







上次说过的,要整个Solr Cluster也就是Solr Cloud,现在好像比较流行Cloud滴说。网上很多都是solr4版的solr cloud,还都是用tomcat,一大堆copy操作,solr5的很少看到。下面我就来吃个螃蟹,solr5 solr 5 solr5美好的事情要重复三遍!
就像Solr介绍的一样
Apache Solr includes the ability to set up a cluster of Solr servers that combines fault tolerance and high availability. Called SolrCloud, these capabilities provide distributed indexing and search capabilities, supporting the following features:
- Central configuration for the entire cluster
- Automatic load balancing and fail-over for queries
- ZooKeeper integration for cluster coordination and configuration.
这些特性对Cluster是必要的,更多的说明见Solr的文档:https://cwiki.apache.org/confluence/display/solr/Getting+Started+with+SolrCloud
1.单机多节点
[hadoop@vm11 bin]$ ./solr -e cloud 下面按照交互式的命令敲入参数(使用内嵌的ZooKeeper)
例如:nodes =2 the port for node1 8983 the node for node2 7574
new collection : testcoll
shards : 3 replicas :3
configuration:basic_configs
通过以下命令来查看:
[hadoop@vm11 ~]$ cd tools//solr-5.3.0/bin/
[hadoop@vm11 bin]$ ./solr status
Found 2 Solr nodes:
Solr process 2185 running on port 7574
或者打开浏览器:http://IP:8983/solr/#/~cloud 这个可以好好看下,有助理解相关概念(node,collection,shards,replicas),具体的图就不贴了。
上面这些命令在Windows下也很容易成功的,不过使用这种方式建立的是单机版的模拟cluster,两个节点在同一台机器上。
2.多节点完全分布式SolrCloud
| Node Name | IP | HostName |
| Node1 | 192.168.182.128 | vm11 |
| Node2 | 192.168.182.129 | vm22 |
| Node3 | 192.168.182.130 | vm33 |
三个节点安装ZooKeeper,三个节点安装Solr,IP/HOST同上。
2.1 运行ZooKeeper(不使用Solr内嵌的)
下载、解压ZooKeeper,我用的是zookeeper-3.4.6.tar.gz,安装目录是/home/hadoop/tools/zookeeper-3.4.6
cd /home/hadoop/tools/zookeeper-3.4.6
mkdir data
echo "1" >data/myid (这个在后面的配置文件用到)
cd conf
vi zoo.cfg (里面的内容是这样的)
dataDir=/home/hadoop/tools/zookeeper-3.4.6/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=vm11:2888:3888
server.2=vm22:2888:3888
server.3=vm33:2888:3888
dataDir 把内存中的数据存储成快照文件snapshot的目录,同时myid也存储在这个目录下(myid中的内容为本机server服务的标识)是ZK存放数据的目录,最好放在其他的目录,不要在安装目录下。
clientPort 客户端连接server的端口,即zk对外服务端口,一般设置为2181。
initLimit Leader允许Follower在initLimit时间内完成这个工作。默认值为10,即10 * tickTime
syncLimit Leader发出心跳包在syncLimit之后,还没有从Follower那里收到响应,那么就认为这个Follower已经不在线了。默认为5,即5 * tickTime
tickTime ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。
server.X hostname为机器ip,第一个端口n为事务发送的通信端口,第二个n为leader选举的通信端口,默认为2888:3888
配置好了之后,就可以启动ZK了。
./bin/zkServer.sh start
在其他的节点上重复做这个,唯一需要注意的是myid这个文件,在其他的节点上修改为2,3,再启动。
这样ZK就建立起来了。
[hadoop@vm22 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/tools/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
2.2 安装运行Solr
下载解压Solr,我用的是solr-5.3.0 solr5的一大feature就是能作为独立的App运行,不需要和其他的容器绑定,优化安装配置 我解压到 /home/hadoop/tools/solr-5.3.0。激动人心的时刻就要到来了。
我们知道ZooKeeper 就是为了解决统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等而来的。
1) 首先要上传配置文件,放在Zk里面,让Solr从ZK里面来获得配置,管理集群,这个的确是一件美好的事情
在Solr的目录下面有个server/scripts/cloud-scripts目录,里面提供了一个脚本来做这个事情(当然在ZK里面也有脚本来做这个,Solr里面的这个是做了一个封装)
./server/scripts/cloud-scripts/zkcli.sh -cmd upconfig -confdir ./server/solr/configsets/basic_configs/conf -confname myconf -z vm11:2181,vm22:2181,vm33:2181
这几个参数的意义还是比较容易看出来的。
建立Link between collection and conf
./server/scripts/cloud-scripts/zkcli.sh -cmd linkconfig -collection mycol -confname myconf -z vm11:2181,vm22:2181,vm33:2181
可以通过ZK的命令查看是否成功:cd /home/hadoop/tools/zookeeper-3.4.6/bin
./zkCli.sh -server vm22:2181
[zk: vm22:2181(CONNECTED) 2] ls /configs/myconf
[_rest_managed.json, currency.xml, solrconfig.xml, protwords.txt, stopwords.txt, synonyms.txt, lang, schema.xml]
[zk: vm22:2181(CONNECTED) 3] ls /collections/mycol
[state.json, leader_elect, leaders]
2) 下面就可以把每个启动solr节点都启动了。
./bin/solr start -cloud -p 8983 -s "/home/hadoop/tools/solr-5.3.0/server/solr" -z vm11:2181,vm22:2181,vm33:2181
-cloud指定运行为cloud模式 -p 端口
-s 就是要指定solr.xml所在的目录,就是很多时候说的solr.solr.home(solr的官方文档也是这样)这个名字真的是很奇葩,开始的时候很难理解,这么说吧,solr.home就是一般说的solr的安装目录,就像万能的Java_home,hadoop_home.而solr.solr.home可以理解为每个solr运行时的配置目录,包括core,等等。当然也可以copy里面的几个文件,把-s指向其他的目录
-z ZK配置,多个的时候中间用,隔开
三个节点都运行这个命令,运行起来后,这样cloud就跑起来了。
3) 下面来创建Shard,通过curl来执行
curl ’http://vm11:8983/solr/admin/collections?action=CREATE&name=mycol&numShards=3&replicationFactor=3&maxShardsPerNode=3&collection.configName=myconf‘
这个myconf从上面上传到zk里面的配置,我们在前面早就配置好了。其他的几个参数很明显。
在一个节点上运行就可以了。开始打开浏览器:http://192.168.182.128:8983

几个地方我高亮出来了,很容易看出来。再来看看solr.solr.home。例如Node1,这个里面包括三个shard,每个的一个replica
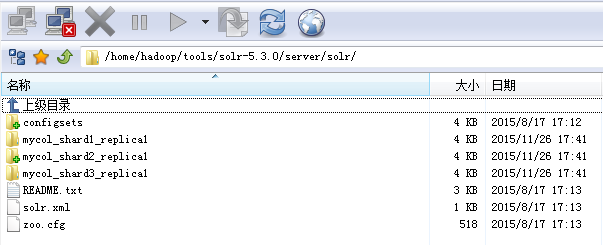
这样这个结构就比较清晰了,很多概念就出来了。下面引用网上的几个图(没有注明出处,如有冒犯,请指出以便删除),可以更清晰的看看几个概念之间的关系
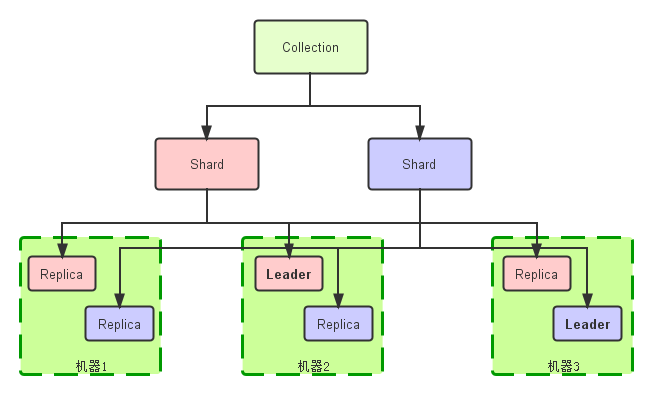
实体和逻辑对应图:
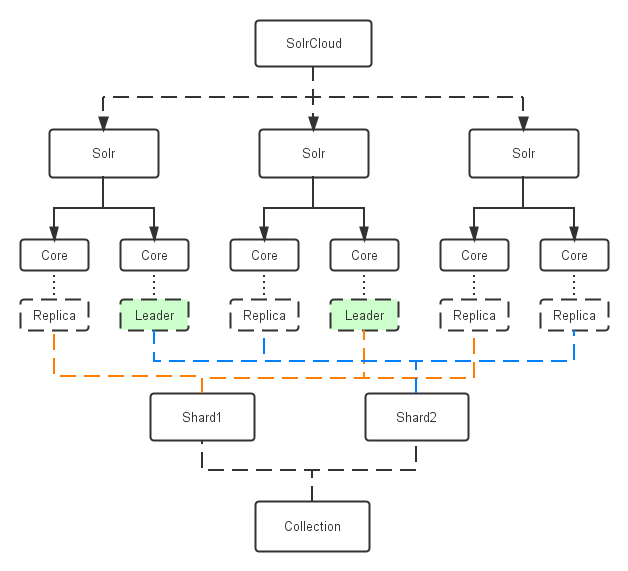
附:Solr Command
Starting with -noprompt
You can also get SolrCloud started with all the defaults instead of the interactive session using the following command:
Restarting Nodes
You can restart your SolrCloud nodes using the bin/solr script. For instance, to restart node1 running on port 8983 (with an embedded ZooKeeper server), you would do:
To restart node2 running on port 7574, you can do:
Notice that you need to specify the ZooKeeper address (-z localhost:9983) when starting node2 so that it can join the cluster with node1.
Adding a node to a cluster
Adding a node to an existing cluster is a bit advanced and involves a little more understanding of Solr. Once you startup a SolrCloud cluster using the startup scripts, you can add a new node to it by:
Notice that the above requires you to create a Solr home directory. You either need to copy solr.xml to the solr_home directory, or keep in centrally in ZooKeeper /solr.xml.
Example (with directory structure) that adds a node to an example started with "bin/solr -e cloud":
The previous command will start another Solr node on port 8987 with Solr home set to example/cloud/node3/solr. The new node will write its log files toexample/cloud/node3/logs.
Once you're comfortable with how the SolrCloud example works, we recommend using the process described in Taking Solr to Production for setting up SolrCloud nodes in production.















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









