






David Silver强化学习笔记-intro_RL


一、关于RL
(一)强化学习的特征
强化学习和其他机器学习的不同之处:
-
没有监督者,只有一个reward标志
-
反馈有延迟,不是马上得到
-
时间很重要(序列)
监督学习时将独立同分布的数据进行学习,而强化学习的数据是有序列的。
-
agent的actions影响着随后接收到的数据。
我们需要应对的是一个动态系统,agent和外部环境进行交互,每一步都在影响着下一步,强化学习是一个主动学习的过程。
(二)强化学习的几个例子
-
直升机飞行特技表演
-
在backgammon游戏击败世界冠军
-
管理一个投资组合
-
控制发电站
通过调整不同的参数,优化效率
-
做一个机器人模仿人类走路
-
在很多Atari游戏中比人类表现还要好
二、强化学习问题
(一)reward
1、rewards
-
reward Rt是一个标量
-
表示在步骤t agent做的有多好
-
agent的工作是最大化累计的reward
强化学习基于奖励假设。
定义(奖励假设)
所有的目标都可以通过预期累计奖励最大化来描述。
agent 的目标是在一个episode中,采取措施,在episode结束时获得最大化的奖励
例如:每经历一个时间不长,都会有一个值为-1的奖励信号,在完成目标后,就会停下来。我们总的奖励就是你耗费的时间。现在我们有两个明确的木不爱,一个是最大化你的累计奖励,另一个是在最短的时间内达成目标。
2、Sequential Decision Making(顺序决策)
- 目标:选择actions来最大化未来总奖励
- actions可能有长期后果
- reward可能会有延迟
- 可能会牺牲即时奖励(reward)以获得更多长期奖励
(二)环境
1、agent and environment


强化学习的数据来源就是action、observation、reward组成的序列。
- agent在每一个时间步t:
- 执行action A_t
- 接收observation O_t
- 接收标量reward R_t
- 环境:
- 接收action A_t
- 发出observation O_t+1
- 发出标量reward R_t+1
(三)state
1、History and State
history就是Observation、actions、reward构成的序列
H t = O 1 , R 1 , A 1 , . . . A t − 1 , O t , R t H_t = O_1,R_1,A_1,...A_t-1,O_t,R_t Ht=O1,R1,A1,...At−1,Ot,Rt
agent目前所经历的一系列东西组成了history
agent 的输入:他所见到的东西,输出:做出的决定。
我们目标是创建一个history到action的映射
-
例如:到时间t所有可观察到的变量,有些变量虽然存在于环境中,但是agent不一定能观察到
-
例如:机器人或具体主体的感觉运动流
-
依靠history接下来会发生什么:
- agent 选择actions
- 环境选择observation/reward
-
State 是用来决定接下来会发生什么的信息
因为history太大,所有我们用state来代替history -
state是history的函数:
S t = f ( H t ) S_t=f(H_t) St=f(Ht)
2、environment state

- 环境状态是环境的私有表示
- 环境状态对agent不是可见、看不懂的,agent不能直接依靠环境状态来执行action
- 即使环境状态是可见的,他也可能包含不相关的信息。
题外话:多agent 系统,让其中一个agent把其他agent看作是环境的一部分。
3、agent state

- agent state是agent的内在表示
agent总结到目前为止发生的事情,根据agent state来决定下一步的action - agent state是用于强化学习算法的信息
- agent state是历史的函数:
S t a = f ( H t ) S^a_t=f(H_t) Sta=f(Ht)
4、information state
information state(也叫Markov state)包含了来自历史的所有有用的信息
定义:
当一个状态满足如下性质为一个Markov状态
P
[
S
t
+
1
∣
S
t
]
=
P
[
S
t
+
1
∣
S
1
,
.
.
.
,
S
t
]
P\lbrack S_{t+1}\vert S_t\rbrack=P\lbrack S_{t+1}\vert S_1,...,S_t\rbrack
P[St+1∣St]=P[St+1∣S1,...,St]
下一时刻的状态仅由当前状态决定与过去的状态没有关系。
- 如果具有Markov性质,未来和过去是独立的,仅仅取决于当下的状态S,当你得到状态s后,只需要将st存储在这里,他具有Markov性质,你就可以让掉history的整个的其他部分,因为history对你起到的帮助比不上state,因为状态决定未来该采取什么行动,状态可以嗲表整个的history,这样更加精简,是一种更好的方式。
- 一旦状态已知,history就可以让掉了
- 状态是对未来的充分统计
Markov state包含了足够多的信息,来得出未来所有的奖励 - 环境状态是Markov性质的
- history是Markov性质
5、Fully Observable Environment

agent可以直接观察到环境状态
O t = S t a = s t e O_t = S^a_t=s^e_t Ot=Sta=ste
- agent state = environment state = information state
- 这是一个Markov decision process(MDP)
6、部分可观察环境
- agent不能直接观察到环境
- 例如:一个机器人的摄像机视觉不能直接告诉他自己的绝对位置
- agent state 不等于environment state
- 这是一个partially observable Markov decision process(POMDP)
- agent必须建筑自己的state representation
- 全部的历史:
S
t
a
=
H
t
S^a_t=H_t
Sta=Ht
记住到目前为止每次的观测、动作和奖励 - Beliefs of environment state:
不相信每一步都是正确的,只是有一定概率是正确的。
S t a = ( P [ S t e = s 1 ] , . . . , P [ S t e = s n ] ) S^a_t=(P[S^e_t=s^1],...,P[S^e_t=s^n]) Sta=(P[Ste=s1],...,P[Ste=sn]) - RNN:
S t a = σ ( S t − 1 a W s + O t W 0 ) S_t^a=\sigma(S_{t-1}^aW_s+O_tW_0) Sta=σ(St−1aWs+OtW0)
通过线性组合的方式得到最新的状态
- 全部的历史:
S
t
a
=
H
t
S^a_t=H_t
Sta=Ht
三、inside An RL Agent
(一)一个RL agent的要素
- 一个RL agent可能包含下列一个或多个因素:
- policy:agent 的行为函数。输入为状态,输出为行动决策
- value function:评估每个状态或行动有多好
- Model:agent 的环境表示,agent眼里的环境,可以用于判断环境的变化。
(二)Policy
- 一个policy是一个agent的行为
- 是state到action的映射
- 确定性的policy: a = π ( s ) a=\pi(s) a=π(s)
- 随机policy: a = π ( a ∣ s ) = P [ A t = a ∣ S t = s ] a=\pi(a\vert s)=P\lbrack A_t=a\vert S_t=s\rbrack a=π(a∣s)=P[At=a∣St=s]
(三)value function
- value function是对未来奖励的预测,告诉我们在未来奖励预期会有多少
- 用来评估state的好坏
- 因此要在动作之间进行选择
V π ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] V_\pi(s)=E_\pi\lbrack R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+...\vert S_t=s\rbrack Vπ(s)=Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s]
看多远会根据gamma大小,一步一步降低奖励,已知到我们可以忽略掉的程度。
(四)Model
model并不是环境本身,它对预测环境变化很有用处,model会学习环境的行为。model可以用来确定计划,model对下一步的行动很有用。
- model预测环境会做什么
- model有两个:
- transition model:用来预测下一个状态,预测环境的动态变化, P 一侧下一个状态
- reward model:用模型来估计我们得到的奖励, 预测下一个immediate reward
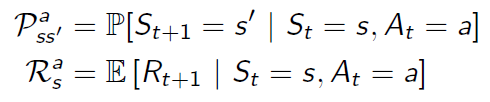
根据先前的状态和动作,环境所处的下一个状态的概率
预期的奖励是基于先前的状态和行动
model 并不是必须的,还有无model的方法。
(五)Maze Example:Policy


一旦得到这个映射,那么你就可以读入数据,然后采取行动最终达到目标。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3kC2lbjo-1574390482507)(E91FB62FFE9C48FEB04920AD801D2A4D)]
状态到行动的映射。
(六)Maze Example:value function

数字表示每个状态s的
v
π
(
s
)
v_\pi(s)
vπ(s)
很容易创建一个最佳的policy。对我们最优化偏好很有用
(七)Maze Example:Model

网格布局代表transition model
数字代表从每个状态s得到的immediate reward
- agent可能有一个环境的内部模型
- 动态:行动会改变状态
- rewards:每个状态会获得多少奖励
- model可能是不完美的
(八)RL agents的种类(1)
-
value based
- No policy(Implicit)
- value function
通过value函数来挑选最优的action
-
policy based
-
policy
-
No value Function
包含每种数据结构,在不适用value函数的情况下尽可能得到多的奖励 -
Actor critic
-
policy
-
value Function
(九)RL agents的种类(2)
-
Model Free
-
policy and/or value function
-
no model
不会尝试去理解环境,并不会创造一个动态特性模型表征直升机如何运动,不需要知道环境的状态 -
model Based
-
policy and/or value function
-
model
(十)RL agent 分类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OghmxDOO-1574390482523)(40860CAD043E4ABB9C12568F1478F182)]](https://img-blog.csdnimg.cn/20191122123925649.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1aWJpbm55,size_16,color_FFFFFF,t_70)
四、Problems within RL
(一)learning and planning
在顺序决策中两个基本问题
-
强化学习:
- 环境刚开始是未知的
- agent和环境交互
- agent改善policy
-
规划(plannning):
- 环境模型是已知的
- agent使用其模型执行计算(无需任何外部交互)
- agent改善自己的policy
- 又名deliberation, reasoning, introspection, pondering,thought, search
(二)Atari Example: Reinforcement Learning

- 游戏的规则未知
- 直接从交互的game-play中学习
- 在操纵杆上选择动作,查看像素和分数
(三)Atari Example: Planning

- 游戏规则已知
- 可以查询模拟器
- agent大脑中的完美模型
- 如果我从状态s采取action
- 下一个状态是什么
- 得分是什么
- 提前计划以找到最佳policy
- 比如:tree search
(四)探索和开发
-
强化学习就像是反复试验的学习
-
agent应该从其环境经验中发现一个好的策略
-
而不会在沿途损失太多的reward
-
探索会发现有关环境的更多信息,有选择地放弃某些奖励。
-
开发会利用已知信息来最大化回报,开发利用已有的信息
-
探索和开发通常很重要
比如:虽然你觉得往左边走比较好,右边没怎么探索,但也许走右边可以得到更大的回报。
探索和开发问题是专属于强化学习的问题。
(五)predication and control
-
prediction:评估未来
- 提供一个policy
遵循现在的policy,在未来我会做的怎么样
- 提供一个policy
-
control:优化未来
- 找到最好的policy
先解决predication的问题,进而解决control问题
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









