = array[parent];
//保存的值和父节点的值比较 如果保存的值大于父节点不需要改变
if (key.compareTo((T) e) >= 0)
break;
//否则 k这个下标的值就等于 父节点的值
array[k] = e;
//k 等于父节点
k = parent;
}
//将保存的值 放入数组对应下标中
array[k] = key;
}
这个最小堆的算实现举个例子,比如放入30和5两个数字。
- 第一次数组为空那么
siftUpComparable(0, 30, array)。key = x = 30因为k不大于0 所以 直接执行array[k] = key;就是父节点array[0] = 30。此时父节点是30 - 第二次数组不为空了,那么
siftUpComparable(1, 5, array)。key = x = 5此时k=1 >0所以执行while里面的方法。获取到父节点的值为30。然后5和30比较,5不大于30 返回-1 所以往下执行array[k] = e;实际上就是array[1] = 30;然后 k = 0 ;然后继续while循环 ;此时 k = 0获取父节点值就是array[0] = 30。然后有进行比较 此时30 等于30 返回0 退出while循环 。执行array[k] = key; 也就是array[0] = 5; 此时父节点就变成了5了
这部分就是入队的操作。在看下出队的操作
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
//dequeue() 主要的出队方法
while ( (result = dequeue()) == null)
//如果队列为空 进行阻塞
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}
private E dequeue() {
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
//获取父节点的值 也就是最小值
E result = (E) array[0];
//获取数组的最后一个值
E x = (E) array[n];
//设置数组最后一个值为null
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
//主要的算法逻辑 x:数组最后一个值 n:数组最后一个下标
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
private static <T> void siftDownComparable(int k, T x, Object[] array, int n) {
if (n > 0) {
//key就是 数组最后一个值
Comparable<? super T> key = (Comparable<? super T>)x;
//是计算下标 就是n的一半
int half = n >>> 1; // loop while a non-leaf
while (k < half) {
//向左移位 然后+1
int child = (k << 1) + 1; // assume left child is least
//就是取左节点的值
Object c = array[child];
//计算右节点下标
int right = child + 1;
//下面就是判断大小 然后位置交换
if (right < n &&
((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
c = array[child = right];
if (key.compareTo((T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = key;
}
}
这个就不举例了,要打断点跟进去才能更好的了解。
DelayQueue
DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素。延迟队列的特点是:不是先进先出,而是会按照延迟时间的长短来排序,下一个即将执行的任务会排到队列的最前面。
它是无界队列,放入的元素必须实现 Delayed 接口,而 Delayed 接口又继承了 Comparable 接口,所以自然就拥有了比较和排序的能力。

看个案例
//实体类 必须实现 Delayed接口重写 getDelay 和 compareTo方法 才能放入延迟队列中
@Data
@ToString
public class OrderInfo implements Delayed {
public OrderInfo(){};
public OrderInfo(Long id,Long exTime){
this.orderId = id;
this.status = 1;
this.orderTime = new Date();
this.exTime = exTime + orderTime.getTime();
};
//订单id
private Long orderId;
//订单支付过期时间 单位毫秒
private Long exTime;
//订单支付状态 1 待支付 2 支付成功 3支付失败
private Integer status;
//下单时间
private Date orderTime;
//出队的条件
@Override
public long getDelay(TimeUnit unit) {
return exTime - System.currentTimeMillis();
}
//排序
@Override
public int compareTo(Delayed o) {
if (this.exTime < ((OrderInfo) o).getExTime()) return -1;
if (this.exTime > ((OrderInfo) o).getExTime()) return 1;
return 0;
}
}
public class DelayQueueDemo {
public static void main(String[] args) throws InterruptedException {
//实例化一个延迟队列
DelayQueue<OrderInfo> queue = new DelayQueue<>();
//第一个参数 订单id 第二个参数 过期时间 单位毫秒
queue.put(new OrderInfo(1L,15000L));
queue.put(new OrderInfo(2L,10000L));
queue.put(new OrderInfo(3L,5000L));
queue.put(new OrderInfo(4L,20000L));
//获取支付超时的订单
for (;;) {
OrderInfo take = queue.take();
//设置超时的订单 状态为支付失败
take.setStatus(3);
System.out.println(take);
}
}
看打印的顺序 按照过期时间来

源码分析
重要属性
//用于保证队列操作的线程安全
private final transient ReentrantLock lock = new ReentrantLock();
// 优先级队列,存储元素,用于保证延迟低的优先执行
private final PriorityQueue<E> q = new PriorityQueue<E>();
// 用于标记当前是否有线程在排队(仅用于取元素时) leader 指向的是第一个从队列获取元素阻塞的线程
private Thread leader = null;
// 条件,用于表示现在是否有可取的元素 当新元素到达,或新线程可能需要成为leader时被通知
private final Condition available = lock.newCondition();
public DelayQueue() {}
public DelayQueue(Collection<? extends E> c) {
this.addAll(c);
入队put方法
public void put(E e) {
offer(e);
}
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 入队方法 入队的操作和上面讲到的PriorityBlockingQueue 很像,也是有对应的扩容机制和构建最小堆(最大堆)的方法
//不在重复分析
q.offer(e);
//q.peek()是出队的操作 如果能够出队并且等于刚放入的元素 说明当前元素延迟最小
if (q.peek() == e) {
// 若入队的元素位于队列头部,说明当前元素延迟最小
// 将 leader 置空
leader = null;
//当队列为空时,take方法会阻塞 所以通过signal()
// 将available条件队列转同步队列,准备唤醒阻塞在available上的线程
available.signal();
}
return true;
} finally {
lock.unlock(); // 解锁,真正唤醒阻塞的线程
}
}
出队take方法
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();// 取出堆顶元素( 最早过期的元素,但是不弹出对象)
if (first == null)// 如果堆顶元素为空,说明队列中还没有元素,直接阻塞等待
available.await();//当前线程无限期等待,直到被唤醒,并且释放锁。
else {
long delay = first.getDelay(NANOSECONDS);// 堆顶元素的到期时间
if (delay <= 0)// 如果小于0说明已到期,直接调用poll()方法弹出堆顶元素
return q.poll();
// 如果delay大于0 ,则下面要阻塞了
// 将first置为空方便gc
first = null;
// 如果有线程争抢的Leader线程,则进行无限期等待。
if (leader != null)
available.await();
else {
// 如果leader为null,把当前线程赋值给它
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 等待剩余等待时间
available.awaitNanos(delay);
} finally {
// 如果leader还是当前线程就把它置为空,让其它线程有机会获取元素
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// 成功出队后,如果leader为空且堆顶还有元素,就唤醒下一个等待的线程
if (leader == null && q.peek() != null)
// available条件队列转同步队列,准备唤醒阻塞在available上的线程
available.signal();
// 解锁,真正唤醒阻塞的线程
lock.unlock();
}
如何选择适合的阻塞队列
线程池对于阻塞队列的选择
线程池有很多种,不同种类的线程池会根据自己的特点,来选择适合自己的阻塞队列。
- FixedThreadPool(SingleThreadExecutor 同理)选取的是 LinkedBlockingQueue
- CachedThreadPool 选取的是 SynchronousQueue
- ScheduledThreadPool(SingleThreadScheduledExecutor同理)选取的是延迟队列
选择策略
通常我们可以从以下 5 个角度考虑,来选择合适的阻塞队列:
- 功能
第 1 个需要考虑的就是功能层面,比如是否需要阻塞队列帮我们排序,如优先级排序、延迟执行等。如果有这个需要,我们就必须选择类似于 PriorityBlockingQueue 之类的有排序能力的阻塞队列。 - 容量
第 2 个需要考虑的是容量,或者说是否有存储的要求,还是只需要“直接传递”。在考虑这一点的时候,我们知道前面介绍的那几种阻塞队列,有的是容量固定的,如 ArrayBlockingQueue;有的默认是容量无限的,如 LinkedBlockingQueue;而有的里面没有任何容量,如 SynchronousQueue;而对于 DelayQueue 而言,它的容量固定就是 Integer.MAX_VALUE。所以不同阻塞队列的容量是千差万别的,我们需要根据任务数量来推算出合适的容量,从而去选取合适的 BlockingQueue。 - 能否扩容
第 3 个需要考虑的是能否扩容。因为有时我们并不能在初始的时候很好的准确估计队列的大小,因为业务可能有高峰期、低谷期。如果一开始就固定一个容量,可能无法应对所有的情况,也是不合适的,有可能需要动态扩容。如果我们需要动态扩容的话,那么就不能选择 ArrayBlockingQueue ,因为它的容量在创建时就确定了,无法扩容。相反,PriorityBlockingQueue 即使在指定了初始容量之后,后续如果有需要,也可以自动扩容。所以我们可以根据是否需要扩容来选取合适的队列。 - 内存结构
第 4 个需要考虑的点就是内存结构。我们分析过 ArrayBlockingQueue 的源码,看到了它的内部结构是“数组”的形式。和它不同的是,LinkedBlockingQueue 的内部是用链表实现的,所以这里就需要我们考虑到,ArrayBlockingQueue 没有链表所需要的“节点”,空间利用率更高。所以如果我们对性能有要求可以从内存的结构角度去考虑这个问题。 - 性能
第 5 点就是从性能的角度去考虑。比如 LinkedBlockingQueue 由于拥有两把锁,它的操作粒度更细,在并发程度高的时候,相对于只有一把锁的 ArrayBlockingQueue 性能会更好。另外,SynchronousQueue 性能往往优于其他实现,因为它只需要“直接传递”,而不需要存储的过程。如果我们的场景需要直接传递的话,可以优先考虑 SynchronousQueue。














 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









