







Solr是什么
还是先来科普下,Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
在Solr的官网(http://lucene.apache.org/solr/)上说的Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene
很明显Solr基于Lucene,处在Lucene项目下,基本与Lucene保持同步更新。
Solr是基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。工作方式:查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
Solr工作原理:
Solr对外提供标准的http接口来实现对数据的索引的增加、删除、修改、查询。在 Solr 中,用户通过向部署在servlet 容器中的 Solr Web 应用程序发送 HTTP 请求来启动索引和搜索。Solr 接受请求,确定要使用的适当SolrRequestHandler,然后处理请求。通过 HTTP 以同样的方式返回响应。默认配置返回Solr 的标准 XML 响应,也可以配置Solr 的备用响应格式。
可以向 Solr 索引 servlet 传递四个不同的索引请求:
add/update 允许向 Solr 添加文档或更新文档。直到提交后才能搜索到这些添加和更新。
commit 告诉 Solr,应该使上次提交以来所做的所有更改都可以搜索到。
optimize 重构 Lucene 的文件以改进搜索性能。索引完成后执行一下优化通常比较好。如果更新比较频繁,则应该在使用率较低的时候安排优化。一个索引无需优化也可以正常地运行。优化是一个耗时较多的过程。
delete 可以通过 id 或查询来指定。按 id 删除将删除具有指定 id 的文档;按查询删除将删除查询返回的所有文档。
继续更新:上面说了很多,其实都是幌子,没有什么实际意义,说实在的原来想的就是在这里占个坑,下面来点干货:
Solr怎么玩
1 下载Solr,我用的是solr-5.3.0,解压(我是在windows系统上跑的,最好是在linux下面跑,因为solr有些脚本没有windows版的)
2. 启动
solr-5.3.0\server\solr下面新建一个目录mycore
把solr-5.3.0\server\solr\configsets\basic_configs下面的conf目录copy到mycore里面,新建一个目录data.
修改conf里面的文件schema.xml ,在field id 后面加两行name,age,把那些动态字段全部删掉,真烦,很多人不需要那么多,solr也挺烦的,搞那么多,别人知道是干什么的,吐槽下,真的让很多刚开始学习的童鞋云里雾里,不知道怎么下手,搞得心烦了就放弃了,这种赶脚有木有过?!
这样里面部分看起来像这样:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="age" type="int" indexed="true" stored="true" required="true" multiValued="false" />
<uniqueKey>id</uniqueKey>
这意思很明显了,id是唯一字段(建议这个要有),还有两个字段name,age 其他的配置项都先不要管了。
启动一个CMD窗口到solr安装目录/bin
solr start -p 8983
看到 Started Solr server on port 8983.Happy searching. 恭喜你,启动成功了。打开浏览器 http://localhost:8983/solr
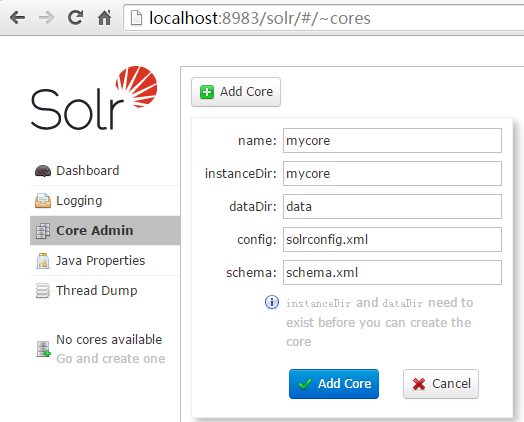
3,管理Core
左边看到有个core admin,新建一个core. 名称为mycore
4,索引,查询
新建成功后,可以看到左下角,有个下拉,选择mycore,点击Document,往里面灌些数据
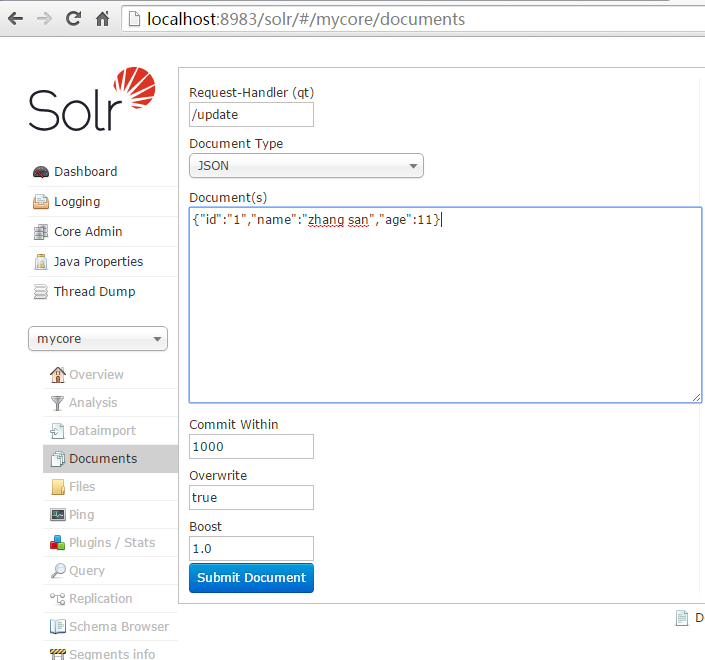
可以多编辑几条数据 {"id":"2","name":"li si","age":22} {"id":"3","name":"zhang si","age":33} 看看
也可以在命令行到bin目录执行 java -Dc=new_core -jar ../example/exampledocs/post.jar ../test/a.xml (最后这个参数就是要索引的文件或者目录都可以,注意目录结构,我的当前目录是bin)
a.xml像这样:
<add>
<doc>
<field name="id">1</field>
<field name="name">aaa</field>
<field name="age">11</field>
</doc>
</add>
在linux下面可以执行bin/post(windows下面没有这个脚本)命令来做。
点击Query,来查询看数据有木有,这个可以有:
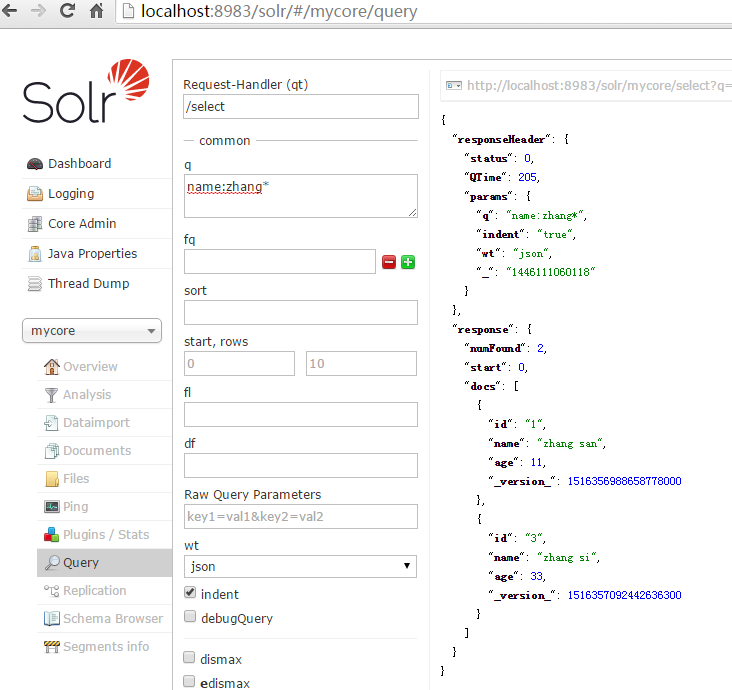
现在一切真相大白了,原来前面做这么多就是为了看这个!现在你爽了没有,其实也很简单,但是网上很多版本比较旧,说的不清楚,都是copy的,所谓原理、说明一大堆,都没有我这个简单明了,Right?
这里面的每一步是做什么的,为什么要这么做,我不多说了,网上很多文档用的上,solr里面的配置文档很多注释也说了很多,看看就清楚了。
核心问题:
字段怎么配置,配置意义
怎么修改删除文档
数据库数据怎么进行索引
复杂查询怎么写
中文分词怎么配置
怎么提高索引/搜索效率
还有Solr的 cluster 下面怎么搞,这个必须的,后面 "数据检索---Solr Colud" 一定搞出来,娃哈哈!















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









