






检索增强生成和上下文提示大语言模型在飞机工程中的应用
2025_Retrieval-Augmented Generation and In-Context Prompted Large Language Models in Aircraft Engineering
https://arc.aiaa.org/doi/10.2514/6.2025-0700
摘要/介绍
针对飞机工程领域中的QA任务
比较了当前最有效和最流行的三种大语言模型问题解答提示方法——大语言模型零-shot提示、大语言模型上下文提示和基于大语言模型的检索增强生成(RAG)
描述了一个新的低量、高质量的基准飞机设计QA数据集(AeroEngQA),并利用该数据集定性评估每一类大语言模型,探讨其在答案准确性和简洁性等方面的特性
相关工作
QA数据集
数据集结构:
最广泛使用的数据集可能是SQUAD2 [11],其中包含10万个基于维基百科文章的问题,由众包工人提出,其中一半的问题故意设计为不可回答。QA对由一个问题、一篇包含足够信息来回答该问题的维基百科文章,和一个标准答案组成。
QA任务的评估指标通常采用定量、定性或混合方法:
对于定量QA评估 ,将标准答案文本与预测的答案文本进行比较,并计算如精确匹配(Exact Match)和F1得分等指标。精确匹配得分是正确答案的比例,正确答案是指预测答案的所有字符完全匹配标签真值答案。F1得分是精确度和召回率指标的混合,使用字符级别的真实正例计数进行计算,这些计数对所有与真值答案字符重叠的预测答案字符进行评分。因此,F1得分允许模型得出几乎正确的答案,或者完全正确的答案,但可能会包含一些额外字符,如解释、语法或仅仅是空格字符。
对于定性评估,通常通过专家使用预先商定的评分方案对随机样本的答案进行评分,这些方案通常是任务特定的。理想情况下,应该有一个专家团队,以便讨论人类判断的差异并找到共识得分。但由于涉及人工劳动,它通常仅限于QA数据集的一小部分。定量评估虽然不如定性评估真实,但可以覆盖整个QA数据集。
提出了自己的数据集:
通过一个由四名航空航天专家组成的团队,从一个真实的公共航空航天文献库中提取了80个问题和答案,这些文献包括NASA、NTSB报告和工程专利。
基于LLM的问答模型
为了执行QA,LLM必须通过提示进行引导,提示方式包括零-shot提示(直接提问)或上下文提示(提供几个问题应该如何回答的例子,作为零-shot提示的补充)
RAG,比较熟悉了,不再介绍
方法
AeroEngQA的构建
数据来源:
1.上下文是从公共领域的文档中提取的
2.标注团队由本文的四位作者组成,代表了不同的工程研究和工业经验。每位标注者都持有工程学位,其中三位团队成员还拥有工程学博士学位。
分类:
1.单跳问题(简单推理)
2.多跳问题(复杂推理,涉及桥接实体)
此外,测试数据集包括可回答和不可回答的问题
多跳可回答问题的示例:

AeroEngQA****中的一个多跳可回答问题示例,突出显示了推理桥接实体(蓝色)和正确答案(从上下文中提取,黄色)。问题引用的上下文元素以绿色突出显示,方便阅读;请注意,问题中的措辞不必与上下文中的措辞完全相同(与答案不同,答案是直接从上下文中提取的)。
构建原则:
提出了关于上下文选择,问题指定,答案指定等规则
LLM的操作模式
考虑上面提到的三种基本的LLM操作模式
1.零-shot提示的LLMs(GPT3.5_turbo_zeroshot, GPT4_turbo_zeroshot)
在这种模式下,LLM模型给定一个任务描述或问题,且没有提供任何解决问题的示例。模型预计基于其已有的知识和语言理解生成一个回答。该模式下不会对LLM进行任务特定的微调。这是最简单的提示形式,因为它不需要额外的训练数据,因此成本效益高且时间效率高。然而,可能的缺点(我们在这里进行调查)是,这种方法可能会导致不够准确或不太符合上下文的回答,特别是在复杂或领域特定的任务中。模型的表现可能会不稳定或不可预测,因为它高度依赖于模型的现有知识和理解。
单跳示例:

多跳示例:

2.上下文提示的大语言模型(GPT3.5_turbo_in_context,GPT4_turbo_in_context)
上下文提示(In-context prompting),也称为少样本提示(few-shot prompting),是指在提示语中向模型提供一个或多个任务示例。这些示例作为上下文,帮助模型理解任务并基于所提供的示例生成回答。虽然这种提示方式在构造提示语方面稍显复杂(因为需要收集和筛选相关的训练示例),但其设计目的是提高模型性能的稳健性。

我们开发了一个 Python 脚本。该脚本可无缝集成 OpenAI 的 GPT-3.5 Turbo 与 GPT-4 Turbo 模型,根据提供的上下文内容自动生成问题回答。脚本首先使用适当的 API 密钥初始化 OpenAI 客户端,并指定所使用的模型。随后,脚本会遍历包含上下文与问题的 JSON 文件列表。针对每条数据,脚本分别为零样本(zero-shot)和上下文提示(in-context)场景构建提示语,将上下文与问题嵌入其中。这些提示语随后通过 OpenAI API 提交给 GPT 模型以获取响应。获取到的回答会与原始数据一同系统性地存储,便于实现自动化的问答生成。
3.检索增强生成(RAG_zero_shot; RAG_in_context)
使用了一个开源Python框架来构建与大型语言模型的自定义应用,名为Haystack[33]。Haystack包含了构建RAG系统所需的组件。

1.所有问题的测试数据集上下文被发送到Haystack文档存储。为此,我们使用了一个文档连接器将它们拼接起来,清理后使用文档分割器确保检索的内容大小不超过上下文窗口大小。分割器参数被设置为250个token切片,切片之间有50个token的重叠。分割后的文档被嵌入并写入存储。为了简化操作,我们使用了内存存储,并为每个实验重新创建它,因为文档的大小足够小。
为了在文档存储中找到相关内容,我们将测试数据集中的每个问题进行嵌入,并与存储的内容进行比较。使用Sentence-BERT[34]作为评分机制,采用transformer模型all-MiniLM-L6-v2来获取存储和问题特征向量之间的余弦相似度作为语义匹配度。对于每个问题,检索出十个最佳匹配的文档切片,并按语义相似度排序。然后过滤该列表,使得每个成员的得分至少为最佳语义匹配得分的60%。这导致的结果集大小在1到10个成员之间变化,具体取决于问题;只选择与存储内容最匹配的内容。
经过上述两步,有了一个问题和匹配内容的上下文
下一步是使用Jinja2模板语言创建一个提示。用了与零-shot和In-context实验相同的提示进行比较。我们使用的LLM是Llama3 70B Instruct[35],通过Ollama[36] API作为封装器操作。
第一次运行的结果以json和Excel文件的形式收集。答案与其他结果一起手动标记。
第二次运行通过测试数据集进行,这次在错误回答的问题处停止脚本。检查是否是信息检索(IR)未能找到包含答案的相关部分,或者是否IR检索到了多个答案。在这种情况下,这些事件在结果文件中进行了标记。
实验/结果
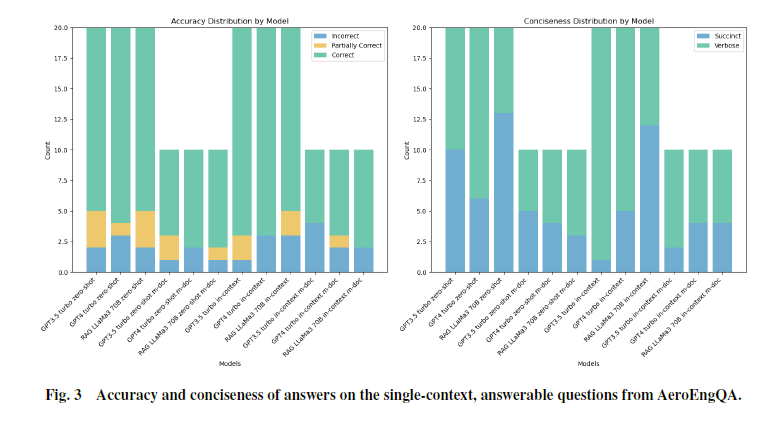
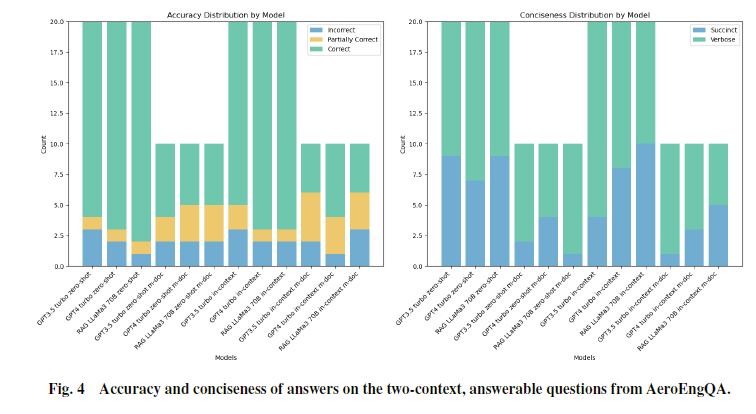
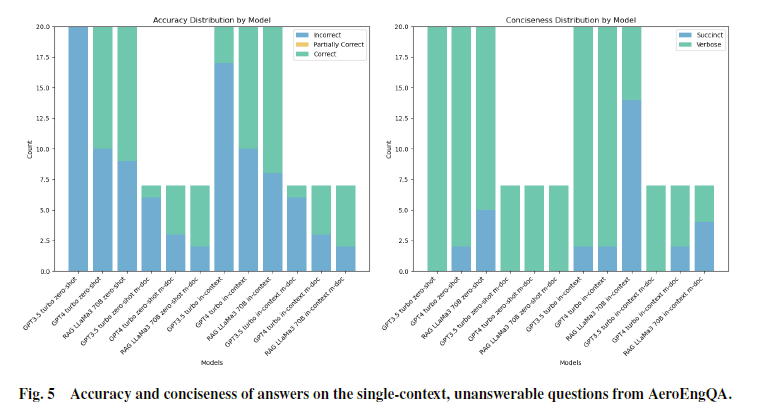
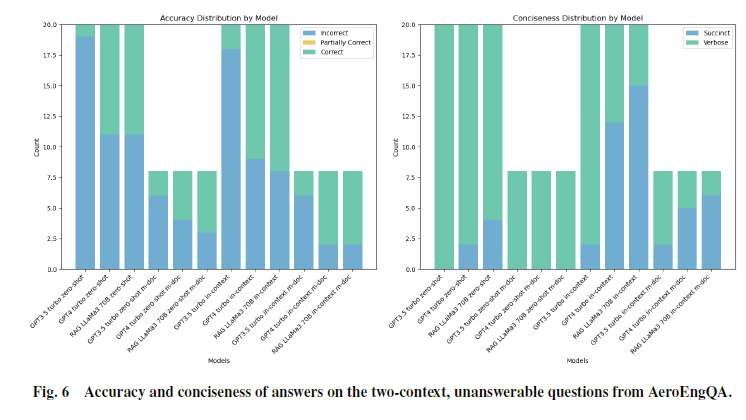
该编码方案基于两个维度的指标:答案准确性 和 答案简洁性。
准确性方面:采用了“错误”“部分正确”“正确”三种枚举类型进行分类。部分正确包括以下两种情况:一是答案只包含了部分参考答案内容;二是答案虽然包含参考答案,但同时添加了多余内容,导致读者产生混淆。
答案简洁性方面,我们使用了“简洁(simple)”和“冗长(verbose)”两种类型,如果答案明显长于标准参考答案,就被标记为冗长。
单跳可回答:
多跳可回答:
单跳不可回答:
多跳不可回答:
总结
1.通过上下文提示给LLMs提供示例似乎能提高整体准确率,平均提高大约5%到10%(尤其是在不可回答的问题上)
2.单跳和多跳推理问答对的表现相似,在生成较难的多跳答案时准确率略有下降。这表明推理难度可能不是LLM在工程问答任务中性能的瓶颈。
3.在多跳推理中,RAG方法实际上超越了非RAG模型。
4.所有类别的LLM倾向于提供冗长的答案,并包含大量不必要的文本。RAG模型略显简洁
5.在没有答案的情况下表现得很困难,常常试图从上下文中虚构一个接近但不完全正确的答案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









