









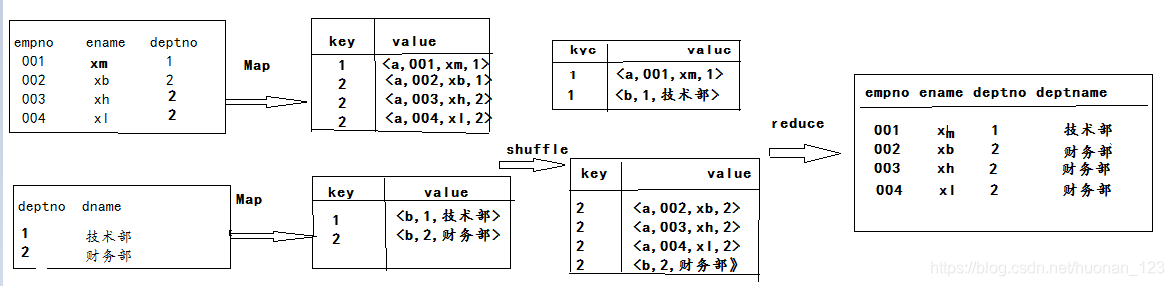
Join
SELECT e.empno,e.ename,e.deptno,d.dname FROM emp e join dept d WHERE e.deptno = d.deptno
- 先对数据进行切分(数据量大)
- 然后执行map操作,map输出<k,v>;k为join条件,v为不同来源的数打上标签,如:emp标签为a,dept标签为b.
- 执行shuffle ,把key相同的拉到一个task里
- reduce计算最终结果输出
Group by
SELECT count(1) FROM emp group by deptno
- 先对数据进行切分(数据量大)
- 执行map操作,转换成<key,value>并打上标签
- 执行shuffle,key相同的数据拉到一个task
- reduce计算输出结果
 SQL执行流程
SQL执行流程
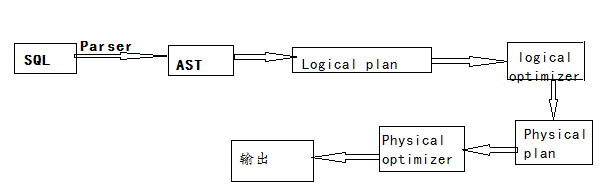
- 根据SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock(QB)
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
SQL语句执行顺序
- map
from–>where(filter)–>select–>group by - reduce
group by -->select
参考:
https://blog.csdn.net/youzhouliu/article/details/70807993#commentBox
https://blog.csdn.net/peixinye/article/details/79587164
https://blog.csdn.net/xyilu/article/details/8996204















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









