







( 本文主要翻译自 高通8450基线代码中 \kernel_platform\msm-kernel\Documentation\scheduler\sched-energy.rst 的说明文档)
一、介绍
能量感知调度(EAS)使调度程序能够预测其决策对 CPU 消耗的电量的影响。 EAS 依赖于 CPU 的能量模型 (EM) 来为每个任务选择省电的 CPU,同时要求对执行任务的吞吐量的影响最小。 本文档介绍 EAS 的工作原理、它背后的主要设计决策是什么,并说明让它运行所需的条件。
EAS不支持SMP架构的处理器。
EAS 仅在异构 CPU 架构上(例如 Arm big.LITTLE)上运行,因为这是通过调度器节省电量的效果最大的地方。
EAS使用的实际的EM部分不是由调度器维护的,而是由专用的框架维护的,具体细节可以参考documentation/power/energy-model.rst文档。
Energy Aware Scheduling (or EAS) gives the scheduler the ability to predict
the impact of its decisions on the energy consumed by CPUs. EAS relies on an
Energy Model (EM) of the CPUs to select an energy efficient CPU for each task,
with a minimal impact on throughput. This document aims at providing an
introduction on how EAS works, what are the main design decisions behind it, and
details what is needed to get it to run.
Before going any further, please note that at the time of writing::
/!\ EAS does not support platforms with symmetric CPU topologies /!\
EAS operates only on heterogeneous CPU topologies (such as Arm big.LITTLE)
because this is where the potential for saving energy through scheduling is
the highest.
The actual EM used by EAS is _not_ maintained by the scheduler, but by a
dedicated framework. For details about this framework and what it provides,
please refer to its documentation (see Documentation/power/energy-model.rst).二、术语介绍
先从下面两个概念开始:
能量 = [焦耳](移动设备上的电池、电能)
功率 = 能量/时间 = [焦耳/秒] = [瓦特]
EAS的目标使用最小的能量完成所需要执行的动作,所以我们主要考量下面两个参数:
performance [ ints / s] / power [w] 最大值
energy [j] / instruction 最小值
在上述两个指标合适的同时仍然获得优异的性能表现,这种思路考虑了两个方面:能效和性能。
引入 EM 背后的想法是让调度程序能够评估其决策的影响,而不是盲目使用可能仅对某些平台有效果的低功耗手段。同时,EM 模型必须尽可能简单,以减小调度程序延迟的效果。
简而言之,EAS 改变了 CFS 任务分配到CPU 的方式。当调度程序决定当前任务应该在哪里运行时(在唤醒期间),EM 用来打破了几个好的 CPU 候选者之间的平等关系,选择一个最佳的候选CPU运行当前任务:会产生最少的电量消耗而不牺牲系统的吞吐量的目标。 EAS 做出的预测依赖于有关平台架构的特性,其中包括 CPU 的“容量”及其各自的能源成本。
To make it clear from the start:
- energy = [joule] (resource like a battery on powered devices)
- power = energy/time = [joule/second] = [watt]
The goal of EAS is to minimize energy, while still getting the job done. That
is, we want to maximize::
performance [inst/s]
--------------------
power [W]
which is equivalent to minimizing::
energy [J]
-----------
instruction
while still getting 'good' performance. It is essentially an alternative
optimization objective to the current performance-only objective for the
scheduler. This alternative considers two objectives: energy-efficiency and
performance.
The idea behind introducing an EM is to allow the scheduler to evaluate the
implications of its decisions rather than blindly applying energy-saving
techniques that may have positive effects only on some platforms. At the same
time, the EM must be as simple as possible to minimize the scheduler latency
impact.
In short, EAS changes the way CFS tasks are assigned to CPUs. When it is time
for the scheduler to decide where a task should run (during wake-up), the EM
is used to break the tie between several good CPU candidates and pick the one
that is predicted to yield the best energy consumption without harming the
system's throughput. The predictions made by EAS rely on specific elements of
knowledge about the platform's topology, which include the 'capacity' of CPUs,
and their respective energy costs.三、具体实现细节
EAS(以及调度程序的其余部分)使用“容量”的概念来区分具有不同计算吞吐量的 CPU。 CPU 的“容量”表示与系统中最强大的 CPU 相比,它以最高频率运行时可以完成的工作量。CPU容量值在0~1024 范围内进行归一化处理,同时与由PELT 机制计算的任务与 CPU 的利用率数据相对比。通过容量和利用率值,EAS 能够估计任务有多大或者CPU有多繁忙,并在评估性能与能源的权衡时考虑到这一点。CPU的容量可以通过与架构想的代码回调函数arch_scale_cpu_capacity()获取到。
EAS 使用的其余必须的信息可以直接从能源模型 (EM) 框架中读取。平台的 EM 由系统中每个“性能域”的功率成本表组成。具体细节可以参考documentation/power/energy-model.rst文档。
当前调度器域建立或者重建的时候,调度器管理拓扑结构中对EM对象的引用。对于每一个根域(root domain)rd,调度器维护一个单独的关于性能域交叉的链表rd->span,链表的每一个节点包含一个指向由EM框架提供的em_perf_domain结构体的指针。
绑定到rd上的链表的目标是为了方便的应对独占的cpuset配置。因为独占的cpuset配置与性能域不一定是匹配的,所以不同的根域(rd)可以包含重复的元素。
下面试一个12个CPU的平台 分成了3个性能域,3个性能域也可以分成两个根域

现在我们假设用户空间分成两个cpusets,因此创建2个独立的域,每个域包含6个独立的CPU,如上图,两个域rd1和rd2在pd4相交,所以pd4同时出现在rd1和rd2中。使用'->pd'我们可以用如下的方式来描述:
* rd1->pd: pd0 -> pd4
* rd2->pd: pd4 -> pd8
调度器会为p4创建两个重复的链表节点,即使如此,这两个节点也仅仅是保持了一个指向相同共享的EM框架数据结构的指针。
同时EAS也维护了一个静态的关键字(sched_energy_present),当rd达到了EAS启动的所有条件(具体条件在第六章中有详细的列举)后,这个值将被设置为enabled状态。
EAS (as well as the rest of the scheduler) uses the notion of 'capacity' to
differentiate CPUs with different computing throughput. The 'capacity' of a CPU
represents the amount of work it can absorb when running at its highest
frequency compared to the most capable CPU of the system. Capacity values are
normalized in a 1024 range, and are comparable with the utilization signals of
tasks and CPUs computed by the Per-Entity Load Tracking (PELT) mechanism. Thanks
to capacity and utilization values, EAS is able to estimate how big/busy a
task/CPU is, and to take this into consideration when evaluating performance vs
energy trade-offs. The capacity of CPUs is provided via arch-specific code
through the arch_scale_cpu_capacity() callback.
The rest of platform knowledge used by EAS is directly read from the Energy
Model (EM) framework. The EM of a platform is composed of a power cost table
per 'performance domain' in the system (see Documentation/power/energy-model.rst
for futher details about performance domains).
The scheduler manages references to the EM objects in the topology code when the
scheduling domains are built, or re-built. For each root domain (rd), the
scheduler maintains a singly linked list of all performance domains intersecting
the current rd->span. Each node in the list contains a pointer to a struct
em_perf_domain as provided by the EM framework.
The lists are attached to the root domains in order to cope with exclusive
cpuset configurations. Since the boundaries of exclusive cpusets do not
necessarily match those of performance domains, the lists of different root
domains can contain duplicate elements.
Example 1.
Let us consider a platform with 12 CPUs, split in 3 performance domains
(pd0, pd4 and pd8), organized as follows::
CPUs: 0 1 2 3 4 5 6 7 8 9 10 11
PDs: |--pd0--|--pd4--|---pd8---|
RDs: |----rd1----|-----rd2-----|
Now, consider that userspace decided to split the system with two
exclusive cpusets, hence creating two independent root domains, each
containing 6 CPUs. The two root domains are denoted rd1 and rd2 in the
above figure. Since pd4 intersects with both rd1 and rd2, it will be
present in the linked list '->pd' attached to each of them:
* rd1->pd: pd0 -> pd4
* rd2->pd: pd4 -> pd8
Please note that the scheduler will create two duplicate list nodes for
pd4 (one for each list). However, both just hold a pointer to the same
shared data structure of the EM framework.
Since the access to these lists can happen concurrently with hotplug and other
things, they are protected by RCU, like the rest of topology structures
manipulated by the scheduler.
EAS also maintains a static key (sched_energy_present) which is enabled when at
least one root domain meets all conditions for EAS to start. Those conditions
are summarized in Section 6.四、EAS任务分配
EAS 调度算法重写了 CFS 任务唤醒平衡代码。它使用平台的 EM 和 PELT 信息在调度时机唤醒期间选择节能目标 CPU。当启用 EAS 时,select_task_rq_fair() 调用 find_energy_efficient_cpu() 来执行任务选择的决策。此函数会在每个性能域中寻找具有最高备用容量(CPU 容量 - CPU 利用率)的 CPU,因为它可以让我们保持最低频率去运行任务。然后,该函数检查将任务迁移到候选CPU与将其留在之前的CPU 上相比是否可以节省电量。
find_energy_efficient_cpu() 使用 compute_energy() 来估计如果唤醒任务被迁移,系统将消耗多少电量。 compute_energy() 查看 CPU 的当前利用率情况并对其进行调整以“模拟”任务迁移。 EM 框架提供 em_pd_energy() API,该 API 计算给定使用环境下每个性能域的预期能耗。
让我们假设一个虚拟平台,它有 2 个独立的性能域,每个域由两个 CPU 组成。 CPU0 和 CPU1 是little CPU; CPU2 和 CPU3 为big CPU。
调度程序必须决定当前任务P迁移到哪个CPU进行执,当前任务P工作量负载util_avg = 200 和 prev_cpu = 0 。
CPU 的当前利用率情况如下图所示。 CPU 0-3 的 工作量负载 util_avg 分别为 400、100、600 和 500。每个性能域都有三个操作性能点 (OPP)。 能源模型表中列出了与每个 OPP 相关的 CPU 容量和电力成本。 P 的 util_avg 在下图中显示为“PP”
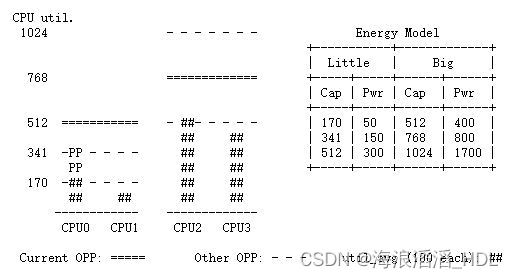
find_energy_efficient_cpu() 将首先在两个性能域中查找具有最大备用容量的 CPU。 在本例中,CPU1 和 CPU3。 然后它会估计系统的能量,如果 P 放在它们中的任何一个上,并检查与将 P 放在 CPU0 上相比是否会节省一些能量。EAS假定OPP遵循的利用率规则与schedutil CPUFreq的行为保持一致,具体参加第六章。
情况1:任务P迁移到CPU1上

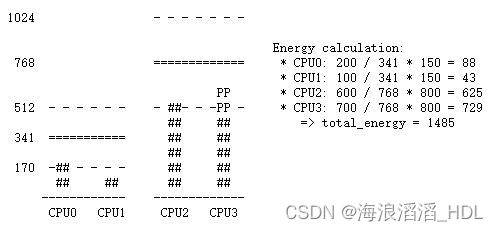
情况2:P迁移到CPU3上
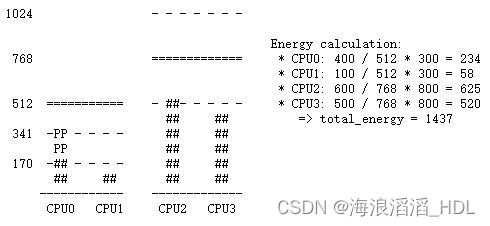
情况3:P仍然保持在原来的CPU0上执行(prev_cpu = 0)
大核 CPU 通常比小 核CPU 更耗电,因此主要在任务不适合小 CPU 时才迁移到大核CPU使用。然而,小 核CPU 并不总是比大 核CPU 更节能。例如,对于某些系统,小核CPU 的高 OPP 可能比大核 CPU 的最低 OPP 节能。因此,如果小 CPU 在特定时间点恰好有足够的利用率,那么在那个时刻醒来的小任务可能会更好地在大侧执行以节省能量,即使它适合小侧.
并且即使在大CPU的所有OPP都比小CPU的能源效率低的情况下,使用大核CPU执行小任务在特定条件下仍然可以节省能源。事实上,将一个任务放在一个小的 CPU 上会导致整个性能域的 OPP 提高,这将增加已经在那里运行的任务的成本。如果将唤醒任务放在大核CPU 上,其自身的执行成本可能会比在小 CPU 上运行时更高,但不会影响小 CPU 的其他任务,这些任务将继续以较低的 OPP 运行。因此,在考虑 CPU 消耗的总能量时,在大内核上运行该任务的额外成本可能小于在小 CPU 上为所有其他任务提高 OPP 的成本。
如果不知道在系统中的所有 CPU 上不同 OPP 下的运行的成本,上面的示例几乎不可能以通用方式正确完成,并广泛适用于所有平台。由于基于 EM 的设计,EAS 可以正确应对它们而不会遇到太多麻烦。但是,为了确保对高利用率场景的吞吐量影响最小,EAS 还实施了另一种称为“过度利用率”的机制
EAS overrides the CFS task wake-up balancing code. It uses the EM of the
platform and the PELT signals to choose an energy-efficient target CPU during
wake-up balance. When EAS is enabled, select_task_rq_fair() calls
find_energy_efficient_cpu() to do the placement decision. This function looks
for the CPU with the highest spare capacity (CPU capacity - CPU utilization) in
each performance domain since it is the one which will allow us to keep the
frequency the lowest. Then, the function checks if placing the task there could
save energy compared to leaving it on prev_cpu, i.e. the CPU where the task ran
in its previous activation.
find_energy_efficient_cpu() uses compute_energy() to estimate what will be the
energy consumed by the system if the waking task was migrated. compute_energy()
looks at the current utilization landscape of the CPUs and adjusts it to
'simulate' the task migration. The EM framework provides the em_pd_energy() API
which computes the expected energy consumption of each performance domain for
the given utilization landscape.
An example of energy-optimized task placement decision is detailed below.
Example 2.
Let us consider a (fake) platform with 2 independent performance domains
composed of two CPUs each. CPU0 and CPU1 are little CPUs; CPU2 and CPU3
are big.
The scheduler must decide where to place a task P whose util_avg = 200
and prev_cpu = 0.
The current utilization landscape of the CPUs is depicted on the graph
below. CPUs 0-3 have a util_avg of 400, 100, 600 and 500 respectively
Each performance domain has three Operating Performance Points (OPPs).
The CPU capacity and power cost associated with each OPP is listed in
the Energy Model table. The util_avg of P is shown on the figures
below as 'PP'::
CPU util.
1024 - - - - - - - Energy Model
+-----------+-------------+
| Little | Big |
768 ============= +-----+-----+------+------+
| Cap | Pwr | Cap | Pwr |
+-----+-----+------+------+
512 =========== - ##- - - - - | 170 | 50 | 512 | 400 |
## ## | 341 | 150 | 768 | 800 |
341 -PP - - - - ## ## | 512 | 300 | 1024 | 1700 |
PP ## ## +-----+-----+------+------+
170 -## - - - - ## ##
## ## ## ##
------------ -------------
CPU0 CPU1 CPU2 CPU3
Current OPP: ===== Other OPP: - - - util_avg (100 each): ##
find_energy_efficient_cpu() will first look for the CPUs with the
maximum spare capacity in the two performance domains. In this example,
CPU1 and CPU3. Then it will estimate the energy of the system if P was
placed on either of them, and check if that would save some energy
compared to leaving P on CPU0. EAS assumes that OPPs follow utilization
(which is coherent with the behaviour of the schedutil CPUFreq
governor, see Section 6. for more details on this topic).
**Case 1. P is migrated to CPU1**::
1024 - - - - - - -
Energy calculation:
768 ============= * CPU0: 200 / 341 * 150 = 88
* CPU1: 300 / 341 * 150 = 131
* CPU2: 600 / 768 * 800 = 625
512 - - - - - - - ##- - - - - * CPU3: 500 / 768 * 800 = 520
## ## => total_energy = 1364
341 =========== ## ##
PP ## ##
170 -## - - PP- ## ##
## ## ## ##
------------ -------------
CPU0 CPU1 CPU2 CPU3
**Case 2. P is migrated to CPU3**::
1024 - - - - - - -
Energy calculation:
768 ============= * CPU0: 200 / 341 * 150 = 88
* CPU1: 100 / 341 * 150 = 43
PP * CPU2: 600 / 768 * 800 = 625
512 - - - - - - - ##- - -PP - * CPU3: 700 / 768 * 800 = 729
## ## => total_energy = 1485
341 =========== ## ##
## ##
170 -## - - - - ## ##
## ## ## ##
------------ -------------
CPU0 CPU1 CPU2 CPU3
**Case 3. P stays on prev_cpu / CPU 0**::
1024 - - - - - - -
Energy calculation:
768 ============= * CPU0: 400 / 512 * 300 = 234
* CPU1: 100 / 512 * 300 = 58
* CPU2: 600 / 768 * 800 = 625
512 =========== - ##- - - - - * CPU3: 500 / 768 * 800 = 520
## ## => total_energy = 1437
341 -PP - - - - ## ##
PP ## ##
170 -## - - - - ## ##
## ## ## ##
------------ -------------
CPU0 CPU1 CPU2 CPU3
From these calculations, the Case 1 has the lowest total energy. So CPU 1
is be the best candidate from an energy-efficiency standpoint.
Big CPUs are generally more power hungry than the little ones and are thus used
mainly when a task doesn't fit the littles. However, little CPUs aren't always
necessarily more energy-efficient than big CPUs. For some systems, the high OPPs
of the little CPUs can be less energy-efficient than the lowest OPPs of the
bigs, for example. So, if the little CPUs happen to have enough utilization at
a specific point in time, a small task waking up at that moment could be better
of executing on the big side in order to save energy, even though it would fit
on the little side.
And even in the case where all OPPs of the big CPUs are less energy-efficient
than those of the little, using the big CPUs for a small task might still, under
specific conditions, save energy. Indeed, placing a task on a little CPU can
result in raising the OPP of the entire performance domain, and that will
increase the cost of the tasks already running there. If the waking task is
placed on a big CPU, its own execution cost might be higher than if it was
running on a little, but it won't impact the other tasks of the little CPUs
which will keep running at a lower OPP. So, when considering the total energy
consumed by CPUs, the extra cost of running that one task on a big core can be
smaller than the cost of raising the OPP on the little CPUs for all the other
tasks.
The examples above would be nearly impossible to get right in a generic way, and
for all platforms, without knowing the cost of running at different OPPs on all
CPUs of the system. Thanks to its EM-based design, EAS should cope with them
correctly without too many troubles. However, in order to ensure a minimal
impact on throughput for high-utilization scenarios, EAS also implements another
mechanism called 'over-utilization'.
五、过度利用率
从一般的角度来看,EAS 最有帮助的用例是那些涉及小/中核CPU(light/medium CPU) 利用率的场景。每当长cpu绑定任务执行时,这些任务将需要所有可用的 CPU 容量,并且调度程序无法在不严重损害吞吐量的情况下节省能源。为了避免 EAS 影响性能,一旦 CPU 使用率超过其计算容量的 80%,就会被标记为“过度使用”。只要根域中没有 CPU 被过度使用,负载平衡就会被禁用,并且 EAS 会代替唤醒平衡代码(个人理解为:如果性能根域中没有使用率超过80%的CPU,则使用EAS调度算法;如果使用率超过80%则使用负载均衡调度算法CFS)。如果可以在不损害吞吐量的情况下完成,EAS 可能会比其他系统加载更多能效 CPU。因此,负载平衡器被禁用以防止它破坏 EAS 发现的节能任务迁移。当系统没有过度使用时,这样做是安全的,因为低于 80% 的临界点意味着:所有 CPU 上都有一些空闲时间,因此 EAS 使用的利用率很可能准确地表示系统中各种任务的“大小”;所有任务都应该已经提供了足够的 CPU 容量,无论它们的值如何;由于有空闲容量,所有任务都必须定期阻塞/休眠,并且在唤醒时进行平衡就足够了。
一旦一个 CPU 超过 80% 的临界点,上述三个假设中的至少一个就会变得不正确。在这种情况下,整个根域的“过度使用”标志被引发,EAS 被禁用,负载平衡器被重新启用。通过这样做,调度程序回退到基于负载的算法,以在 CPU 受限的条件下进行唤醒和负载平衡。这更好地尊重了任务的美好价值。
由于过度使用的概念在很大程度上依赖于检测系统中是否存在空闲时间,因此必须考虑被更高(比 CFS)调度类(以及 IRQ)“窃取”的 CPU 容量。因此,过度使用的检测不仅考虑了 CFS 任务使用的容量,还考虑了其他调度类和 IRQ 使用的容量。
From a general standpoint, the use-cases where EAS can help the most are those
involving a light/medium CPU utilization. Whenever long CPU-bound tasks are
being run, they will require all of the available CPU capacity, and there isn't
much that can be done by the scheduler to save energy without severly harming
throughput. In order to avoid hurting performance with EAS, CPUs are flagged as
'over-utilized' as soon as they are used at more than 80% of their compute
capacity. As long as no CPUs are over-utilized in a root domain, load balancing
is disabled and EAS overridess the wake-up balancing code. EAS is likely to load
the most energy efficient CPUs of the system more than the others if that can be
done without harming throughput. So, the load-balancer is disabled to prevent
it from breaking the energy-efficient task placement found by EAS. It is safe to
do so when the system isn't overutilized since being below the 80% tipping point
implies that:
a. there is some idle time on all CPUs, so the utilization signals used by
EAS are likely to accurately represent the 'size' of the various tasks
in the system;
b. all tasks should already be provided with enough CPU capacity,
regardless of their nice values;
c. since there is spare capacity all tasks must be blocking/sleeping
regularly and balancing at wake-up is sufficient.
As soon as one CPU goes above the 80% tipping point, at least one of the three
assumptions above becomes incorrect. In this scenario, the 'overutilized' flag
is raised for the entire root domain, EAS is disabled, and the load-balancer is
re-enabled. By doing so, the scheduler falls back onto load-based algorithms for
wake-up and load balance under CPU-bound conditions. This provides a better
respect of the nice values of tasks.
Since the notion of overutilization largely relies on detecting whether or not
there is some idle time in the system, the CPU capacity 'stolen' by higher
(than CFS) scheduling classes (as well as IRQ) must be taken into account. As
such, the detection of overutilization accounts for the capacity used not only
by CFS tasks, but also by the other scheduling classes and IRQ.
六、EAS 的依赖和要求
由于过度使用的概念在很大程度上依赖于检测系统中是否存在空闲时间,因此必须考虑被更高(比 CFS)调度类(以及 IRQ)“窃取”的 CPU 容量。因此,过度使用的检测不仅考虑了 CFS 任务使用的容量,还考虑了其他调度类和 IRQ 使用的容量。
6.1 - 非对称 CPU 架构
如简介中所述,目前仅在具有非对称 CPU 拓扑的平台上支持 EAS。通过在构建调度域时查找 SD_ASYM_CPUCAPACITY_FULL 标志的存在,在运行时检查此要求。
请注意,EAS 与 SMP 并非根本不兼容,但尚未观察到在 SMP 平台上的显着节省。如果另有证明,此限制可能会在未来进行修改。
6.2 - 能源模型存在
EAS 使用平台的 EM 来估计调度决策对能量的影响。因此,您的平台必须向 EM 框架提供电力成本表才能启动 EAS。
6.3 - 能量模型复杂度
任务唤醒路径对延迟非常敏感。当平台的 EM 太复杂(CPU 太多、性能域太多、性能状态太多……)时,在唤醒路径中使用它的成本可能会令人望而却步。能量感知唤醒算法的复杂度为:
C = Nd * (Nc + Ns)
Nd 性能域的数量; Nc CPU 的数量;和 Ns 是 OPP 的总数(例如:对于两个具有 4 个 OPP 的性能域,Ns = 8)。
以8450为例我们计算一下能力模型复杂度
adb shell "cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_frequencies"
307200 403200 518400 614400 710400 806400 902400 998400 1094400 1190400 1286400 1363200 1459200 1536000 1632000 1708800 1785600adb shell "cat /sys/devices/system/cpu/cpu4/cpufreq/scaling_available_frequencies"
633600 729600 844800 940800 1036800 1152000 1248000 1344000 1459200 1555200 1651200 1766400 1862400 1977600 2073600 2169600adb shell "cat /sys/devices/system/cpu/cpu7/cpufreq/scaling_available_frequencies"
729600 844800 960000 1075200 1190400 1305600 1420800 1536000 1651200 1766400 1881600 1996800 2112000 2227200 2323200 2419200
C(8450某个状态下) = 3*(8+4*17+3*16+16)= 420
在构建调度域时,在根域级别执行复杂性检查。如果 EAS 的 C 恰好高于完全任意的 EM_MAX_COMPLEXITY 阈值(撰写本文时为 2048),则 EAS 将不会在根域上启动。
如果想使用 EAS 但平台的能量模型的复杂性太高而无法与单个根域一起使用,那么只有两种可能的选择:
使用独占的 cpuset 将您的系统拆分为单独的、较小的根域,并在每个域上本地启用 EAS。此选项的优点是开箱即用,但缺点是阻止根域之间的负载平衡,这可能导致系统整体不平衡;
提交补丁以降低 EAS 唤醒算法的复杂性,从而使其能够在合理的时间内处理更大的 EM。
6.4 - Schedutil 调控器
EAS 试图预测 CPU 在不久的将来将在哪个 OPP 上运行,以估计它们的能耗。为此,假设 CPU 的 OPP 遵循其利用率。
尽管在实践中很难为这个假设的准确性提供硬性保证(例如,因为硬件可能不会执行它被告知要做的事情),schedutil 与其他 CPUFreq 调控器相比,至少 requests 频率是使用利用率计算的信号。因此,与 EAS 一起使用的唯一合理的调控器是 schedutil,因为它是唯一一种在频率请求和能量预测之间提供一定程度一致性的调控器。不支持将 EAS 与 schedutil 以外的任何其他调控器一起使用。
6.5 尺度不变的利用率信息
为了对 CPU 和所有性能状态进行准确预测,EAS 需要频率不变和 CPU 不变的 PELT 信号。这些可以使用架构定义的 arch_scale{cpu,freq}_capacity() 回调获得。不支持在未实现这两个回调的平台上使用 EAS。
6.6 超线程(SMT)
当前形式的 EAS 无法识别 SMT,并且无法利用超线程硬件来节省能源。 EAS 将超线程视为独立的 CPU,这实际上会对性能和能源产生反作用。不支持 SMT 上的 EAS。
6. Dependencies and requirements for EAS
----------------------------------------
Energy Aware Scheduling depends on the CPUs of the system having specific
hardware properties and on other features of the kernel being enabled. This
section lists these dependencies and provides hints as to how they can be met.
6.1 - Asymmetric CPU topology
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
As mentioned in the introduction, EAS is only supported on platforms with
asymmetric CPU topologies for now. This requirement is checked at run-time by
looking for the presence of the SD_ASYM_CPUCAPACITY flag when the scheduling
domains are built.
See Documentation/scheduler/sched-capacity.rst for requirements to be met for this
flag to be set in the sched_domain hierarchy.
Please note that EAS is not fundamentally incompatible with SMP, but no
significant savings on SMP platforms have been observed yet. This restriction
could be amended in the future if proven otherwise.
6.2 - Energy Model presence
^^^^^^^^^^^^^^^^^^^^^^^^^^^
EAS uses the EM of a platform to estimate the impact of scheduling decisions on
energy. So, your platform must provide power cost tables to the EM framework in
order to make EAS start. To do so, please refer to documentation of the
independent EM framework in Documentation/power/energy-model.rst.
Please also note that the scheduling domains need to be re-built after the
EM has been registered in order to start EAS.
6.3 - Energy Model complexity
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The task wake-up path is very latency-sensitive. When the EM of a platform is
too complex (too many CPUs, too many performance domains, too many performance
states, ...), the cost of using it in the wake-up path can become prohibitive.
The energy-aware wake-up algorithm has a complexity of:
C = Nd * (Nc + Ns)
with: Nd the number of performance domains; Nc the number of CPUs; and Ns the
total number of OPPs (ex: for two perf. domains with 4 OPPs each, Ns = 8).
A complexity check is performed at the root domain level, when scheduling
domains are built. EAS will not start on a root domain if its C happens to be
higher than the completely arbitrary EM_MAX_COMPLEXITY threshold (2048 at the
time of writing).
If you really want to use EAS but the complexity of your platform's Energy
Model is too high to be used with a single root domain, you're left with only
two possible options:
1. split your system into separate, smaller, root domains using exclusive
cpusets and enable EAS locally on each of them. This option has the
benefit to work out of the box but the drawback of preventing load
balance between root domains, which can result in an unbalanced system
overall;
2. submit patches to reduce the complexity of the EAS wake-up algorithm,
hence enabling it to cope with larger EMs in reasonable time.
6.4 - Schedutil governor
^^^^^^^^^^^^^^^^^^^^^^^^
EAS tries to predict at which OPP will the CPUs be running in the close future
in order to estimate their energy consumption. To do so, it is assumed that OPPs
of CPUs follow their utilization.
Although it is very difficult to provide hard guarantees regarding the accuracy
of this assumption in practice (because the hardware might not do what it is
told to do, for example), schedutil as opposed to other CPUFreq governors at
least _requests_ frequencies calculated using the utilization signals.
Consequently, the only sane governor to use together with EAS is schedutil,
because it is the only one providing some degree of consistency between
frequency requests and energy predictions.
Using EAS with any other governor than schedutil is not recommended.
6.5 Scale-invariant utilization signals
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
In order to make accurate prediction across CPUs and for all performance
states, EAS needs frequency-invariant and CPU-invariant PELT signals. These can
be obtained using the architecture-defined arch_scale{cpu,freq}_capacity()
callbacks.
Using EAS on a platform that doesn't implement these two callbacks is not
supported.
6.6 Multithreading (SMT)
^^^^^^^^^^^^^^^^^^^^^^^^
EAS in its current form is SMT unaware and is not able to leverage
multithreaded hardware to save energy. EAS considers threads as independent
CPUs, which can actually be counter-productive for both performance and energy.
EAS on SMT is not supported.
















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









