




目录
- 1.总结 tomcat实现多虚拟机
- 2.总结 tomcat定制访问日志格式和反向代理tomcat
- 3.总结iptable 5表5链, 基本使用,扩展模块。
- 4.总结iptables规则优化实践,规则保存和恢复。
- 5.总结NAT转换原理, DNAT/SDNAT原理,并自行设计架构实现DNAT/SNAT。
- 6.使用REDIRECT将90端口重定向80,并可以访问到80端口的服务
- 7.firewalld常见区域总结。
- 8.通过ntftable来实现暴露本机80/443/ssh服务端口给指定网络访问
- 9.完成 nginx 反向代理 tomcat实现基于redis会话复制的集群构建
- 10.总结 JVM垃圾回收算法和分代
1.总结 tomcat实现多虚拟机
总体分为四大步:
- 准备JAVA环境
- 安装Tomcat
- 配置多虚拟主机
- 检验测试
1)准备JAVA环境(oracle jdk 8)
#下载安装包:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
#解压到目录:
tar xvf xvf jdk-8u391-linux-x64.tar.gz -C /usr/local/
#创建软链接:
cd /usr/local/;ln -s jdk1.8.0_391/ jdk
#初始化环境变量:
vim /etc/profile.d/jdk.sh
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
#运行初始化脚本:
. /etc/profile.d/jdk.sh
#验证安装:
[root@u200: /usr/local/jdk]# java -version
java version "1.8.0_391"
Java(TM) SE Runtime Environment (build 1.8.0_391-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.391-b13, mixed mode)
2) 安装Tomcat (tomcat9)
#下载并安装:
wget https://downloads.apache.org/tomcat/tomcat-9/v9.0.93/bin/apache-tomcat-9.0.93.tar.gz
#解压:tar xf apache-tomcat-9.0.93.tar.gz -C /usr/local/
#创建软链接:cd /usr/local; ln -s apache-tomcat-9.0.93/ tomcat
#指定PATH变量:echo 'PATH=/usr/local/tomcat/bin:$PATH' > /etc/profile.d/tomcat.sh
. /etc/profile.d/tomcat.sh;
echo $PATH
#创建tomcat 专用帐户:
useradd -r -s /sbin/nologin tomcat
#修改tomcat目录的属主属组:
chown -R tomcat.tomcat /usr/local/tomcat/
#准备service 文件中相关环境文件:
vim /usr/local/tomcat/conf/tomcat.conf
JAVA_HOME=/usr/local/jdk
#创建service文件实现自启动
[Unit]
Description=Tomcat
#After=syslog.target network.target remote-fs.target nss-lookup.target
After=syslog.target network.target
[Service]
Type=forking
Environment=JAVA_HOME=/usr/local/jdk
ExecStart=/usr/local/tomcat/bin/startup.sh
ExecStop=/usr/local/tomcat/bin/shutdown.sh
PrivateTmp=true
User=tomcat
Group=tomcat
[Install]
WantedBy=multi-user.target
#重新加载:
systemctl daemon-reload
#设置开机启动:
systemctl enable --now tomcat
#检验启动情况
[root@u200: /usr/local]# ss -ntl
[root@u200: /usr/local]# ps auxf|grep tomcat
[root@u200: /usr/local]# systemctl status tomcat
#查看日志
tail -f /usr/local/tomcat/logs/catalina.out
3)多虚拟主机配置过程
#修改配置文件,vim conf/server.xml
#在配置文件尾部</Host> 行下添加以下两段
<Host name="node1.x.cn" appBase="/data/webapp1"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="node1_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
<Host name="node2.x.cn" appBase="/data/webapp2"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="node2_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
#准备虚拟主机目录和测试页
mkdir -p /data/webapp{1,2}/ROOT
vim /data/webapp1/ROOT/index.jsp
vim /data/webapp2/ROOT/index.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>jsp例子</title>
</head>
<body>
<br>
<%=request.getRequestURL()%>
</body>
</html>
#设置权限
chown -R tomcat.tomcat /data/webapp{1,2}/
#在测试机上配置域名解析
10.0.0.200 node1.x.cn node2.x.cn
4)检验测试
在window浏览器中访问 :http://node1.x.cn http://node2.x.cn
2.总结 tomcat定制访问日志格式和反向代理tomcat
1)tomcat 定制访问日志格式
- tomcat有五类日志:catalina、localhost、manager、admin、host-manager
- locahost_access_log.YYYY-MM-DD.txt 是访问tomcat的日志,记录请求时间和资源,状态码等信息。
- Tomcat 访问日志格式
#表示指定的首部字段:%{字段名}i 如:%{User-Agent}i,%{Host}i
#" 表示双引号
%h:客户端IP地址
%l:远程逻辑用户名(通常为空)
%u:用户名(如果请求经过了身份验证)
%t:时间戳,格式为 [dd/MMM/yyyy:HH:mm:ss Z]
%r: 请求的第一行(即请求的方法、URL和协议 )
%s:响应状态码
%b:发送给客户端的字节数(不包括头部),如果没有发送字节则显示 -
%D:处理请求所花费的时间(以毫秒为单位)
%{Referer}i: 引用页面
%{User-Agent}i: 客户端使用的浏览器信息
%{xxx}i: 获取请求头中的某个字段
%{xxx}c: 获取特定的 Cookie
%{xxx}r: 获取 ServletRequest 中的某个属性
%{xxx}s: 获取 HttpSession 中的某个属性
- 定制 json 格式的访问日志
#修改配置文件 vim /usr/local/tomcat/conf/server.xml
#注释掉 pattern=""那一行,
<!-- pattern="%h %l %u %t "%r" %s %b" /> -->
#添加以下内容
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","method":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","AgentVersion":"%{User-Agent}i"}"/>
#重启tomcat,验证访问日志
systemctl restart tomcat
#通过window浏览器访问:http://node1.x.cn:8080
tail /usr/local/tomcat/logs/node1_access_log.2024-11-12.txt
]#tail /usr/local/tomcat/logs/node1_access_log.2024-11-12.txt| jq
{
"clientip": "10.0.0.1",
"ClientUser": "-",
"authenticated": "-",
"AccessTime": "[12/Nov/2024:15:29:57 +0800]",
"method": "GET / HTTP/1.1",
"status": "200",
"SendBytes": "142",
"Query?string": "",
"partner": "-",
"AgentVersion": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
2)反向代理实现 tomcat 部署
常见的tomcat部署方式:
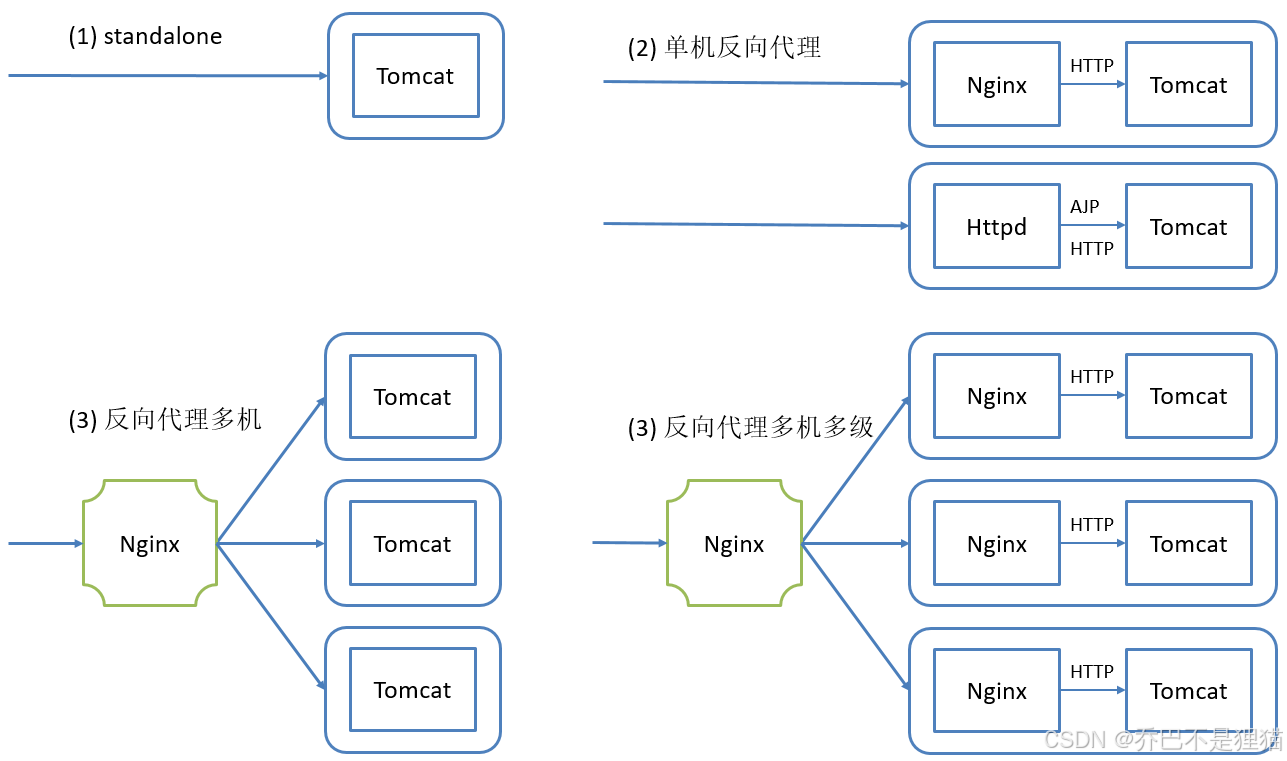
-
standalone模式,Tomcat单独运行,直接接受用户的请求,不推荐
-
反向代理,单机运行,提供一个Nginx作为反向代理,实现动静分离,静态由nginx提供响应,动态由jsp代理给Tomcat
- LNMT:Linux + Nginx + MySQL + Tomcat
- LAMT:Linux + Apache(Httpd)+ MySQL + Tomcat
-
前置一台Nginx,给多台Tomcat实例做反向代理和负载均衡调度,Tomcat上部署的纯动态页面更适合
- Linux + Nginx + MySQL + Tomcat
-
多级代理,
- Linux + Nginx + Nginx + MySQL + Tomcat
实现 Tomcat 负载均衡:
1)IP地址规划:
- Nginx主机: 10.0.0.150(proxy.hui.cn) #作反向代理
- Tomcat主机:10.0.0.200 (t1.hui.cn) ,10.0.0.201(t2.hui.cn) #负载均衡主机
- 在150上实现域名解析:
2)tomcat主机配置
# t1虚拟主机配置 conf/server.xml
<Engine name="Catalina" defaultHost="t1.x.cn">
<Host name="t1.hui.cn" appBase="/data/webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="t1_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
# t2虚拟主机配置 conf/server.xml
<Engine name="Catalina" defaultHost="t2.x.cn">
<Host name="t2.hui.cn" appBase="/data/webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="t2_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
#在t1 t2 上创建相同的测试文件 /data/webapps/ROOT/index.jsp
vim /data/webapps/ROOT/index.jsp
<%@ page import="java.util.*" %>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>tomcat test</title>
</head>
<body>
<div>On <%=request.getServerName() %></div>
<div><%=request.getLocalAddr() + ":" + request.getLocalPort() %></div>
<div>SessionID = <span style="color:blue"><%=session.getId() %></span></div>
<%=new Date()%>
</body>
</html>
3)配置nginx 反向代理
upstream tomcat-server {
hash $cookie_JSESSIONID consistent;
server t1.hui.cn:8080;
server t2.hui.cn:8080;
}
server {
listen 80;
server_name proxy.hui.cn;
location ~* \.(jsp|do)$ {
proxy_pass http://tomcat-server;
}
}
#重启nginx服务并测试
systemctl restart tomcat
http://proxy.hui.cn/index.jsp
4)测试验证
使用window浏览器访问http://proxy.hui.cn/index.jsp,
不开启hash $cookie_JSESSIONID consistent时每次访问SessionID都会变;
启用后,同一台客户端访问时被绑定到某一台tomcat上并实现会话粘性
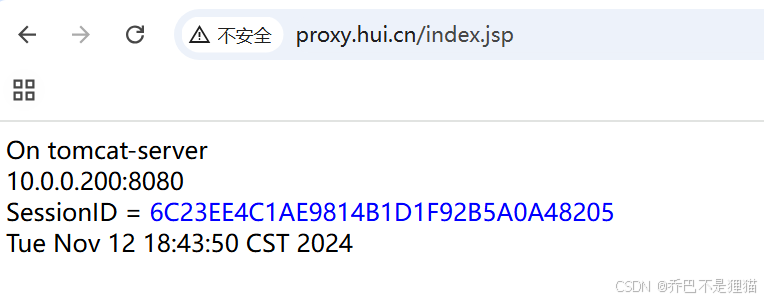
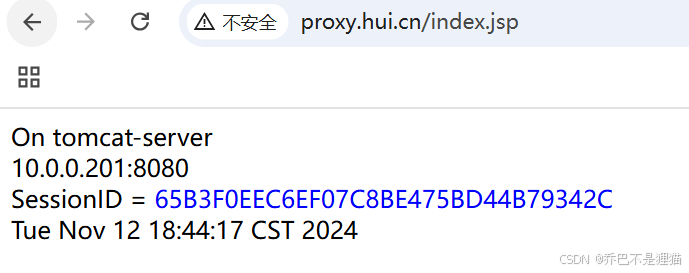
3.总结iptable 5表5链, 基本使用,扩展模块。
1)iptables 中的5表5链
| 表名 | 说明 | 支持的链 |
|---|---|---|
| filter | 过滤规则表,根据预定义的规则过滤符合条件的数据包,默认表 | INPUT,FORWARD,OUTPUT |
| nat | network address translation 地址转换规则表 | PREROUTING,POSTOUTING,INPUT,OUTPUT |
| mangle | 修改数据标记位规则表 | ALL |
| raw | 关闭启用的连接跟踪机制,加快封包穿越防火墙速度 | PREROUTING,OUTPUT |
| security | 用于强制访问控制(MAC)网络规则,由Linux安全模块(如SELinux)实现,很少使用 | INPUT,FORWARD,OUTPUT |
2) 基本使用:
# 清空现有规则
sudo iptables -F
# 允许已建立的连接继续通信
sudo iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
# 允许 SSH 访问
sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT
# 允许 HTTP 访问
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
# 允许 HTTPS 访问
sudo iptables -A INPUT -p tcp --dport 443 -j ACCEPT
# 允许本地回环接口的流量
sudo iptables -A INPUT -i lo -j ACCEPT
# 拒绝其他所有流量
sudo iptables -A INPUT -j DROP
# 保存规则
sudo iptables-save > /etc/iptables/rules.v4
3)扩展模块
- conntrack:用于基于连接状态的匹配,
#允许已建立的连接继续通信
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
- multiport: 以离散方式定义多端口匹配,最多指定15个端口
#允许访问tcp的80,443,8080端口
iptables -A INPUT -p tcp -m multiport --dports 80,443,8080 -j ACCEPT
- iprange:指明连续的ip地址范围
#拒绝10.0.0.10-10.0.0.99 这90个IP
iptables -A INPUT -m iprange --src-range 10.0.0.10-10.0.0.99 -j DROP
- mac:指明源MAC地址,适用于:PREROUTING,FORWARD,INPUT chains
#仅有 mac 地址是00-50-56-C0-00-08 的主机才能访问
iptables -A INPUT -d 10.0.0.150 -m mac --mac-source 00:50:56:C0:00:08 -j ACCEPT
iptables -A INPUT -d 10.0.0.150 -j REJECT
- state: 用于基于连接状态的匹配(已弃用,推荐使用 conntrack)
- connlimit:根据每客户端IP做并发连接数数量匹配,可防止 Dos(Denial of Service,拒绝服务)攻击
#限制并发连接
iptables -A INPUT -m connlimit --connlimit-above 10 -j REJECT
- limit: 用于限制每秒或每分钟的数据包数量,limit 扩展是限制服务器上所有的连接数。
#添加 icmp 放行规则,前10个不处理,后面每分钟放行20个
iptables -A INPUT -p icmp --icmp-type 8 -m limit --limit 20/minute --limit-burst 10 -j ACCEPT
iptalbes -A INPUT -p icmp -j REJECT
- string:对报文中的应用层数据做字符串模式匹配检测
#设置出口规则,在返回的数据包中,跳过前62字节的报文头,如果内容中出现 google,则拒绝返回
iptables -A OUTPUT -m string --algo kmp --from 62 --string "google" -j REJECT
- time:根据将报文到达的时间与指定的时间范围进行匹配
#仅允许在白天SSH访问
iptables -A INPUT -p tcp --dport 22 -m time --timestart 08:00 --timestop 18:00 -j ACCEPT
4.总结iptables规则优化实践,规则保存和恢复。
1)规则优化最佳实践
- 安全放行所有入站和出站的状态为ESTABLISHED状态连接,建议放在第一条,效率更高
- 谨慎放行入站的新请求
- 有特殊目的限制访问功能,要在放行规则之前加以拒绝
- 同类规则(访问同一应用,比如:http ),匹配范围小的放在前面,用于特殊处理
- 不同类的规则(访问不同应用,一个是http,另一个是mysql ),匹配范围大的放在前面,效率更高
- 应该将那些可由一条规则能够描述的多个规则合并为一条,减少规则数量,提高检查效率
- 设置默认策略,建议白名单(只放行特定连接)
- 默认规则(iptables -P)是 ACCEPT,不建议修改,容易出现 “自杀” 现象
- 规则的最后定义规则做为默认策略,推荐使用,放在最后一条
2)iptables 规则保存和加载
#持久化保存
iptables-save > iptables.rule
#加载保存的规则
iptables-restore < ./iptables.rule
5.总结NAT转换原理, DNAT/SDNAT原理,并自行设计架构实现DNAT/SNAT。
1)NAT转换原理
- 源地址转换 (SNAT):当内部网络中的设备发送数据包到外部网络时,NAT 设备会将数据包的源IP地址从内部私有IP地址转换为公共IP地址。
- 目的地址转换 (DNAT):当外部网络中的设备发送数据包到内部网络中的设备时,NAT 设备会将数据包的目的IP地址从公共IP地址转换为内部私有IP地址。
2)实现 DNAT 和 SNAT
架构设计:
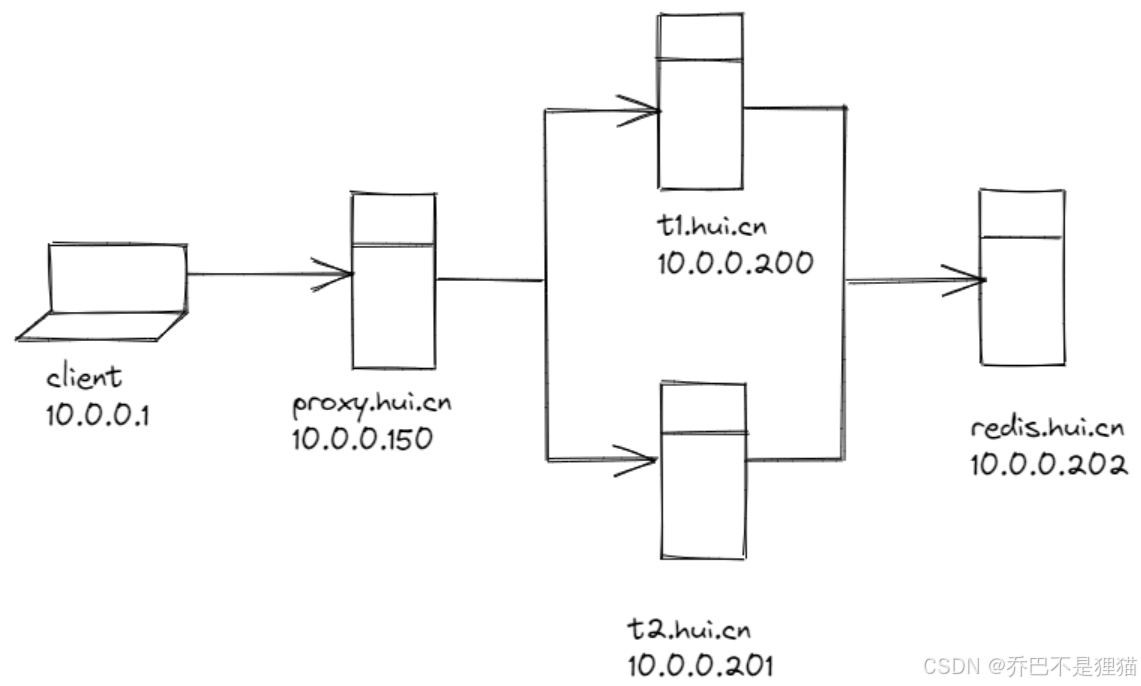
- u150为单NAT网卡,模拟内网环境的客户端。ip: 10.0.0.150/24
- u201模拟防火墙,有NAT与仅主机双网卡。eth0-IP: 10.0.0.201/24 eth1-IP: 192.168.10.201/24
- u200为单仅主机网卡,模拟互联网环境。IP: 192.168.10.200/24
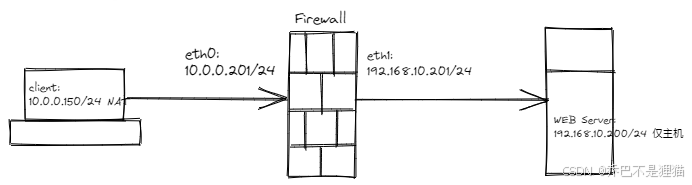
1)修改10.0.0.150主机的网关,指向10.0.0.201

2)防火墙只保留同网段的网关

3)确认开启 ip_forward功能

4)开启u201的tomcat服务,及本机测试web服务
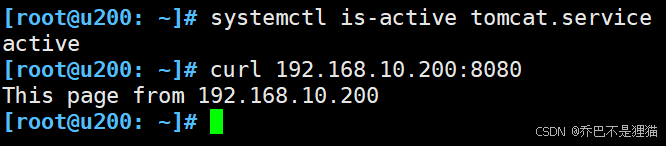
5) 在防火墙主机测试web服务
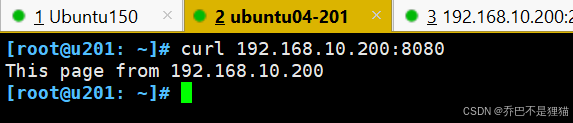
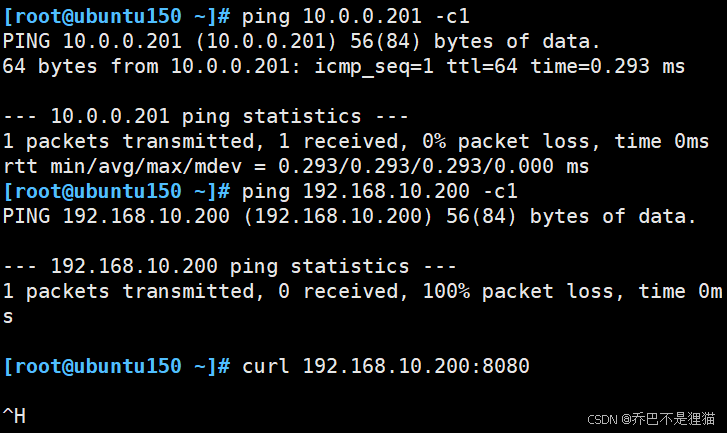
6)在 10.0.0.150 主机上测试
可以PING通防火墙,但是ping不通目标主机,也无法访问
(一)SNAT实现源IP地址转换:
SNAT基于nat表,工作在POSTROUTING链上。
具体是指将经过当前主机转发的请求报文的源IP地址转换成根据防火墙规则指定的IP地址
#在防火墙上添加规则,如果源IP是10.0.0.0/24网段的IP,且目标网段不是10.0.0.0/24,则出去的时候替换成 192.168.10.201
iptables -t nat -A POSTROUTING -s 10.0.0.0/24 ! -d 10.0.0.0/24 -j SNAT --to-source 192.168.10.201
#查看规则
[root@u201: ~]# iptables -t nat -L POSTROUTING
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
SNAT all -- 10.0.0.0/24 !10.0.0.0/24 to:192.168.10.201
测试,10.0.0.150访问192.168.10.200,可以得到返回内容

同时tomcat服务器上跟踪的访问日志显示,访问自己的IP是192.168.10.201。源地址被转换成了 192.168.10.201,实现了SNAT
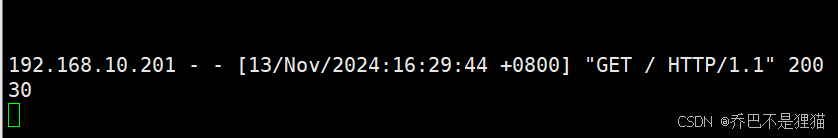
(二)DNAT实现目标IP地址转换
DNAT:目标地址转换,基于nat表,工作在 PREROUTING 链上。
在10.0.0.150上的web服务处理内网,从192.168.10.200上访问不到10.0.0.0网段。
但是可以访问到防火墙上的公网地址:192.168.10.201的80端口。
防火墙自身没有web服务,当有请求访问到防火墙192.168.0.201:80端口,将通过DNAT转发至内网10.0.0.150的80端口上。添加一条规则
#在防火墙上添加规则,在访问192.168.10.201的80端口时,转发到 10.0.0.150的80端口上
iptables -t nat -A PREROUTING -d 192.168.10.201 -p tcp --dport 80 -j DNAT --to-destination 10.0.0.150:80
#查看规则
[root@u201: ~]# iptables -t nat -vnL PREROUTING
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
1 60 DNAT tcp -- * * 0.0.0.0/0 192.168.10.201 tcp dpt:80 to:10.0.0.150:80
测试访问
虽然u200无法ping通10.0.0.0网段,但是可以访问 192.168.10.201的80端口,
根据防火墙的规则,请求被转发给 u150从而得到返回数据,实现了DNAT,目标地址的转换。

6.使用REDIRECT将90端口重定向80,并可以访问到80端口的服务
REDIRECT:重定向,通过定义规则,将收到的数据包转发至同一主机的不同端口
REDIRECT 功能无需开启内核 ip_forward 转发
#REDIRECT 转换的目标地址,工作在PREROUTING链上。添加规则:如果目标地址是10.0.0.150的90端口,就重定向到该主机的80端口
iptables -t nat -A PREROUTING -d 10.0.0.150 -p tcp --dport 90 -j REDIRECT --to-ports 80
7.firewalld常见区域总结。
| Zone | 说明 |
|---|---|
| block | 拒绝所有 |
| dmz | 拒绝除和传出流量相关的,以及ssh预定义服务之外的其它所有传入流量 |
| drop | 拒绝除和传出流量相关的所有传入流量(甚至不以ICMP错误进行回应 |
| external | 拒绝除和传出流量相关的,以及ssh预定义服务之外的其它所有传入流量,属于external zone的传出ipv4流量的源地址将被伪装为传出网卡的地址。 |
| home | 拒绝除和传出流量相关的,以及ssh,mdsn,ipp-client,samba-client,dhcpv6-client预定义服务之外其它所有传入流量 |
| internal | 和home相同 |
| public | 拒绝除和传出流量相关的,以及ssh,dhcpv6-client预定义服务之外的其它所有传入流量,新加的网卡默认属于public zone |
| trusted | 允许所有流量 |
| work | 拒绝除和传出流量相关的,以及ssh,ipp-client,dhcpv6-client预定义服务之外的其它所有传入流量 |
8.通过ntftable来实现暴露本机80/443/ssh服务端口给指定网络访问
#创建表和链
sudo nft add table ip filter
sudo nft add chain ip filter input { type filter hook input priority 0 \; }
#添加规则
sudo nft add rule ip filter input ip saddr 192.168.1.0/24 tcp dport 80 accept
sudo nft add rule ip filter input ip saddr 192.168.1.0/24 tcp dport 443 accept
sudo nft add rule ip filter input ip saddr 192.168.1.0/24 tcp dport 22 accept
#保存规则
sudo nft list ruleset > /etc/nftables.conf
#加载规则
sudo nft -f /etc/nftables.conf
9.完成 nginx 反向代理 tomcat实现基于redis会话复制的集群构建
1)架构设计和IP 地址规划
相关 tomcat 安装和 nginx 反向代理配置,已经在前边做过,以此为基础;
只需要配置两台tomcat使用redis来存储SessionID即可。
Nginx配置中注释掉会话保持的配置行
#hash $cookie_JSESSIONID consistent;
2)安装并配置Reids服务
apt update && apt -y install redis
sed -i.bak 's/^bind.*/bind 0.0.0.0/' /etc/redis/redis.conf
systemctl enable --now redis
3)上传redis库到tomcat服务器并配置Tomcat
将以下jar包上传到 tomcat服务器的/usr/local/tomcat/lib/目录下
kryo-3.0.3.jar
asm-5.2.jar
objenesis-2.6.jar
reflectasm-1.11.9.jar
minlog-1.3.1.jar
kryo-serializers-0.45.jar
msm-kryo-serializer-2.3.2.jar
memcached-session-manager-tc8-2.3.2.jar
spymemcached-2.12.3.jar
memcached-session-manager-2.3.2.jar
修改两台tomcat 的配置文件指定redis服务器地址
vim /usr/local/tomcat/conf/context.xml
<Context>
...
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="redis://10.0.0.202:6379"
sticky="false"
sessionBackupAsync="false"
lockingMode="uriPattern:/path1|/path2"
requestUriIgnorePattern=".*\.(ico|png|gif|jpg|css|js)$"
transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory"
/>
</Context>
systemctl restart tomcat
4)测试访问
浏览器刷新访问多次,主机轮询,但SessionID不变
10.总结 JVM垃圾回收算法和分代
1)JVM垃圾回收算法
-
Mark-Sweep(标记清除)
分垃圾标记阶段和内存释放两个阶段- 标记阶段,找到所有可访问对象打个标记。清理阶段,遍历整个堆
- 对未标记对象(即不再使用的对象)逐一进行清理
优点: 算法简单
缺点:标记-清除最大的问题会造成内存碎片,但是不浪费空间,效率较高(如果对象较多时,逐一删除效率也会受到影响)
-
Mark-Compact (压缩)
分垃圾标记阶段和内存整理两个阶段- 标记阶段,找到所有可访问对象打个标记。
- 内存清理阶段时,整理时将对象向内存一端移动,整理后存活对象连续的集中在内存一端。
优点:标记-压缩算法好处是整理后内存空间连续分配,有大段的连续内存可分配,没有内存碎片。
缺点:内存整理过程有消耗,效率相对低下
-
Coping (复制)
先将可用内存分为大小相同两块区域A和B,每次只用其中一块,比如A。当A用完后,则将A中存活的对象复制到B。复制到B的时候连接的使用内存,最后将A一次性清除干净。
优点:没有碎片,复制过程中保证对象使用连续空间,且一次性清除所有垃圾,所以即使对象很多,收回效率也很高。
缺点:比较浪费内存,只能使用原来一半内存,因为内存对半划分了,复制过程也有代价。
2)多种算法总结:
- 按效率:复制算法 > 标记-清除算法 > 标记-压缩算法
- 按内存整齐度:复制算法 = 标记-压缩算法 > 标记-清除算法
- 内存利用率: 标记-压缩算法 = 标记-清除算法 > 复制算法
3)分代:
Heap 内存空间分为三个不同类别:年轻代、老年代、永久代
Heap堆内存分为
- 年轻代Young:Young Generation
- 伊甸园 eden:只有一个,刚刚创建的对象
- 幸存(存活)区 Servivor Space:有2个幸存区,一个是 from区,一个是to区。大小相等、地位相同、可互换。
- from 指的是本次复制数据的源区
- to 指的是本次复制数据的目标区
- 老年代Tenured:Old Generation,长时间存活的对象
默认空间大小比例:
默认JVM试图分配最大内存的总内存1/4,初始化默认总内存为总内存的1/64,年青代中heap的1/3,老年代占2/3
永久代:JDK1.7之前使用,Method Area方法区;JDK1.8后改名为 MetaSpace,此空间不存在垃圾回收,此空间物理上不属于heap内存,但逻辑上存在于heap内存
- 永久代必须指定大小限制,字符串常量JDK1.7存放在永久代,1.8后存放在heap中
- MetaSpace 可以设置,也可不设置,无上限
年轻代:存活时长低,适合复制算法
老年代:区域大,存活时长高,适合标记-压缩算法
JVM 1.8 默认的垃圾回收器:Parallel GC(也称为吞吐量收集器),所以大多数都是针对此进行调优
Parallel GC它是一个并行的年轻代收集器,旨在最小化垃圾回收对应用吞吐量的影响。
JVM 11、17 默认的垃圾回收器:G1
G1(Garbage First) 旨在提供更高的应用程序响应速度,同时避免长时间的垃圾回收停顿。它通过将堆划分为多个大小相等的区域(regions),并优先回收垃圾最多的区域来实现这一目标。

















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









