



 本文详细介绍了如何在Windows虚拟机上搭建Spark环境,包括安装和配置JDK、Scala、Python3.7、Hadoop2.7,以及配置Hadoop和安装Spark2.4.5的步骤。特别强调了版本兼容性和避免安装到C盘的重要性。
本文详细介绍了如何在Windows虚拟机上搭建Spark环境,包括安装和配置JDK、Scala、Python3.7、Hadoop2.7,以及配置Hadoop和安装Spark2.4.5的步骤。特别强调了版本兼容性和避免安装到C盘的重要性。
1.前言
2.安装jdk配置java环境
3.安装scala语言
4.安装Python3.7
5.安装hadoop2.7
6.配置hadoop
7.安装spark2.4.5
8.验证成果
1.前言
对于一个刚刚迈入数据领域的小白、大学生而言,可能有很多人和我一样,面对这种搭建平台知识懵懵懂懂,摸不到头绪,摸爬滚打,在无尽的报错和反复尝试受尽了折磨!

在spark搭建之前,有很多的准备工作,你会明白搭建spark不只是搭建spark这么简单。
下面我们一起尝试这走出这片苦海!
对于一个全新的windows虚拟机,我们需要安装很多前提条件,如果你的虚拟机有jdk、python、hadoop,也需要对准好对应版本,他们大多数兼容性很差,稍有不慎就会出现报错,
很重要一点就是千万千万别把相应的软件安装到c盘不然后面步骤中会报错
步入正题:
首先我们要明确我们的步骤,知道自己要干什么,怎么做
1.spark的搭建需要依赖的java的环境基础,因此我们先需要下载一个jdk,并配置环境变量
2.安装scala语言,其实我也不明白为什么要安装这个东西,后面好像也没用到过
3.因为我们最后运用的是pyspark,所以要安装python,spark也是很依赖python的
4.安装hadoop,这个需要选择好版本,与spark版本是对应的,如果不能对应好版本,那你只能从头再来了
5.最后我们就可以真正地安装spark了
2.安装jdk配置java环境
在这里我建议大家在官网安装jdk17版本,虽然常用的是jdk8版本,但是我总感觉这个版本一旦安装出错就很难删除了,此外过程中需要注册一个甲骨文公司账号,不然是无法在官网正规下载的
https://www.oracle.com/java/technologies/downloads/#jdk17-windows(保姆级别)
建议安装到除c盘之外的其他盘
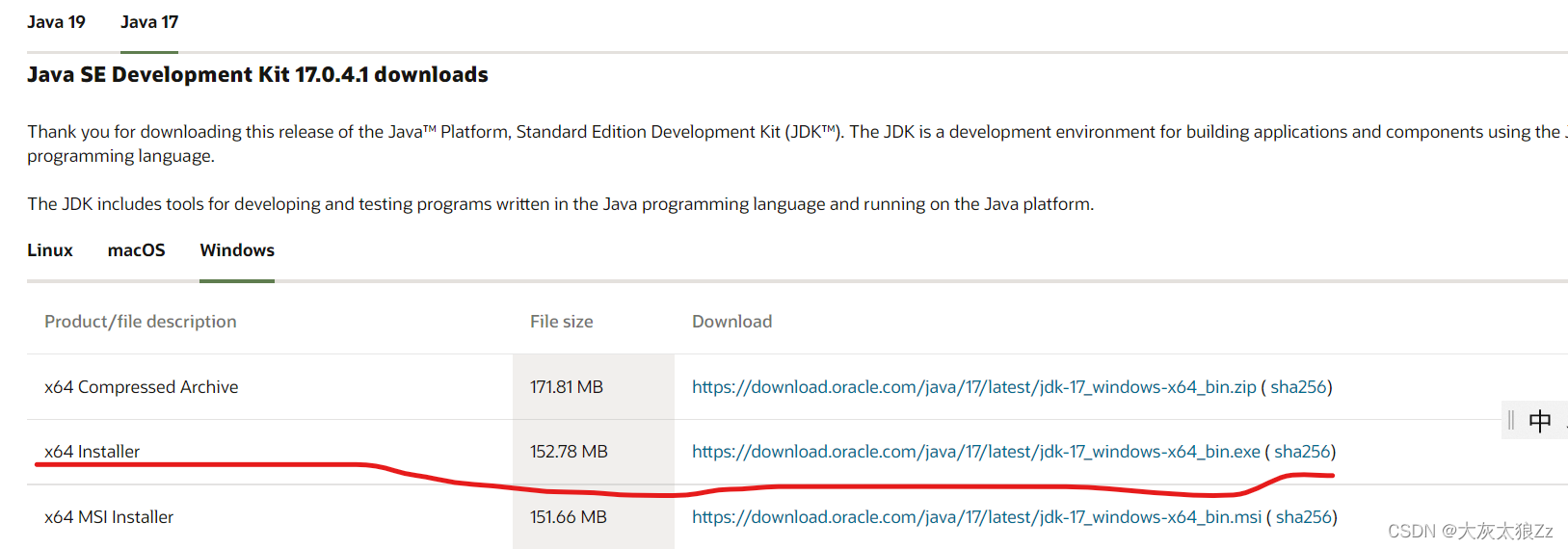
下面我们配置环境>>>>>>
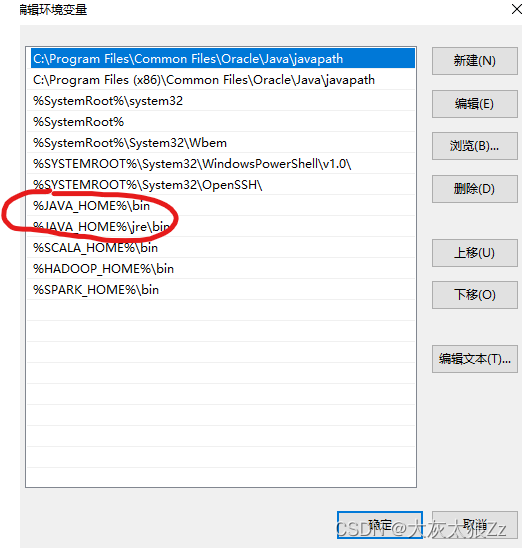
打开此电脑>右击属性>右侧最下面高级系统设置>环境变量
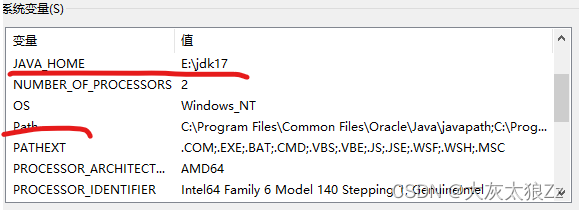
这里的值就写自己jdk安装的地址就可以了
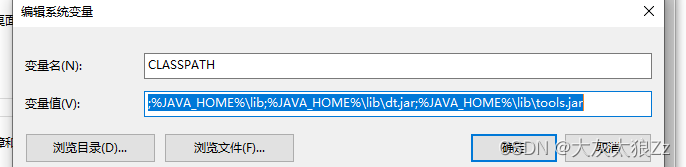
除此之外我们还要建一个CLASSPATH变量,内容如下:
这样我们的java环境就配置好了,可以win+R打开命令提示符cmd,输入
javac -version

这一步就成功了🎉🎉🎉
3.安装scala
这里按我安装的来吧scala2.12.1
https://scala-lang.org/download/2.12.1.html
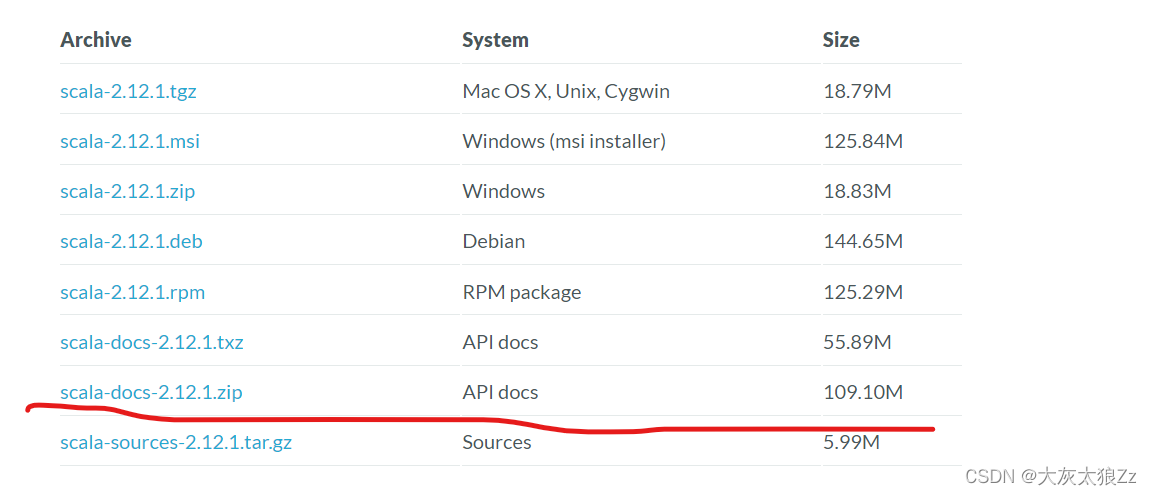
这个就是傻瓜式安装,注意不要装C盘
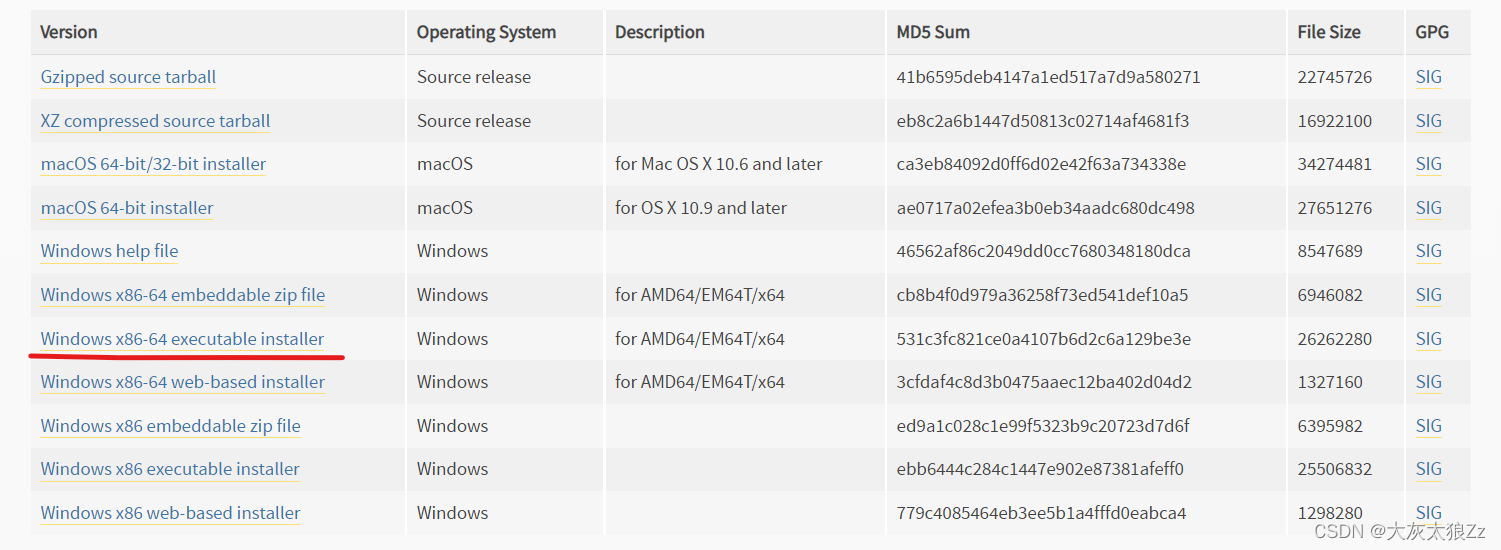
4.安装Python3.7
https://www.python.org/downloads/release/python-370/
不要装到C盘就好
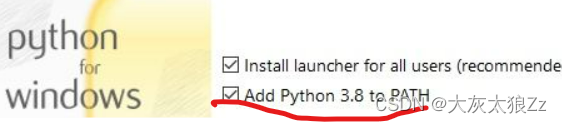
python的环境变量是不需要自己去配置的,只需要在最后,勾选一个选项就行,划线的这句话的意思就是配置python3.8环境变量,当然我们是3.7版本就是Add Python 3.7 to PATH
5.安装Hadoop2.7
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
不要装C盘,安装时注意,最好不要安装到带有空格的路径名下,例如:Programe Files,不然会报错,这对我来说也是个铁的教训
这个也比较简单我就直接跳过了😁
6.配置Hadoop
这个相对来说比较困难,首先说说为什么要重新配置Hadoop吧。这个东西很奇怪它其实在linux系统中也没这么多事,但是它好像不喜欢待在windows里面,也可以说是Hadoop不属于windows这个大环境,对于专业的知识讲解等博主下次科普好了再讲给大家。所以我们需要改变以下它的特征,让它适应windows自然
我们首先去这为大佬家下载我们需要的配置文件
https://github.com/steveloughran/winutils
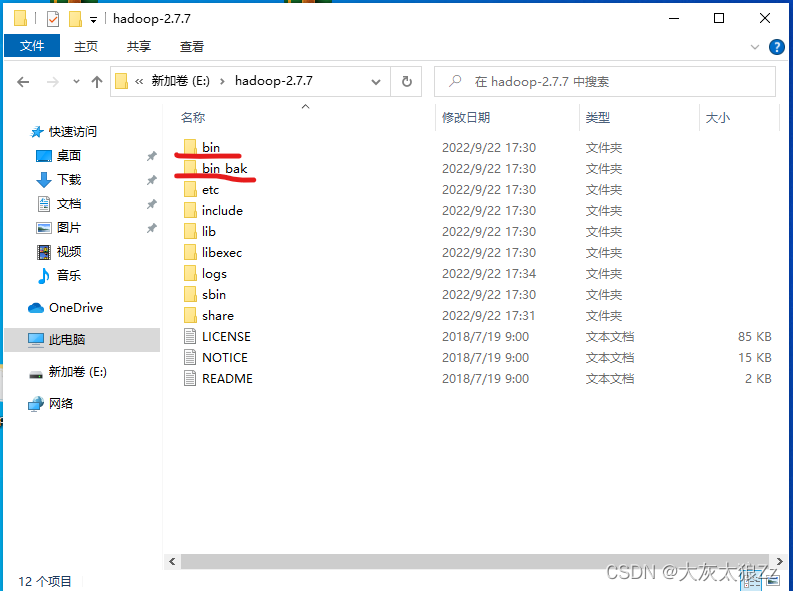
在里面找到hadoop2.7版本,将其下面的bin文件夹复制到hadoop文件夹内
原来的bin文件夹改名为:bin_bak
修改hadoop-2.7.7\etc\hadoop下的hadoop-env文件,将原来的配置改为:
这个地方瞄准文件右击编辑
(这个地方弄自己的jdk下载的地址)
set JAVA_HOME= D:\Java\jdk1.8.0_45
下面就是配置环境变量了,直接上截图
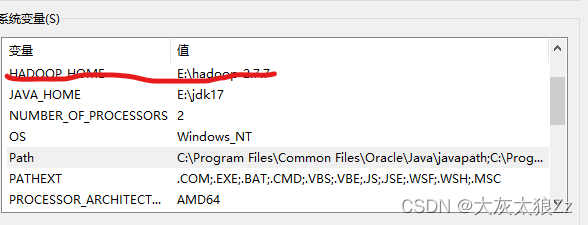
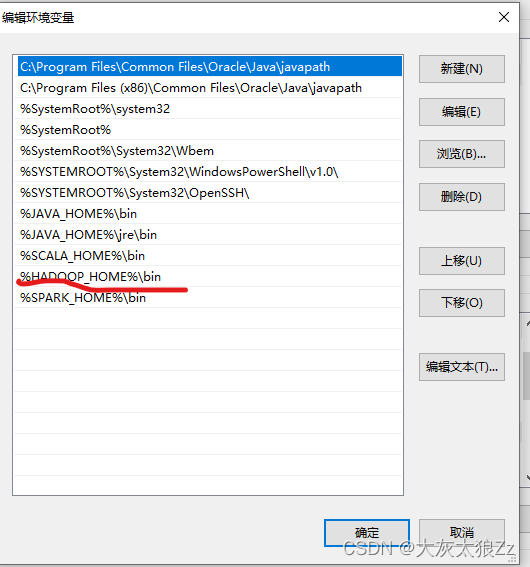
然后就可以进行我们的验证操作了:
命令提示符,输入
hadoop version 7.安装spark2.4.5
7.安装spark2.4.5
下载Spark: https://archive.apache.org/dist/spark/spark-2.4.5/
一定要对应好这个版本,它和上面hadoop是亲兄弟,分不开
![]()
然后我们配置环境:
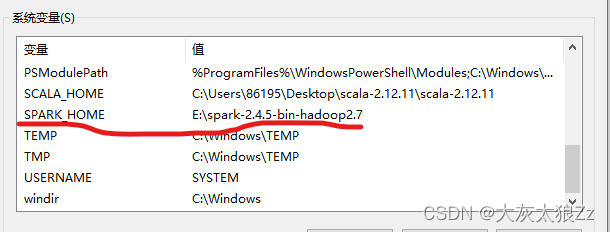
还有就是系统变量里面的path
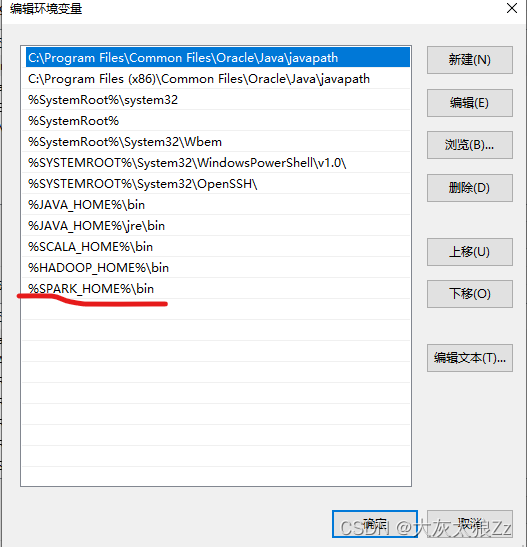
最后,我们就可以最后一步去验证了:
win+r>cmd>输入:pyspark
pyspark如果在命令提示符中出现这个大大的spark就证明我们终于成功了🤣🤣🤣
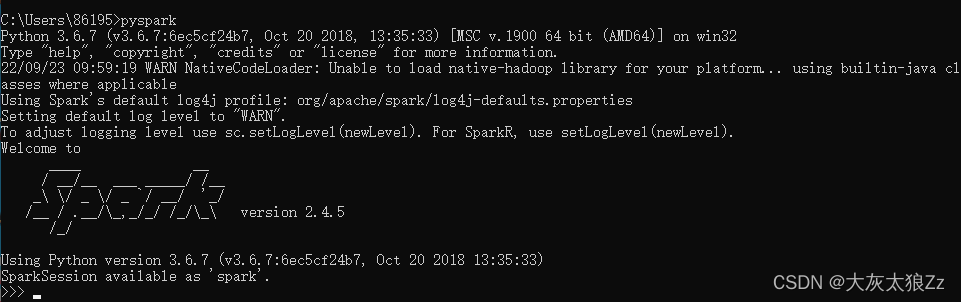
到此我们的spark就算搭建成功了,第一次写技术博客而且还是一个大学生, 如果出现各种问题,欢迎评论区积极评论,我会尽最大努力不断完善作品,解决问题。有什么不足的地方,也希望大佬们指点一二,继续学习完善自己😘😘😘

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









