







JPivot是一个基于mondrian(OLAP分析服务)的可钻取web报表展示标签,形成了整套的较方便的数据仓库主题web展现工具。话说JPivot已经很久没有更新了,作为小规模的应用,试试可以,但是要做为产品,貌似还差太多。下面以JPivot连接MySQL VS PostgreSQL做个简单的例子,以比较两个数据库有什么差别,作为分析比较之用。
数据准备
1. 建立数据库和表
CREATE TABLE `customer` (
`cusid` int(11) NOT NULL,
`gender` char(1) DEFAULT NULL,
PRIMARY KEY (`cusId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `product` (
`proid` int(11) NOT NULL,
`protypeid` int(11) DEFAULT NULL,
`proname` varchar(32) DEFAULT NULL,
PRIMARY KEY (`proid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `producttype` (
`protypeid` int(11) NOT NULL,
`protypename` varchar(32) DEFAULT NULL,
PRIMARY KEY (`protypeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `sale` (
`saleid` int(11) NOT NULL,
`proid` int(11) DEFAULT NULL,
`cusid` int(11) DEFAULT NULL,
`unitprice` float DEFAULT NULL,
`number` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
说明:表创建参考网上。
PostgreSQL的建表语法基本类似,唯一需要注意的是我把所有的都改为小写,不然后面会有很多问题,吃了很多次这个亏,都吃饱了,一定要注意!
2.导入数据
insert into `customer`(`cusid`,`gender`) values (1,'A'),(2,'B'),(3,'C'),(4,'D'),(5,'E'),(6,'F'),(7,'G'),(8,'H'),(9,'I'),(10,'G');
insert into `producttype`(`protypeId`,`protypename`) values (1,'电子'),(2,'数码'),(3,'设备'),(4,'化工'),(5,'机械'),(6,'纺织'),(7,'医疗'),(8,'卫生'),(9,'轻工'),(10,'其他');
insert into `product`(`proId`,`protypeid`,`proname`) values (1,8,'Prd1'),(2,9,'Prd2'),(3,5,'Prd3'),(4,4,'Prd4'),(5,7,'Prd5'),(6,9,'Prd6'),(7,2,'Prd7'),(8,5,'Prd8'),(9,6,'Prd9'),(10,4,'Prd10');
我的product表时间数据有100条,这里只列出部分。
sale表,写了个java程序,产生随机数据,批处理往里面塞数据
public static void main(String[] args) {
DecimalFormat df = new DecimalFormat("#.00");
int total = 1000000;
int paramNum = 5;
StringBuffer qryStr = new StringBuffer();
// qryStr.append("INSERT INTO product(proid,protypeid,proname) VALUES(");
qryStr.append("INSERT INTO sale(saleId,proid,cusId,unitprice,number) VALUES(");
for (int i = 1; i <= paramNum; i++) {
qryStr.append("?");
if (i != paramNum) {
qryStr.append(",");
}
}
qryStr.append(");");
List<Object[]> data = new ArrayList<Object[]>();
for (int i = 1; i < total + 1; i++) {
Object[] objs = new Object[paramNum];
// objs[0] = i;
// objs[1] = getRandInt(10, 1);
// objs[2] = "Prd" + i + "";
objs[0] = i;
objs[1] = getRandInt(99, 1);
objs[2] = getRandInt(10, 1);
objs[3] = getRandDbl(1000, 1); // Double.parseDouble(df.format(getRandDbl(1000,
// 1)));
objs[4] = getRandInt(999, 1);
data.add(objs);
}
System.out.println("Start ...");
exeBatchParparedSQL(qryStr.toString(), paramNum, "IIIDI", 10000, data);
}
public static void exeBatchParparedSQL(String sql, int paramSize,
String paramType, int batchSize, List<Object[]> data) {
Connection conn = null;
try {
Statement stmt = null;
ResultSet rs = null;
CallableStatement call = null;
Class.forName("org.postgresql.Driver").newInstance();// com.mysql.jdbc.Driver
String url = "jdbc:mysql://localhost:3306/mondrian?useUnicode=true&characterEncoding=utf-8";
String user = "root";
String password = "root"; // for MySQL
url = "jdbc:postgresql://localhost:5432/mondrian";
user = "postgres";
password = "postgres";
conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql);
long t = System.currentTimeMillis();
// int batch = data.size() / batchSize;
for (int i = 1; i < data.size() + 1; i++) {
conn.setAutoCommit(false);
Object obj[] = (Object[]) data.get(i - 1);
for (int j = 0; j < paramSize; j++) {
char p = paramType.charAt(j);
if (p == 'S') {
pstmt.setString(j + 1, (String) obj[j]);
} else if (p == 'I') {
pstmt.setInt(j + 1, (Integer) obj[j]);
} else if (p == 'D') {
pstmt.setDouble(j + 1, (Double) obj[j]);
} else {
System.err.println("Not Support,Please update here");
}
}
pstmt.addBatch();
// 批量执行预定义SQL
if ((i % batchSize == 0 && i > 0) || i == data.size()) {
System.out.println((System.currentTimeMillis() - t)
+ " Exec Batch=" + i);
// conn.setAutoCommit(true);
pstmt.executeBatch();
conn.commit();
t = System.currentTimeMillis();
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
}
}
public static int getRandInt(int max, int min) {
return (int) (Math.random() * (max - min) + min);
}
public static double getRandDbl(double max, double min) {
return (Math.random() * (max - min));
}限于篇幅,只列出主要方法,供参考。
这里说下,我列出了MySQL和PostgreSQL的两个数据库连接,可以分别试试,导入数据的差别个人感觉还是很大的。普通个人电脑测试,每万条记录时间MySQL基本要800ms左右,而PostgreSQL在8ms左右,相差近乎100倍,当然我的MySQL是5.5版本的,PostgreSQL是9.5,都没有加索引。
顺便说明,这里的total为100万,可以改为1000万,试试,看看行不行!
在MySQL有了数据之后可以,使用Kettle将数据导入到PostgreSQL,可以练习下ETL, ,在两个数据库之间导数据。
,在两个数据库之间导数据。
注意:Kettle在处理MySQL数据时可能乱码,需要在配置数据库连接的选项里添加命名参数characterEncoding,值为UTF-8
开发web部分
1 下载JPivot war包,部署到tomcat之类的J2EE应用服务器中。
2. 建立维度模型定义
在webapps\jpivot\WEB-INF\queries新建sales.xml
<?xml version="1.0" encoding="UTF-8"?>
<Schema name="hello">
<Cube name="Sales">
<!-- 事实表(fact table) -->
<Table name="sale" />
<!-- 客户维 -->
<Dimension name="cusGender" foreignKey="cusid">
<Hierarchy hasAll="true" allMemberName="allGender" primaryKey="cusid">
<Table name="customer"></Table>
<Level name="gender" column="gender"></Level>
</Hierarchy>
</Dimension>
<!-- 产品类别维 -->
<Dimension name="proType" foreignKey="proid">
<Hierarchy hasAll="true" allMemberName="allPro" primaryKey="proid" primaryKeyTable="product">
<join leftKey="protypeid" rightKey="protypeid">
<Table name="product" />
<Table name="producttype"></Table>
</join>
<Level name="proTypeId" column="protypeid"
nameColumn="protypename" uniqueMembers="true" table="producttype" />
<Level name="proId" column="proid" nameColumn="proname"
uniqueMembers="true" table="product" />
</Hierarchy>
</Dimension>
<Measure name="numb" column="number" aggregator="sum" datatype="Numeric" />
<Measure name="totalSale" aggregator="sum" formatString="¥#,##0.00">
<!-- unitPrice*number所得值的列 -->
<MeasureExpression>
<SQL dialect="generic">(unitPrice*number)</SQL>
</MeasureExpression>
</Measure>
<CalculatedMember name="averPri" dimension="Measures">
<Formula>[Measures].[totalSale] / [Measures].[numb]</Formula>
<CalculatedMemberProperty name="FORMAT_STRING" value="¥#,##0.00" />
</CalculatedMember>
</Cube>
</Schema>3 新建jsp页面
在该目录下面新建salequery.jsp
<%@ page session="true" contentType="text/html; charset=ISO-8859-1" %>
<%@ taglib uri="http://www.tonbeller.com/jpivot" prefix="jp" %>
<%@ taglib prefix="c" uri="http://java.sun.com/jstl/core" %>
<!--
MYSQL配置 com.mysql.jdbc.Driver jdbc:mysql://localhost:3306/mondrian root root
-->
<jp:mondrianQuery id="query01"
catalogUri="/WEB-INF/queries/sales.xml"
jdbcDriver="org.postgresql.Driver"
jdbcUrl="jdbc:postgresql://localhost:5432/mondrian"
jdbcUser="postgres"
jdbcPassword="postgres"
>
select
{[Measures].[numb],[Measures].[averPri],[Measures].[totalSale]} on columns,
{([proType].[allPro],[cusGender].[allGender])}
on rows
from [Sales]
</jp:mondrianQuery>
<c:set var="title01" scope="session">Sales</c:set>
4 启动tomcat,访问web页面
当然需要把相应的数据库jdbc驱动包copy到lib下面,然后才启动tomcat
http://localhost:8080/jpivot/testpage.jsp?query=salequery
不出意外,应该能够看到页面。
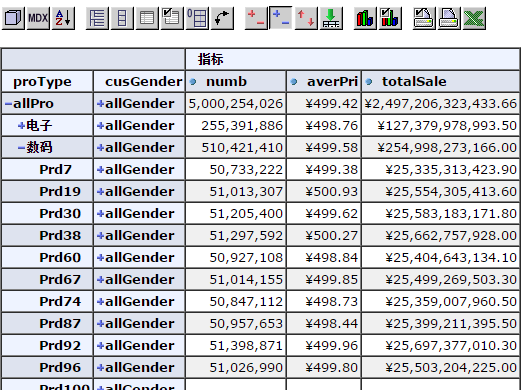
如果遇到下面的错误:
javax.servlet.jsp.JspException: An error occurred while evaluating custom action attribute "test" with value "${query01.result.overflowOccured}": An error occurred while getting property "result" from an instance of class com.tonbeller.jpivot.tags.OlapModelProxy (com.tonbeller.jpivot.olap.model.OlapException:。。。。。
像网上说的去掉testpage.jsp <c:if .../>, 就是"overflowOccured" attribute of the query01 那部分,这样只能治表,不能解决问题,很可能是sales.xml的模式定义除了问题,可以在页面上看看有没有[sql=这样的字符出现,这里就是具体转换之后的sql语句,可以到数据库里面去执行一下,看看问题究竟在哪里。
看到页面之后,可以钻取看看,效果怎么样,性能怎么样。
话说本人第一次试的时候是100万的数据,MySQL速度还是基本满意,后面改为1000万的数据,MySQL都要40多秒才能出现结果,那是一个慢啊,而且点快了就杯具了。
相反换了PostgreSQL,1000万数据的时候大约5秒,勉强能够接受,所以结论这里就不下了,因为涉及很多方面。
MDX的这些操作,在后面是转为sql来实行的,下面在数据库里面查询类似这样:
SELECT proid,cusid,SUM(Number),SUM(number*unitprice) FROM sale GROUP BY proid,cusid
可以分别执行下,看到两个数据库效率的差别了。















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









