







hadoop搭建方式有三种:
Local (Standalone) Mode ——本地模式
Pseudo-Distributed Mode ——伪分布式
Fully-Distributed Mode ——分布式
伪分布式集群的搭建是hadoop入门最先接触的模式:
环境:
jdk:jdk1.7.0_79
hadoop: hadoop-2.5.0需自定义配置的xml文件:
HDFS:core-site.xml,hdfs-site.xml
TARN:yarn-site.xml
MAPREDUCE:mpred-site.xml———-
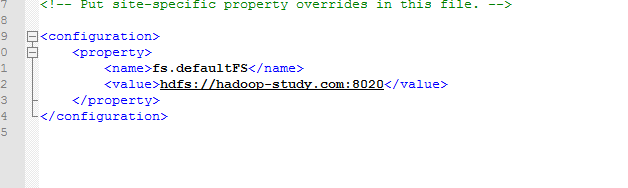
配置文件 hadoop-2.5.0/etc/hadoop/core-site.xml :
设置namenode RPC交互端口,在本机地址
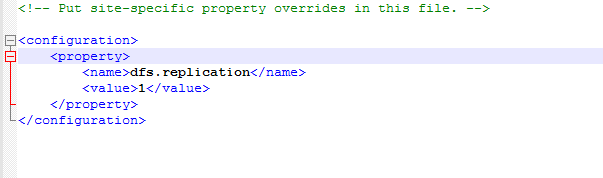
配置文件 hadoop-2.5.0/etc/hadoop/hdfs-site.xml
hdfs数据块的复制份数(备份数据),默认3,但为分布式搭建我们只有一台机器,所以设定为1就可以
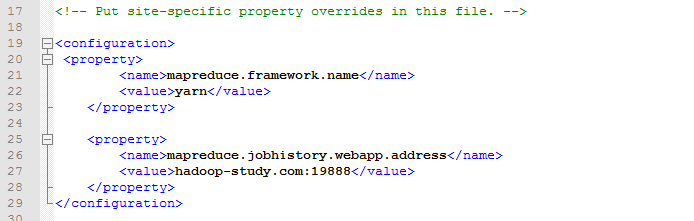
配置文件 hadoop-2.5.0/etc/hadoop/yarn-site.xml

增加配置文件 hadoop-2.5.0/etc/mapred-site.xml
把hdfs加载到yarn上,下面那个是历史端口,,
以上配置信息配置完之后基本就可以启动了
启动hdfs:namenode,datanode,


启动yarn:resourcemanager,namemanager


启动之后使用JPS命令查看

命令出现以下内容就表示启动成功,可以使用
主机名+50070,主机名+8088,,,两个端口来查看web界面
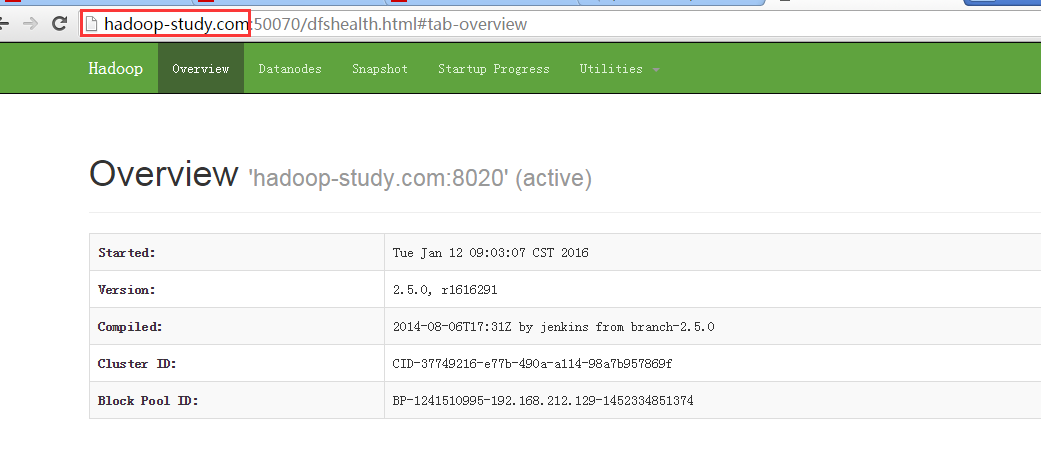

出现以上两个界面说明启动成功,伪分布是搭建成功!
测试:
准备一个本地input文本文件,上传到hadoop,并通过wordcount测试运行查看结果
上传
/opt/datas/wc.input01

通过web可以查看到红线的地址连接的目录都是自己在hdfs中创建的,在这个目录中我们能看到刚才上传到文件wc.input01
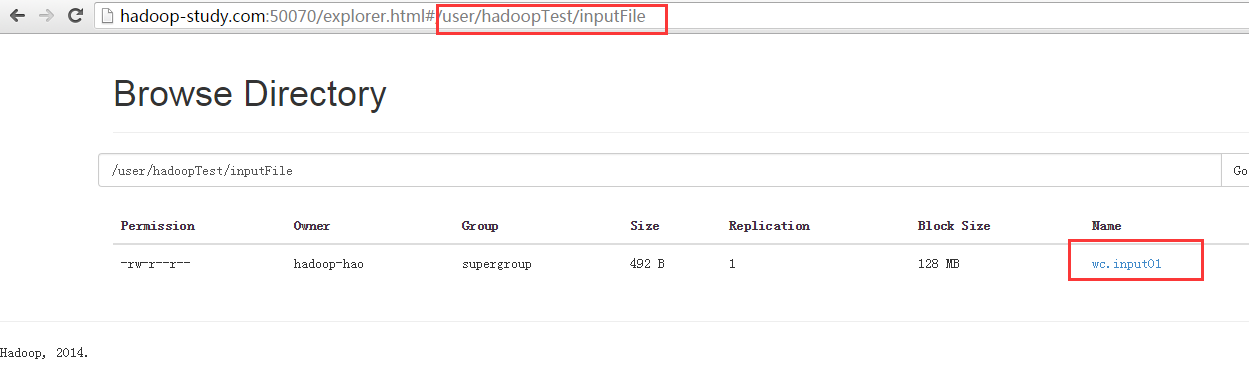
测试
通过以下命令使用worddount来测试运行这个文件,并输出结果到output01的文件中
[hadoop-hao@hadoop-study hadoop-2.5.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/hadoopTest/inputFile/wc.input01 /user/hadoopTest/inputFile/wc.output01
-----------
> [hadoop-hao@hadoop-study hadoop-2.5.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/hadoopTest/inputFile/wc.input01 /user/hadoopTest/inputFile/wc.output01
16/01/12 10:09:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/01/12 10:09:46 INFO client.RMProxy: Connecting to ResourceManager at hadoop-study.com/192.168.212.129:8032
16/01/12 10:09:48 INFO input.FileInputFormat: Total input paths to process : 1
16/01/12 10:09:48 INFO mapreduce.JobSubmitter: number of splits:1
16/01/12 10:09:48 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1452561625006_0001
16/01/12 10:09:49 INFO impl.YarnClientImpl: Submitted application application_1452561625006_0001
16/01/12 10:09:49 INFO mapreduce.Job: The url to track the job: http://hadoop-study.com:8088/proxy/application_1452561625006_0001/
16/01/12 10:09:49 INFO mapreduce.Job: Running job: job_1452561625006_0001
16/01/12 10:10:04 INFO mapreduce.Job: Job job_1452561625006_0001 running in uber mode : false
16/01/12 10:10:04 INFO mapreduce.Job: map 0% reduce 0%
16/01/12 10:10:17 INFO mapreduce.Job: map 100% reduce 0%
16/01/12 10:10:35 INFO mapreduce.Job: map 100% reduce 100%
16/01/12 10:10:36 INFO mapreduce.Job: Job job_1452561625006_0001 completed successfully
16/01/12 10:10:36 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=641
FILE: Number of bytes written=195383
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=622
HDFS: Number of bytes written=491
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11588
Total time spent by all reduces in occupied slots (ms)=14533
Total time spent by all map tasks (ms)=11588
Total time spent by all reduce tasks (ms)=14533
Total vcore-seconds taken by all map tasks=11588
Total vcore-seconds taken by all reduce tasks=14533
Total megabyte-seconds taken by all map tasks=11866112
Total megabyte-seconds taken by all reduce tasks=14881792
Map-Reduce Framework
Map input records=1
Map output records=52
Map output bytes=700
Map output materialized bytes=641
Input split bytes=130
Combine input records=52
Combine output records=36
Reduce input groups=36
Reduce shuffle bytes=641
Reduce input records=36
Reduce output records=36
Spilled Records=72
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=167
CPU time spent (ms)=1940
Physical memory (bytes) snapshot=304365568
Virtual memory (bytes) snapshot=1680384000
Total committed heap usage (bytes)=136450048
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=492
File Output Format Counters
Bytes Written=491注意:输出结果的文件是在运行时系统自行创建的,在运行前不得有相同名的文件
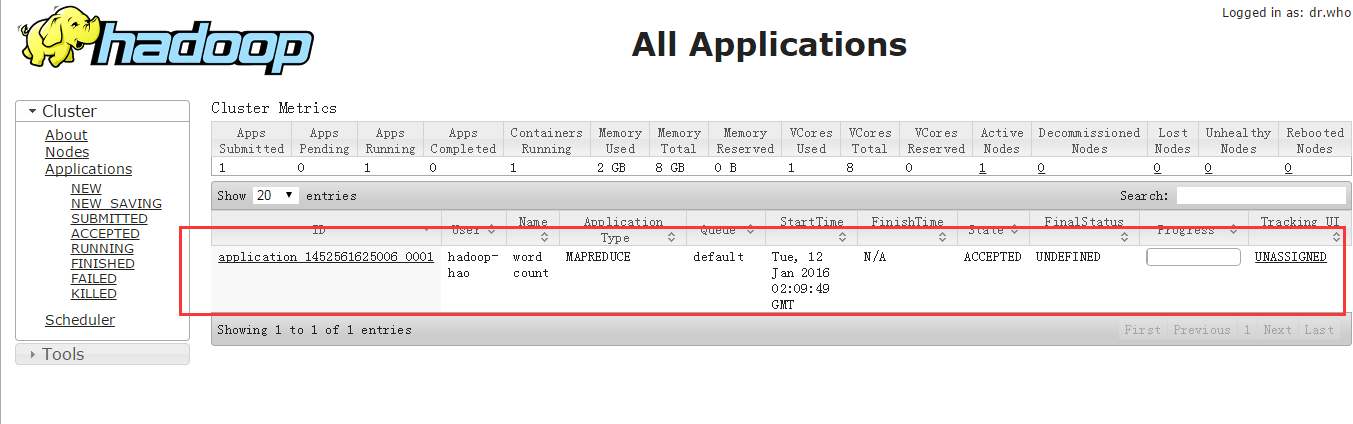
在运行过程中我们可以在yarn的web界面看到进程运行的情况
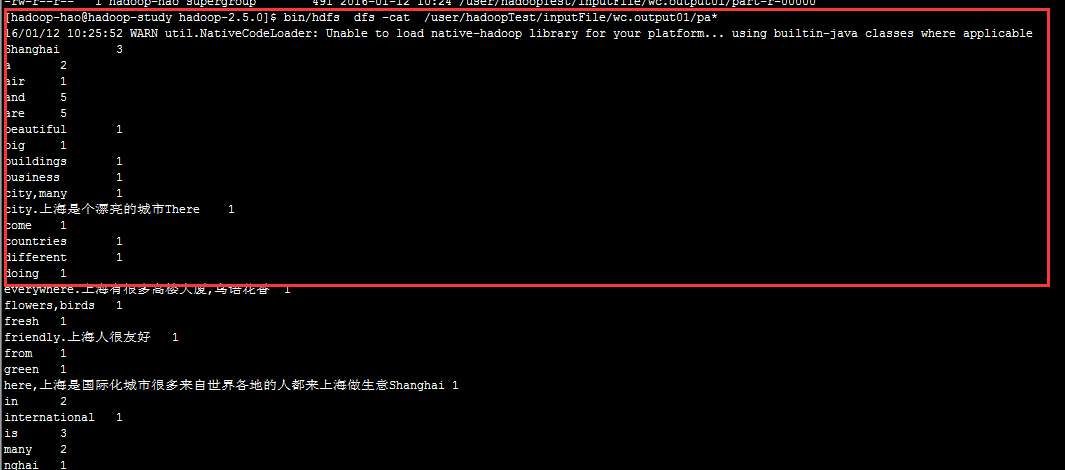
通过bin/hdfs dfs -cat /user/hadoopTest/inputFile/wc.output01/pa*来输出查看结果,我们能看到输出的结果中各单词的数量
以上就是hadoop伪分布式搭建及测试的过程















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









