







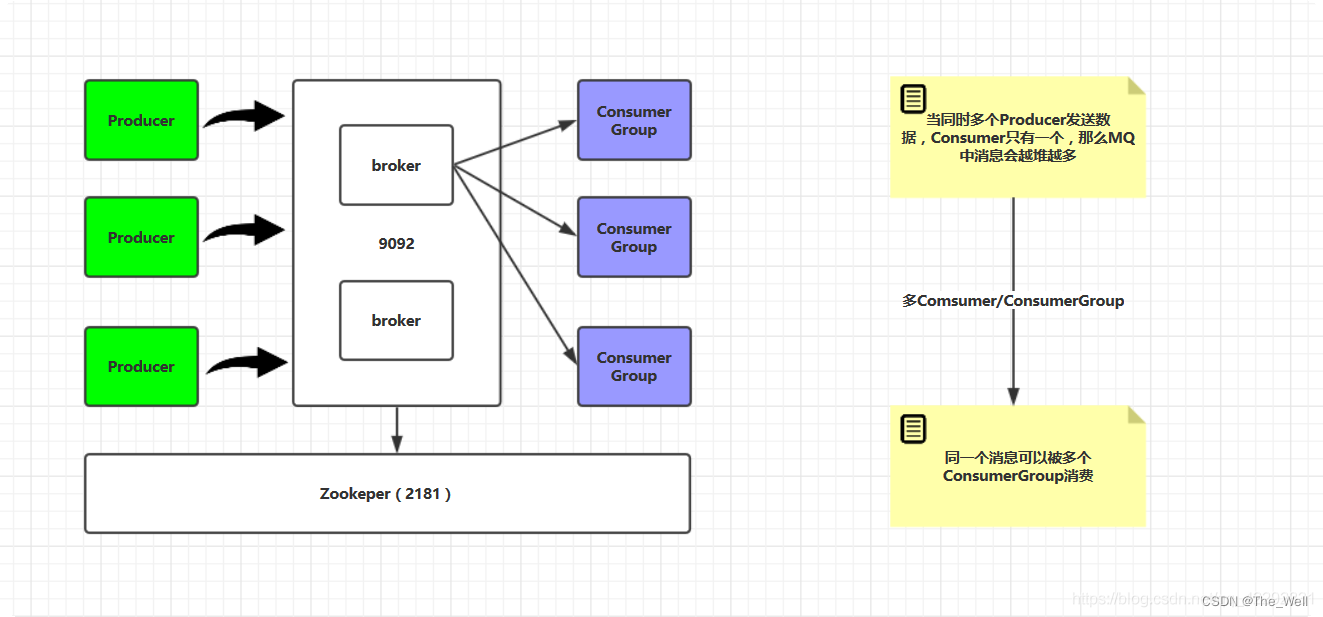
1. Kafka拓扑结构图
Kafka各组件之间交互:

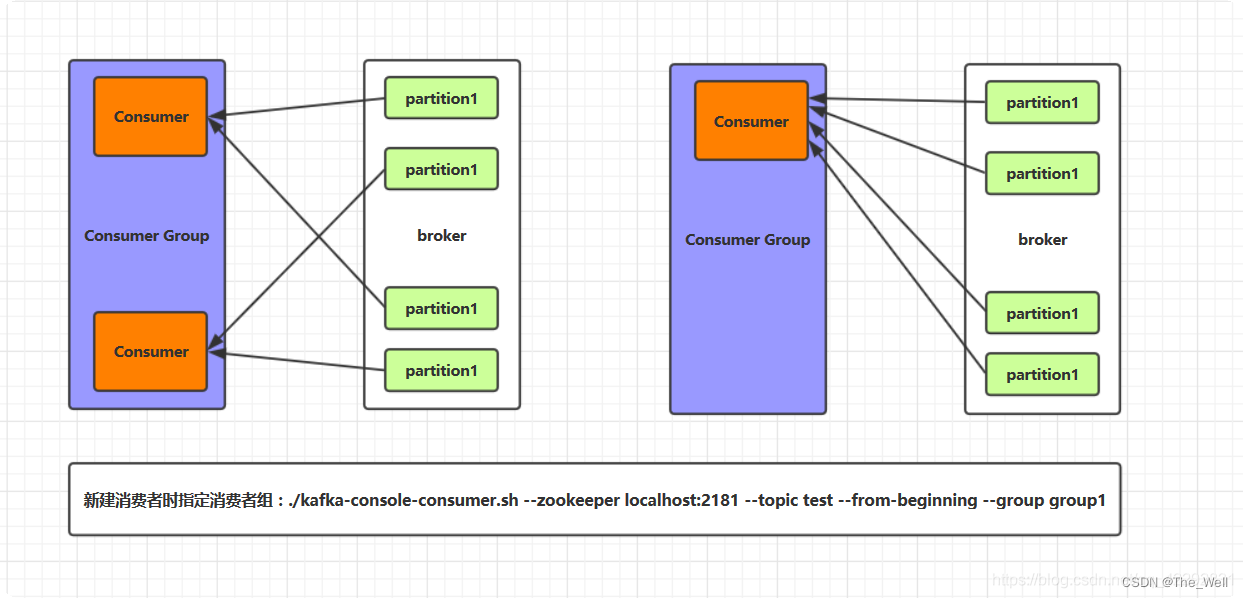
消费者与消费者组之间关系:
2. 角色说明
A. producer
消息生产者,发布消息到kafka 集群的终端或服务
B. broker
节点,kafka 集群中包含的服务器
C. topic
主题,每条发布到kafka 集群的消息属于的类别。生产者向Kafka中生产消息或消费者从消费者中消费消息都是以Kafka的topic为单位的。即Kafka是面向topic的。
D. partition
分区,parition是物理上的概念,每个topic包含一个或多个partition。Kafka分配的原则是partition。partition数只能增加,不能减少。
E. consumer
消息消费者,从Kafka集群中消费消息的终端或服务
F. consumer group
消费者组,每一个consumer都属于一个consumer group。每条消息可以被多个consumer group消费,但是每条消息只能被consumer group中的一个consumer消费。即数据是组内竞争,组间共享。
G. replication
副本,为了保证数据的高可用,每一个partition可以有多个replication。replication有leader和follower两种角色。
H. leader
replication的角色,每一个partition可以有多个replication,但是只有一个leader。producer和consumer只与角色为leader的replication交互。
I. follower
replication的角色,负责从leader中同步数据。当leader挂掉后,选出新的leader,继续工作。
J. controller
整个Kafka集群的管理者,Kafka集群中的其中一台服务器,用来进行leader选举以及各种失败恢复。
1》负责管理集群的broker的上下线
2》所有topic的分区副本分配
3》leader选举
K. zookeeper
Kafka通过zookeeper来存储集群的元数据信息。
3. 设计理念
A. 为了方便扩展并提高吞吐量,一个topic分为多个分区。
B. 配合分区的概念提出了消费者组的概念,组内的每个消费者并行消费。消费者组内的每个消费者负责消费不同分区的数据,一个分区只能被一个消费者消费。
C. 为了提高高可用,每一个分区增加了若干个副本。类似与HDFS的namenode的HA
/usr/local/kafka/kafka_2.13-2.4.1
bin/zookeeper-server-start.sh -daemon config/zookeeper.propertie
bin/kafka-server-start.sh -daemon config/server.properties
nohup ./kafka-server-start.sh ../config/server.properties &
nohup ./zookeeper-server-start.sh ../config/zookeeper.properties &sudo wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.rpm
sudo chmod +x jdk-8u131-linux-x64.rpm
sudo rpm -ivh jdk-8u131-linux-x64.rpm
E:\kafka\kafka_2.12-2.5.0\bin\windows启动zk
bin/windows
.\zookeeper-server-start.bat ..\..\config\zookeeper.properties启动kafka
bin/windows
.\kafka-server-start.bat ..\..\config\server.properties启动生产者
.\kafka-console-producer.bat -broker-list localhost:9092 --topic user_test启动消费者
.\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic user_test --from-beginning启动
canal.deployer-1.1.5
目录 canal.deployer-1.1.5\bin
.\startup.bat local启动canal- admin
E:\cancal\canal.admin-1.1.4\bin
.\startup.bat.\kafka-topics.bat --delete --bootstrap-server localhost:9092 --topic dts
.\kafka-topics.bat --bootstrap-server localhost:9092 --list
instance.propertis
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0# enable gtid use true/false
canal.instance.gtidon=false# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=# username/password
canal.instance.dbUsername=root
canal.instance.dbPassword=123456
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch# mq config
canal.mq.topic=dts
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################server管理配置
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB# binlog ddl isolation
canal.instance.get.ddl.isolation = false# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xmlcanal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml##################################################
######### MQ #############
##################################################
canal.mq.servers = 127.0.0.1:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









