









http://blog.csdn.net/acdreamers/article/details/44672305
今天要讲的主要内容是协同过滤,即Collaborative Filtering,简称CF。
Contents
1. 协同过滤的简介
2. 协同过滤的核心
3. 协同过滤的实现
4. 协同过滤的应用
1. 协同过滤的简介
关于协同过滤的一个最经典的例子就是看电影,有时候不知道哪一部电影是我们喜欢的或者评分比较高的,那
么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。在问的时候,都习惯于问跟自己口味差不
多的朋友,这就是协同过滤的核心思想。
协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,在协同过滤中,这些用户成为邻居,然后根据他
们喜欢的东西组织成一个排序的目录推荐给你。所以就有如下两个核心问题
(1)如何确定一个用户是否与你有相似的品味?
(2)如何将邻居们的喜好组织成一个排序目录?
协同过滤算法的出现标志着推荐系统的产生,协同过滤算法包括基于用户和基于物品的协同过滤算法。
2. 协同过滤的核心
要实现协同过滤,需要进行如下几个步骤
(1)收集用户偏好
(2)找到相似的用户或者物品
(3)计算并推荐
收集用户偏好
从用户的行为和偏好中发现规律,并基于此进行推荐,所以如何收集用户的偏好信息成为系统推荐效果最基础
的决定因素。用户有很多种方式向系统提供自己的偏好信息,比如:评分,投票,转发,保存书签,购买,点
击流,页面停留时间等等。
以上的用户行为都是通用的,在实际推荐引擎设计中可以自己多添加一些特定的用户行为,并用它们表示用户
对物品的喜好程度。通常情况下,在一个推荐系统中,用户行为都会多于一种,那么如何组合这些不同的用户
行为呢 ?基本上有如下两种方式
(1)将不同的行为分组
一般可以分为查看和购买,然后基于不同的用户行为,计算不同用户或者物品的相似度。类似与当当网或者
亚马逊给出的“购买了该书的人还购买了”,“查看了该书的人还查看了”等等。
(2)不同行为产生的用户喜好对它们进行加权
对不同行为产生的用户喜好进行加权,然后求出用户对物品的总体喜好。
好了,当我们收集好用户的行为数据后,还要对数据进行预处理,最核心的工作就是减噪和归一化。
减噪: 因为用户数据在使用过程中可能存在大量噪音和误操作,所以需要过滤掉这些噪音。
归一化:不同行为数据的取值相差可能很好,例如用户的查看数据肯定比购买数据大得多。通过归一化,才能
使数据更加准确。
通过上述步骤的处理,就得到了一张二维表,其中一维是用户列表,另一维是商品列表,值是用户对商品的喜
好。还是以电影推荐为例,如下表
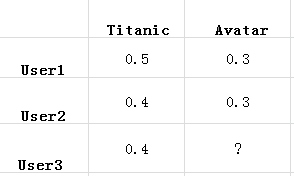
找到相似的用户或物品
对用户的行为分析得到用户的喜好后,可以根据用户的喜好计算相似用户和物品,然后可以基于相似用户或物
品进行推荐。这就是协同过滤中的两个分支了,基于用户的和基于物品的协同过滤。
关于相似度的计算有很多种方法,比如常用的余弦夹角,欧几里德距离度量,皮尔逊相关系数等等。而如果采
用欧几里德度量,那么可以用如下公式来表示相似度
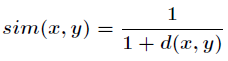
在计算用户之间的相似度时,是将一个用户对所有物品的偏好作为一个向量,而在计算物品之间的相似度时,
是将所有用户对某个物品的偏好作为一个向量。求出相似度后,接下来可以求相似邻居了。
计算并推荐
在上面,我们求出了相邻用户和相邻物品,接下来就应该进行推荐了。当然从这一步开始,分为两方面,分别
是基于用户的协同过滤和基于物品的协同过滤。我会分别介绍它们的原理
(1)基于用户的协同过滤算法
在上面求相似邻居的时候,通常是求出TOP K邻居,然后根据邻居的相似度权重以及它们对物品的偏好,
预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表进行推荐。
(2)基于物品的协同过滤算法
跟上述的基于用户的协同过滤算法类似,但它从物品本身,而不是用户角度。比如喜欢物品A的用户都喜
欢物品C,那么可以知道物品A与物品C的相似度很高,而用户C喜欢物品A,那么可以推断出用户C也可能
喜欢物品C。如下图
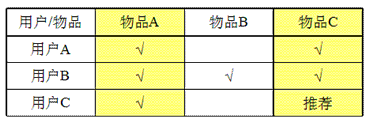
上面的相似度权重有时候需要加入惩罚因子,举个例子,在日常生活中,我们每个人购买卫生纸的的频率比
较高,但是不能说明这些用户的兴趣点相似,但是如果它们都买了照相机,那么就可以大致推出它们都是摄
影爱好者。所以像卫生纸这样的物品在计算时,相似度权重需要加上惩罚因子或者干脆直接去掉这类数据。
适用场景
对于一个在线网站,用户的数量往往超过物品的数量,同时物品数据相对稳定,因此计算物品的相似度不但
计算量小,同时不必频繁更新。但是这种情况只适用于电子商务类型的网站,像新闻类,博客等这类网站的
系统推荐,情况往往是相反的,物品数量是海量的,而且频繁更新。所以从算法复杂度角度来说,两种算法
各有优势。关于协同过滤的文章,可以参考这里:http://www.tuicool.com/articles/6vqyYfR
3. 协同过滤的实现
上面已经介绍了协同过滤的核心思想,现在就来实战一下吧! 采用数据集如下
链接:http://grouplens.org/datasets/movielens/
这个数据集是很多用户对各种电影的评分。接下来先采用Python实现基于用户的协同过滤算法。
首先,我们需要以表格形式读取数据,需要用到Texttable第三方包。安装包如下链接
链接:https://pypi.python.org/pypi/texttable/
大致用法如下
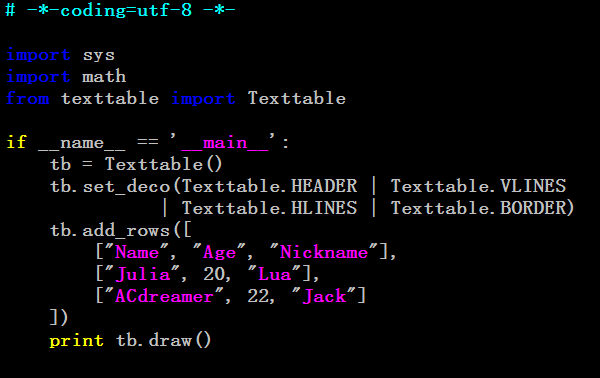
更多方法的使用需要参考Textdtable的源文件texttable.py。接下来可以实现协同过滤算法了。
代码:
- # -*-coding=utf-8 -*-
- import sys
- import math
- from texttable import Texttable
- #计算余弦距离
- def getCosDist(user1, user2):
- sum_x = 0.0
- sum_y = 0.0
- sum_xy = 0.0
- for key1 in user1:
- for key2 in user2:
- if key1[0] == key2[0]:
- sum_x += key1[1] * key1[1]
- sum_y += key2[1] * key2[1]
- sum_xy += key1[1] * key2[1]
- if sum_xy == 0.0:
- return 0
- demo = math.sqrt(sum_x * sum_y)
- return sum_xy / demo
- #读取文件,读取以行为单位,每一行是列表里的一个元素
- def readFile(filename):
- contents = []
- f = open(filename, "r")
- contents = f.readlines()
- f.close()
- return contents
- #数据格式化为二维数组
- def getRatingInfo(ratings):
- rates = []
- for line in ratings:
- rate = line.split("\t")
- rates.append([int(rate[0]), int(rate[1]), int(rate[2])])
- return rates
- #生成用户评分数据结构
- def getUserScoreDataStructure(rates):
- #userDict[2]=[(1,5),(4,2)].... 表示用户2对电影1的评分是5,对电影4的评分是2
- userDict = {}
- itemUser = {}
- for k in rates:
- user_rank = (k[1], k[2])
- if k[0] in userDict:
- userDict[k[0]].append(user_rank)
- else:
- userDict[k[0]] = [user_rank]
- if k[1] in itemUser:
- itemUser[k[1]].append(k[0])
- else:
- itemUser[k[1]] = [k[0]]
- return userDict, itemUser
- #计算与指定用户最相近的邻居
- def getNearestNeighbor(userId, userDict, itemUser):
- neighbors = []
- for item in userDict[userId]:
- for neighbor in itemUser[item[0]]:
- if neighbor != userId and neighbor not in neighbors:
- neighbors.append(neighbor)
- neighbors_dist = []
- for neighbor in neighbors:
- dist = getCosDist(userDict[userId], userDict[neighbor])
- neighbors_dist.append([dist, neighbor])
- neighbors_dist.sort(reverse = True)
- return neighbors_dist
- #使用UserFC进行推荐,输入:文件名,用户ID,邻居数量
- def recommendByUserFC(filename, userId, k = 5):
- #读取文件
- contents = readFile(filename)
- #文件格式数据转化为二维数组
- rates = getRatingInfo(contents)
- #格式化成字典数据
- userDict, itemUser = getUserScoreDataStructure(rates)
- #找邻居
- neighbors = getNearestNeighbor(userId, userDict, itemUser)[:5]
- #建立推荐字典
- recommand_dict = {}
- for neighbor in neighbors:
- neighbor_user_id = neighbor[1]
- movies = userDict[neighbor_user_id]
- for movie in movies:
- if movie[0] not in recommand_dict:
- recommand_dict[movie[0]] = neighbor[0]
- else:
- recommand_dict[movie[0]] += neighbor[0]
- #建立推荐列表
- recommand_list = []
- for key in recommand_dict:
- recommand_list.append([recommand_dict[key], key])
- recommand_list.sort(reverse = True)
- user_movies = [k[0] for k in userDict[userId]]
- return [k[1] for k in recommand_list], user_movies, itemUser, neighbors
- #获取电影的列表
- def getMovieList(filename):
- contents = readFile(filename)
- movies_info = {}
- for movie in contents:
- single_info = movie.split("|")
- movies_info[int(single_info[0])] = single_info[1:]
- return movies_info
- #从这里开始运行
- if __name__ == '__main__':
- reload(sys)
- sys.setdefaultencoding('utf-8')
- #获取所有电影的列表
- movies = getMovieList("u.item")
- recommend_list, user_movie, items_movie, neighbors = recommendByUserFC("u.data", 50, 80)
- neighbors_id=[ i[1] for i in neighbors]
- table = Texttable()
- table.set_deco(Texttable.HEADER)
- table.set_cols_dtype(['t', 't', 't'])
- table.set_cols_align(["l", "l", "l"])
- rows=[]
- rows.append([u"movie name",u"release", u"from userid"])
- for movie_id in recommend_list[:20]:
- from_user=[]
- for user_id in items_movie[movie_id]:
- if user_id in neighbors_id:
- from_user.append(user_id)
- rows.append([movies[movie_id][0],movies[movie_id][1],""])
- table.add_rows(rows)
- print table.draw()
推荐结果如下
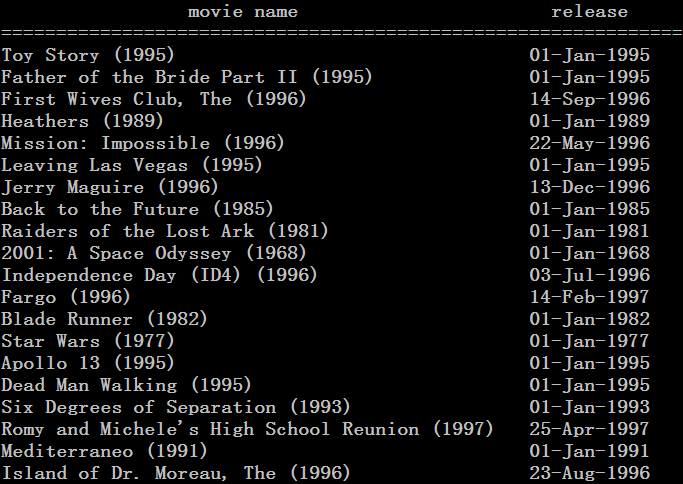
接下来再来看一个题目,这个题目是2014年阿里的大数据竞赛题目,描述可以参考如下链接
题目:http://102.alibaba.com/competition/addDiscovery/gameIntroduce.htm
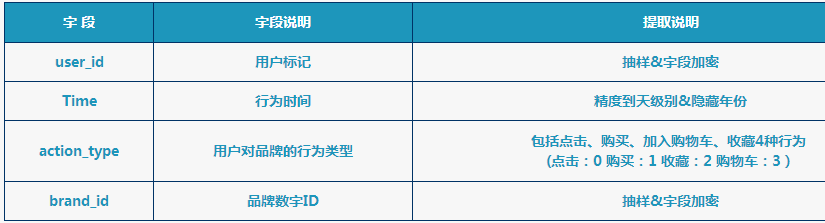
题意:根据用户在天猫的4个月的行为日志,建立用户的品牌偏好,并预测他们在接下来的一个月内对品牌商品的
购买行为。开放的字段类型如下
解析:http://www.tuicool.com/articles/AN7Rf2
上面的是建立的简单的模型,实际上在天猫,有基于行为簇的用户偏好分析。
协同过滤资料















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









