







目录
1、为什么要用到ELK
早在传统的单体应用时代,查看日志大都通过SSH客户端登服务器去看,使用较多的命令就是 less 或者 tail。如果服务部署了好几台,就要分别登录到这几台机器上看,等到了分布式和微服务架构流行时代,一个从APP或H5发起的请求除了需要登陆服务器去排查日志,往往还会经过MQ和RPC调用远程到了别的主机继续处理,开发人员定位问题可能还需要根据TraceID或者业务唯一主键去跟踪服务的链路日志,基于传统SSH方式登陆主机查看日志的方式就像图中排查线路的工人一样困难,线上服务器几十上百之多,出了问题难以快速响应,因此需要高效、实时的日志存储和检索平台

一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
收集-能够采集多种来源的日志数据 传输-能够稳定的把日志数据传输到中央系统 存储-如何存储日志数据 分析-可以支持 UI 分析 警告-能够提供错误报告,监控机制 ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
2、ELK简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
ElasticSearch是个开源分布式搜索引擎,提供搜索、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析过滤,输出日志的工具,支持大量的数据获取方式。负责将收到的各节点日志进行过滤、修改等操作在一并发往ElasticSearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
Packetbeat(搜集网络流量数据) Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据) Filebeat(搜集文件数据) Winlogbeat(搜集 Windows 事件日志数据)
PS:elasticsearch中文社区:Elastic 中文社区
3、ELK架构图
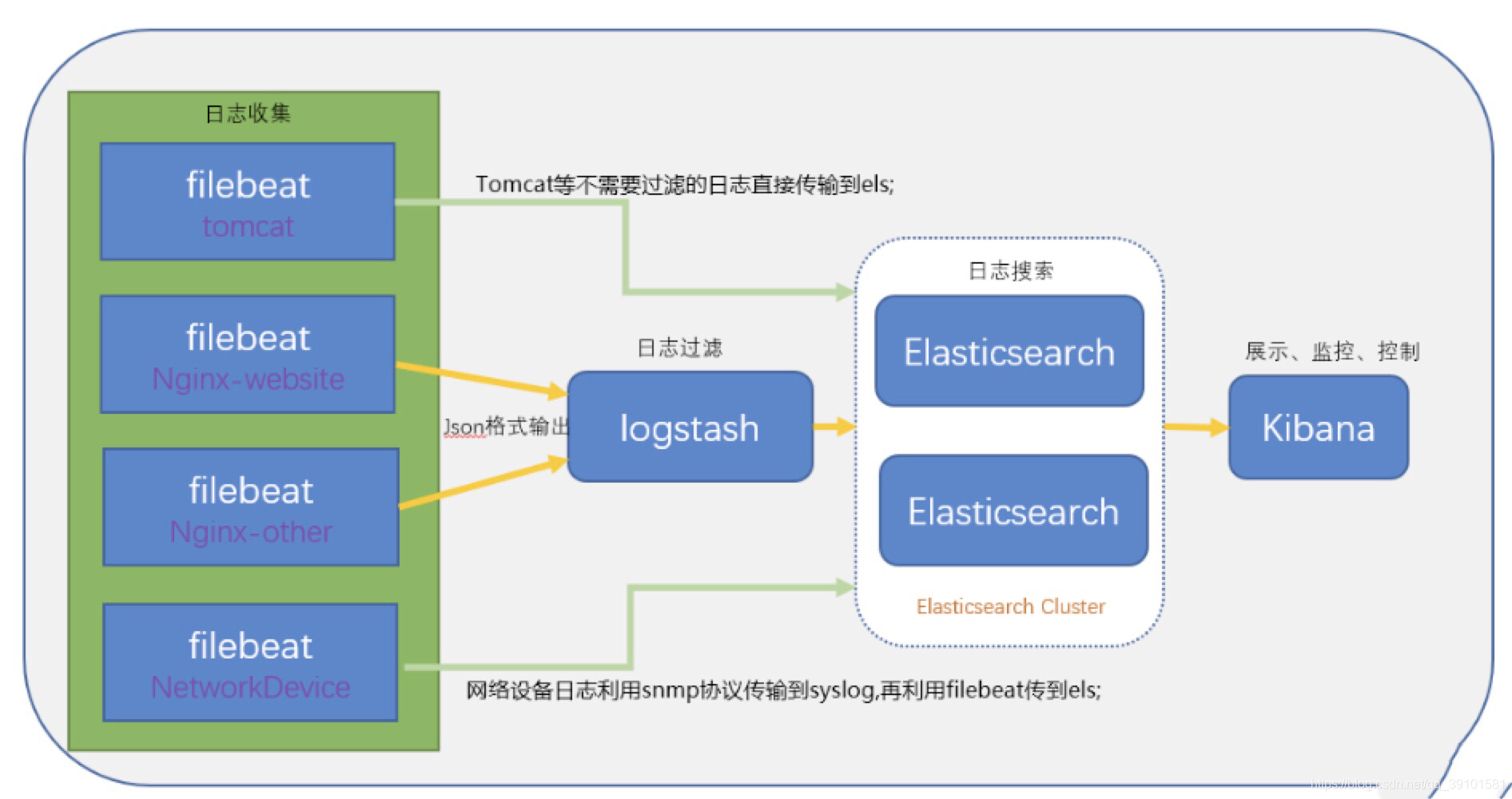
4、ELK安装准备工作
参考:
ElasticSearch基本原理及应用_长沙老码农-CSDN博客
Logstash原理介绍及应用_长沙老码农-CSDN博客_logstash
4.1 ElasticSearch集群搭建
参考:ElasticSearch集群与分片管理_长沙老码农-CSDN博客
4.2 配置LogStash采集nginx日志
我们需要将采集的Nginx日志按照我们希望的格式输出到ElasticSearch,所以我们先定义一个索引模板:
//vim /config/es-index-template.json,输入如下信息:
--------------------------------------------------------------------------------
{
"template": "nginx*", //模糊匹配,对应logstash中配置的index
"order": 1, // elasticsearch 在创建一个索引的时候,如果发现这个索引同时匹配上了多个 template ,那么就会先应用 order 数值小的 template 设置,然后再应用一遍 order 数值高的作为覆盖,最终达到一个 merge 的效果
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "5s"
},
"mappings": {
"properties": {
"host": {
"store": true,
"type": "text"
},
"level": {
"store": true,
"type": "long"
},
"message": {
"analyzer": "ik_max_word",
"store": true,
"type": "text"
},
"type": {
"store": true,
"type": "text"
},
"@timestamp": {
"store": true,
"type": "text"
}
}
}
}
cd logstash-7.8.0/config/
vim config/elk.conf #编辑一个检测脚本文件,输入以下配置
------------------------------------------------------------------
input {
file {
path => "/usr/local/nginx/logs/*.log"
type => "nginx-log"
start_position => "beginning"
}
}
filter{
grok{
match => {"message" => "%{LOGLEVEL:level}"}
}
}
output {
if[level] == "error"{
elasticsearch {
hosts => ["192.168.223.128:9200","192.168.223.129:9200","192.168.223.130:9200"]
index => "nginx-%{+YYYY.MM.dd}"
template => "/usr/local/logstash-7.8.0/config/es-index-template.json"
template_name => "nginx-test"
template_overwrite => true
}
}
}
-------------------------------------------------------------------
#启动服务
cd logstash-7.8.0/
bin/logstash -f config/elk.conf4.3 安装Kibana
#下载kibana安装包,需要与elasticsearch版本保持一致,logstash虽然没有必要,但是也尽量保持一致
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.8.0-x86_64.rpm
yum install -y kibana-7.8.0-x86_64.rpm
#修改配置文件
vim /etc/kibana/kibana.yml
server.port: 5601 #监听端口
server.host: "192.168.223.128" #监听IP地址,建议内网ip
elasticsearch.hosts: ["http://192.168.223.128:9200","http://192.168.223.129:9200","http://192.168.223.130:9200"] #kibana连接elasticsearch的URL:es集群
#启动服务
systemctl daemon-reload
systemctl enable kibana #开机启动
systemctl start kibana #PS:压缩包形式的启动需要添加 --allow-root4.4 服务启动顺序
注意启动顺序,先启动elasticsearch(盘不够内存不够的同学会有点够呛,删除data试试),再启动logstash,最后再启动kibana(很慢哦)
4.4 测试
1)、其实我们已经通过elasticsearch-head可以看到生成了索引数据:

2)、访问kibana控制台:http://192.168.223.128:5601/
一开始我们的kibana并没有添加任何索引的浏览,所以需要手动添加
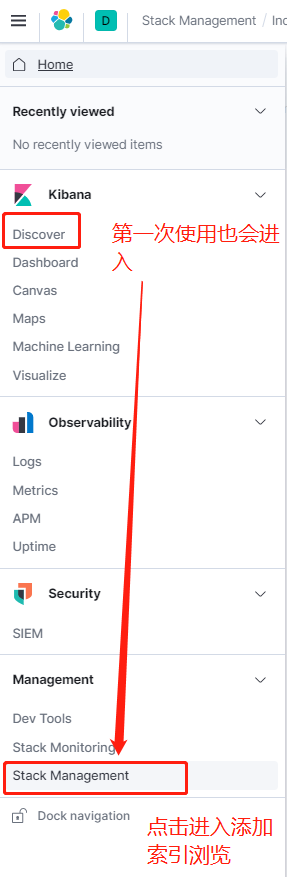



再次进入可以看到索引数据已经可以浏览了!
#现在我们往logstash采集的目录文件写入一些数据,看看能不能采集并且查看到!
echo "hello elk world,我是老胡" >> /usr/local/nginx/logs/test.log
完全没有问题!
4.5 问题
logstash采集过的数据会记录偏移量,如果再次采集,需要删除该信息!

#执行删除:
rm -rf /usr/local/logstash-7.8.0/data/plugins/inputs/file
mkdir /usr/local/logstash-7.8.0/data/plugins/inputs/file
5、Filebeat日志采集
为什么要用filebeat来收集日志?为什么不直接用logstash收集日志?
因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存(这就是为什么logstash启动特别慢的原因),更重要的是LogStash收集日志对业务系统资源的消耗非常大,而filebeat只需要10来M内存资源。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送到logstash,logstash根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch中,通过kibana去展示。
查看命令帮助:
cat /proc/meminfo #查看所有内存情况
top -p 10997 #查看进程占用资源情况适用于集群环境下,服务多,且部署在不同机器
具体架构图可以参照上面的ELK架构图
5.1 filebeat安装配置
wget -c https://download.elastic.co/beats/filebeat/filebeat-1.2.3-x86_64.rpm
rpm -ivh filebeat-1.2.3-x86_64.rpm配置文件位于/etc/filebeat/目录中
默认filebeat的日志是error级别以上才打印,最好改一下
#vim /etc/filebeat/filebeat.yml
filebeat:
prospectors:
paths:
- /usr/local/nginx/logs/*.log #采集的日志路径
encoding: utf-8
input_type: nginx-log
registry_file: /var/lib/filebeat/registry #记录处理进度,防止重复采集,如果你需要重复采集,删除之
output:
logstash:
hosts: ["192.168.223.128:5044"] #输出到logstash地址
logging:
to_syslog: false
to_files: true
files:
rotateeverybytes: 10485760 # 默认的10MB
level: info #日志采集级别修改后,日志文件将位于/var/log/filebeat/
另外要说的是,类似logstash,为了防止重复处理日志,filebeat也会记录处理进度到文件/var/lib/filebeat/registry,为了测试可以先停止filebeat,清空文件registry,然后再启动就会重复处理了
5.2 编写logstash脚本
cd logstash-7.8.0/
vim config/filebeat.conf #输入以下脚本,其实就是改了input
------------------------------------------------------------------------------
input {
beats {
port => 5044
}
}
filter{
grok{
match => {"message" => "%{LOGLEVEL:level}"}
}
}
output {
if[level] == "error"{
elasticsearch {
hosts => ["192.168.223.128:9200","192.168.223.129:9200","192.168.223.130:9200"]
index => "filebeat-%{+YYYY.MM.dd}"
template => "/usr/local/logstash-7.8.0/config/es-index-template.json"
template_name => "nginx-test"
template_overwrite => true
}
}
}
------------------------------------------------------------------------------
#启动logstash
bin/logstash -f config/filebeat.conf5.3 启动filebeat
#删除日志采集移量
rm -rf /var/lib/filebeat/registry
mkdir /var/lib/filebeat/registry
#启动服务
systemctl start filebeat
5.4 效果

看到如下效果即可:(记得关防火墙或者开启端口5044)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









