







其他异常
1 服务器发生 CPU 大量 sys 占用问题的原因
问题现象
数据库在运行过程中,因为某些原因出现大量的 CPU sys 占用,进而导致数据库
性能问题。这类问题应该如何去排查?有哪些已知的原因可能导致这类问题的发
生?
解决方法
通常 cpu 出现大量的 sys 占用是由于资源争抢导致的,如锁资源的争抢、内存的
争抢。可用于监控、分析的工具有 perf、nmon 等。
GBase8a 集群出现 sys 占用高的几个已知问题原因有:
操作系统的 NUMA 参数未关闭,在内存紧张情况下可能导致频繁的内存换入
换出导致 sys 高。
gnode 层的参数设置不合理
_gbase_dc_window_size 设置过小,该参数是可缓存到内存的 DC 数,当需要
缓存的实际数据量超过设置的 DC 数时,就可能导致 sys 占用。
_gbase_insert_malloc_size_limit 设置过小
在 insert select 场景中,如果存在较大的 varchar 列,如 varchar(2000),会导
致每行或每几行申请一次内存,内存频繁申请出现 sys 占用。
2 更新 500 亿大表全文索引导致 gbased oom
问题现象
GBase 8a 集群更新 500 亿大表全文索引时报错,全文索引更新语句:UPDATE I
NDEX"IX_RG010005"ON"horus"."rwa_source_0001",企业管理器报错:gclust
er table error:Server shutdown in progress。
原因分析
初步判断为更新记录太大导致内存爆满,gbased 进程被系统重启了。全文默认参
数是支持增量更新的,会在索引过程中持有字典,大批量一次更新会导致内存吃
紧,可以设置 gbfticfg.xml 配置文件中的参数 reduceMemoryMode 为 1 解决。
解决方法
不调整全文检索常驻内存参数(常驻内存),测试更新 500 亿大表全文索引,复
现了类似操作系统重启的情况。集群第 1 个节点系统 crash 日志显示 gbased 引起
oom panic,进而导致系统 reboot。
同时验证将常驻内存参数 reduceMemoryMode 设为 1(不常驻内存),更新 500
亿大表全文索引(4 个字段),都操作成功,未出现系统异常。
3 审计日志中 JDBC 程序执行的 sql 语句 conn_type字段显示为空,没有显示出 JDBC
问题现象
审计日志中 JDBC 程序执行过的 sql,在 audit_log 的 conn_type 字段显示为空,没
有显示出 JDBC。
原因分析
之前有一个兼容的需求,增加了一个参数,默认关闭,不向 server 提供连接类型。
可以在 jdbc 的连接串中设置打开该参数 useConnectionFlag=true。
解决方法
在 jdbc 的连接串中设置打开该参数 useConnectionFlag=true 后测试,审计日志中
能够体现出 java 程序连接的类型是 JDBC。
4 开启资源管理计划之后删除用户受限
问题现象
开启资源计划的情况下删除用户,报错 ERROR 1268 (HY000): Cannot drop one
or more of the requested users。
停止资源计划后,没有将用户从消费组中删除时,删除用户报错 ERROR 1758 (H
Y000): gcluster dal error: Operation DROP USER failed for'u01'@'%'.。
解决方法
测试发现,开启资源计划的情况下,对于明确添加到 consumer group 的用户,需
要停止资源计划,并将用户从消费组中删除,用户才可以被删除;
其他默认属于 default_consumer_group 组的用户,需要停止资源计划,用户才可以
被删除。
这是资源管理的使用限制:
用户放到用户组后,用户不允许删除;
在启用资源计划后,用户不能脱离用户组的关联关系;
这些限制是由于已经分配给该用户的系统资源,例如 cgroup 分组、内存等的动态
回收,以及实现上存在单一指令,多点操作的一致性问题。
5 使用 gccli 客户端创建存储过程未保留注释
问题现象
使用 gccli 客户端创建存储过程包含注释,但是执行 show create procedure 注释没
有显示。
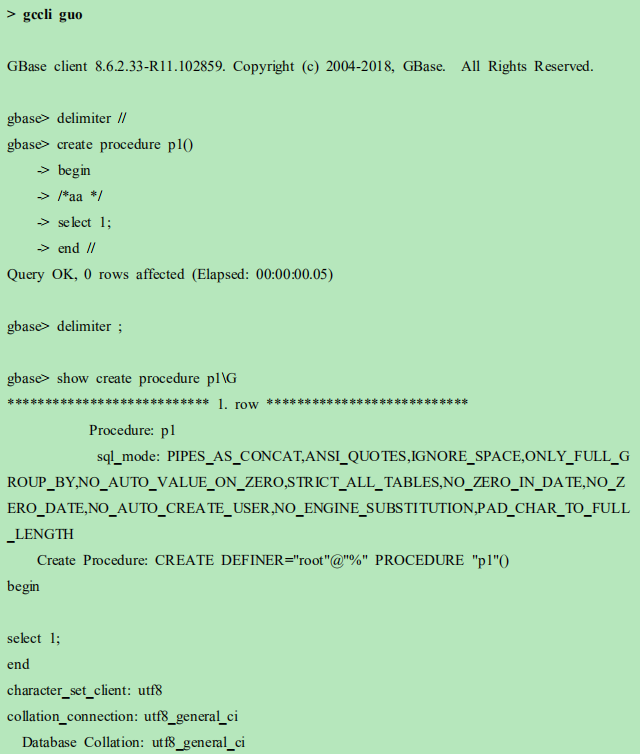

解决方法
gccli-c 保留存储过程中的注释。


6 全文索引更新处理时报错
问题现象
全文索引更新,处理时报错
查看 express.log,gcluster 层有如下的异常信息:

解决方法
全文默认参数是支持增量更新的,会在索引过程中持有字典,大批量一次更新会导致内存吃紧,可以
设置 gbfticfg.xml 配置文件中的参数 reduceMemoryMode 为 1 解决。
全文配置如下:

7 节点异常后执行 delete 与 shrink space 操作,数据文件有残留
问题现象
某一个节点异常后,执行 delete 与释放空间操作,查看数据文件有残留(存在两
份数据)。
原因分析
集群环境下,如果某一gnode 节点不在线,之后依次执行了 dml(如 delete 操作)、
shrink space 操作,当该节点上线后触发集群同步操作会导致该节点的 seg 文件可
能出现 A、B 版本都存在的情况,属正常现象;因为集群先处理 ddl(shrink space,
由于没有 delete 数据此时不做任何处理),再处理 dml 触发同步。















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









