







学Java的时候也顺便看了一下网上的一个爬虫的源码,感觉看完了收获也很有限,只是大概了解了一下其基本思路:从用户添加的种子URL作为起点,不断请求web页面,然后从页面中提取出新的URL,添加到爬取队列中,其中穿插有URL去重和正则表达式匹配等操作,最后到达指定层数后停止。
之后感觉用这东西去爬爬网页什么的也没什么意思,更多的东西在于用它来做什么应用了,于是也没有深究。
之前去腾讯面试,面试官看了我这个东西,当得知这个东西不是我自己写的之后,也不感兴趣了。当时我就想,难道我要自己写一个这个东西?互联网公司还是比较重视编码能力啊。
后来去面苏州微软,二面、三面面试官都对这个挺感兴趣的。二面面试官问了一个问题,说如果网站禁止爬虫怎么办?我心想,这个我怎么知道啊。幸亏面试官人挺好的(实际上感觉微软面试官都很和蔼可亲!),看我一时不知道怎么回答,就说这个问题只是他个人兴趣,不是面试问题,要我不要紧张。然后告诉我说,一般对于爬虫都会有许可协议的,有些网站对于自己的某些内容可能会禁止爬取,对这种情况有两种解决办法:一是从爬虫上面去解决,二是通过模拟浏览器来访问,因为一个网站是不可能禁止浏览器访问它的。从爬虫上解决的办法没有细说。
没想到在第三面的时候,除了开始问了一点C++和Java的问题之后,面试官好像对于爬虫特别感兴趣,于是和我大量讨论起来,关于怎么提高吞吐量,不断引导我想办法,然后分析有哪些瓶颈,还有没有什么办法。在他的引导下,我大致回答出了开更多的线程(其中还讨论了如何根据各部分负载情况估算线程上限),异步IO,同时写多个数据库,开更多的爬虫机器。然后一一讨论了缺点:带宽受限制,保持数据一致性复杂啦等等。总之面试官很看重你的反应能力,能不能立即想到有哪些解决办法。
看来做技术的人还蛮看重爬虫这一块的,虽然基本思想挺简单的,但其扩展性好,可以扯到多线程,数据库、吞吐量,分布式等很多东西,想想自己以前学习还是太被动了,关于爬虫的一些扩展的东西还是有很多东西可以学的。现在就想读读相关的扩展书籍补充一下。
爬虫和搜索引擎
很好奇爬虫和搜索引擎有什么关系。感觉行为很像但是又不太一样。
书中给出了搜索引擎的架构:
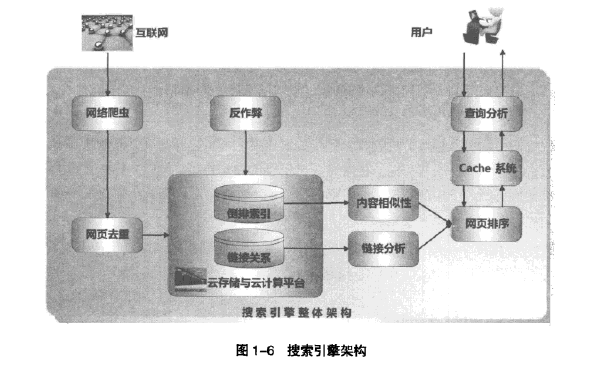
说爬虫是搜索引擎的一个模块,爬虫从互联网上爬取大量的页面然后存储到本地。
搜索引擎要素
相关性、可信赖性、用户需求。
用户需求是说,对于相同的关键字,在不同的场景下用户的实际需求可能是不一样的,如何准确识别的问题。
网络爬虫
有批量型爬虫、垂直型爬虫和增量型爬虫。
爬虫的友好性是说,要准从某些约定:有些网站出于隐私考虑,可能对某些文件夹下的页面不允许抓取;另一方面,过多地对特定网站的爬取会导致网络负载过大,影响正常访问。
因此有网络禁抓协议(Robot Exclusion Protocol),对应根目录下robot.txt, 指明了哪些目录下的网页不允许爬取。还有页面禁抓标记(meta, robots, noindex or nofollow)。另外为了尽量降低对网站负载的影响,减少对单一站点的高频访问。
爬虫的抓取策略
简单来说就是如何对待爬取的URL队列中的元素进行排序。主要有如下几类:
1. 宽度优先搜索策略
最原始的,简单直观的方法,效果还不错。隐含了一定程度上的优先级策略:因为如果入链多的话更有可能会被优先搜索到,因此。
2. 非完全PageRank策略
完整的PageRank策略是基于全网的全局Rank计算得到的,但是在爬取的过程中是不可能获取完整的网页信息的,所以只能根据已经下载到本地的页面进行部分的非完全的PageRank值计算,有一定的效果,但是不一定优于宽搜的方式。
3. OCIP策略(Online Page Importance Computation)
将页面的URL对应的权重均分给页面内的子链,这样动态计算链接的权重。效果不错。
4. 大站优先策略。
网页更新策略
- 基于历史更新周期数据
- 基于用户体验:看网页变化对搜索排名结果的影响,靠前的优先更新。
- 基于聚类分析:对新网页较好,是使用较多的一类。
暗网抓取策略
对于一些根据用户请求动态生成的页面,一些垂直网站比如携程的订票查询页面,需要用户输入一些数据然后才从后台数据库返回对应的页面。这些页面是明网页面数量的上百倍。
爬虫要爬取这些暗网数据,需要解决两个问题:查询组合和文本框输入。
查询组合:遍历所有的查询组合,很多包含的信息量较少,而且会产生巨大的流量压力。基于查找其中富含信息的查询模板,ISIT算法较为有效。
文本框。。。
分布式爬虫
- 主从式爬虫:对URL服务器依赖。
- 对等式爬虫:URL的hash取模法分配对节点损坏问题不能很好解决。采用一致性hash法较好解决此问题。















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









