



文章目录
1 概论
| 命令 | 特点 | 场景 |
|---|---|---|
| grep | 过滤 | grep命令过滤速度是最快的 |
| sed | 替换,修改文件内容,取行 | 进行替换/修改文件内容 取出某个范围的内容 |
| awk | 取列,统计计算 | 取列 对比,比较 >= <= != 统计,计算(awk数组) |
2 grep 指令
| 选项 | 含义 |
|---|---|
| -E | ==egrep 支持正则扩展 |
| -A | after -A3 匹配你要的内容并且显示接下来的3行 |
| -B | before -B3 匹配你要的内容并且显示上面的3行 |
| -C | context -C3 匹配你要的内容并且显示上下3行 |
| -c | 统计出现了多少行,类似于wc -l |
| -v | 取反 排除(行) |
| -n | 显示行号 |
| -i | 忽略大小写 |
| -w | 精确匹配 |
[Tom@hadoop102 hadoop-3.1.3]$ cat cut.txt
guan yu
liu bei
zhang fei
syn quan
zhuge liang
sima yi
ma chao
huang zhong
xu chu
yuan shao
lv bu
chen gong
wei yan
ma teng
jiang wei
[Tom@hadoop102 hadoop-3.1.3]$ cat cut.txt | grep -A3 'sima yi'
sima yi
ma chao
huang zhong
xu chu
[Tom@hadoop102 hadoop-3.1.3]$ cat cut.txt | grep -B3 'sima yi'
zhang fei
syn quan
zhuge liang
sima yi
[Tom@hadoop102 hadoop-3.1.3]$ cat cut.txt | grep -C3 'sima yi'
zhang fei
syn quan
zhuge liang
sima yi
ma chao
huang zhong
xu chu
ps +grep的时候,容易把自己也过滤出来,导致判断进程状态失误,所以需要加入-v来进行排除
[root@hadoop102 hadoop-3.1.3]# ps -ef |grep crond
root 1107 1 0 09:52 ? 00:00:00 /usr/sbin/crond -n
root 5706 5617 0 14:46 pts/0 00:00:00 grep --color=auto crond
[root@hadoop102 hadoop-3.1.3]# ps -ef | grep -c crond
2
[root@hadoop102 hadoop-3.1.3]# pkill crond
[root@hadoop102 hadoop-3.1.3]# ps -ef | grep crond
root 5720 5617 0 14:46 pts/0 00:00:00 grep --color=auto crond
[root@hadoop102 hadoop-3.1.3]# ps -ef | grep -c crond
1
[root@hadoop102 hadoop-3.1.3]# ps -ef | grep crond | grep -v grep | wc -l
0
[root@hadoop102 hadoop-3.1.3]# cat cut2.txt
thank
thankyou
the
thread
ok
yes
[root@hadoop102 hadoop-3.1.3]# cat cut2.txt | grep thank
thank
thankyou
[root@hadoop102 hadoop-3.1.3]# cat cut2.txt | grep -w thank
thank
2 sed 指令
2.1 sed特点及格式
sed stream editor 流编辑器,sed把处理的内容(文件)当做是水,源源不断的进行处理,直到文件末尾
sed格式
| 命令 | 选项 | (s)sed命令功能(g)修饰符 | 参数(文件) |
|---|---|---|---|
| sed | -r | ‘s#word1#word2#g’ | cut.txt |
sed命令核心功能:增删改查
| 功能 | |
|---|---|
| s | 替换substitute |
| p | 显示print |
| d | 删除delete |
| cai | 增加c/a/i |
2.2 sed执行过程
找谁干啥 找谁:要找哪一行;干啥:增删查改
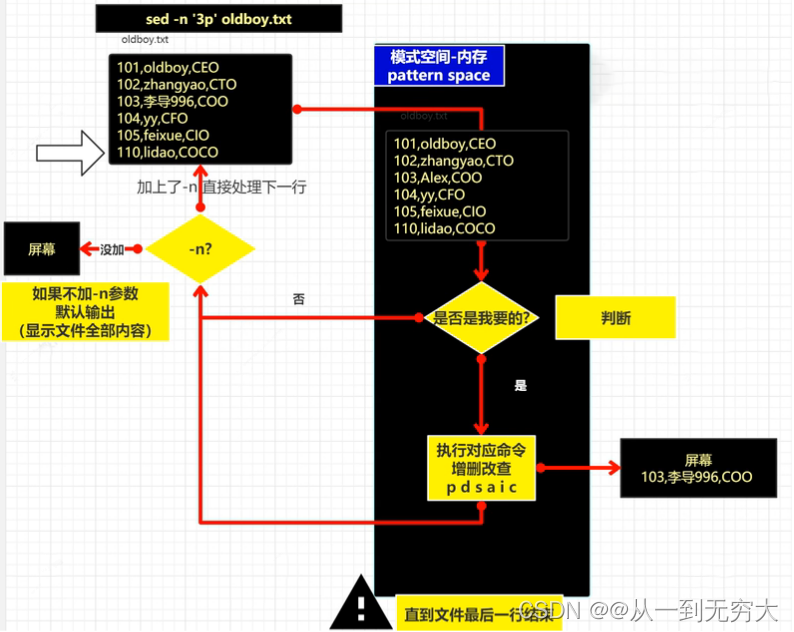
2.3 sed核心应用
(1)sed-查找p
| 查找格式 | |
|---|---|
| ‘3p’ | 指定行号进行查找 |
| ‘1,5p’ | 指定行号范围进行查找 |
| ‘/zhang/p’ | 类似于grep,过滤,//里面可以写正则 |
| ‘/10:00/,/11:00/p’ | 表示范围的过滤 |
| ‘1,/zhang/p’ | 混合 |
[root@hadoop102 hadoop-3.1.3]# sed -n '3p' cut.txt
zhang fei
[root@hadoop102 hadoop-3.1.3]# sed -n '1,5p' cut.txt
guan yu
liu bei
zhang fei
syn quan
zhuge liang
[root@hadoop102 hadoop-3.1.3]# #从第5行到最后1行
[root@hadoop102 hadoop-3.1.3]# sed -n '5,$p' cut.txt
zhuge liang
sima yi
ma chao
huang zhong
xu chu
yuan shao
lv bu
chen gong
wei yan
ma teng
jiang wei
[root@hadoop102 hadoop-3.1.3]# sed -n '/ma/p' cut.txt
sima yi
ma chao
ma teng
表示范围过滤的时候,如果结尾的内容匹配不到就是一直显示到最后一行
(2)sed-删除d
| 删除格式 | |
|---|---|
| ‘3d’ | 指定行号进行删除 |
| ‘1,5d’ | 指定行号范围进行删除 |
| ‘/zhang/d’ | 类似于grep,删除,//里面可以写正则 |
| ‘/10:00/,/11:00/d’ | 表示范围的删除 |
| ‘1,/zhang/d’ | 混合 |
案例:删除文件中的空行和包含井号的行
egrep -v '^$|#' /etc/ssh/sshd_config
sed -r '/^$|#/d' /etc/ssh/sshd_config
# !的妙用
# 遇到空行和#不显示
sed -nr '/^$|#/!p' /etc/ssh/sshd_config
`(3)sed-增加cai
| 命令 | |
|---|---|
| c | replace 代替这行的内容 |
| a | append 追加,向指定的行或每一行追加内容(行后面) |
| i | insert插入,向指定的行或每一行插入内容(行前面) |
[root@hadoop102 hadoop-3.1.3]# cat cut2.txt
thank
thankyou
the
thread
ok
yes
[root@hadoop102 hadoop-3.1.3]# sed '3c sleep' cut2.txt
thank
thankyou
sleep
thread
ok
yes
[root@hadoop102 hadoop-3.1.3]# sed '3a hello' cut2.txt
thank
thankyou
the
hello
thread
ok
yes
[root@hadoop102 hadoop-3.1.3]# sed '3i class' cut2.txt
thank
thankyou
class
the
thread
ok
yes
案例:向config里面追加
UseDNS no
GSSAPIAUTCATION no
PermitRootLogin no
# 方法1:
cat >> config << 'EOF'
UseDNS no
GSSAPIAUTCATION no
PermitRootLogin no
EOF
# 方法2: sed
sed '$a UseDNS no\nGSSAPIAUTCATION no\nPermitRootLogin no' config
(4)sed-替换s
s --> substitute 替换
g --> global 全局替换每行所有匹配的内容,sed默认只替换每行第一个匹配的内容
| 替换格式 |
|---|
| s###g |
| s///g |
| s@@@g |
| 三个相同的字符就行 |
例1:将123456变为<123456>
[root@hadoop102 hadoop-3.1.3]# # 后向引用
[root@hadoop102 hadoop-3.1.3]# echo 123456 | sed -r 's/(.*)/<\1>/g'
<123456>
[root@hadoop102 hadoop-3.1.3]# echo 123456 | sed -r 's#(.*)#<\1>#g'
<123456>
例2: 交换两个单词的位置
将hello world变为world hello
[root@hadoop102 hadoop-3.1.3]# echo hello world | sed -r 's#(^.*) (.*$)#\2 \1#g'
world hello
例3:向文件的每一行末尾添加*****
[root@hadoop102 hadoop-3.1.3]# cat cut2.txt
thank
thankyou
the
thread
ok
yes
[root@hadoop102 hadoop-3.1.3]# sed 's#$#*****#g' cut2.txt
thank*****
thankyou*****
the*****
thread*****
ok*****
yes*****
例4:提取文本中的ip地址
[root@hadoop102 hadoop-3.1.3]# ip a s ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:58:76:92 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.102/24 brd 192.168.10.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::7a43:7c71:c245:f91b/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@hadoop102 hadoop-3.1.3]# ip a s ens33 | sed -n '3p' | sed -r 's#^.*t (.*)/.*$#\1#g'
192.168.10.102
[root@hadoop102 hadoop-3.1.3]# ip a s ens33 | sed -rn '3s#^.*t (.*)/.*$#\1#gp'
192.168.10.102
3 awk 指令
3.1 awk执行过程

3.2 awk之行与列
| 名词 | awk中叫法 | 说明 |
|---|---|---|
| 行 | 记录record | 每一行默认通过回车分割 |
| 列 | 字段, 域, field | 每一列默认通过空格分割 |
| awk中行和列结标记都是可以修改的 |
| 内置变量 | |
|---|---|
| NR | Number of Record 记录号,行号 |
| NF | Number of Field 每行有多个字段(列)$NF表示最后一列 |
| FS | -F: ===-vFS=:字段分隔符,每个字段结束标记 |
| OFS | Out Field Separator 输出字段分隔符(awk显示每一列的时候,每一列之间通过什么分割,默认是空格) |
(1)取行
| awk | |
|---|---|
| NR==1 | 取出第一行 |
| NR>=1 && NR<=5 | 取出第1行到第5行 |
| /101/, /105/ | 取出101到105行的内容 |
| 符号 | > < == >= <= != |
[Tom@hadoop102 hadoop-3.1.3]$ awk 'NR == 2' cut.txt
liu bei
[Tom@hadoop102 hadoop-3.1.3]$ awk 'nr == 2' cut.txt
[Tom@hadoop102 hadoop-3.1.3]$ awk 'NR >= 2 && NR <= 5' cut.txt
liu bei
zhang fei
syn quan
zhuge liang
[Tom@hadoop102 hadoop-3.1.3]$ awk '/liu/,/sima/' cut.txt
liu bei
zhang fei
syn quan
zhuge liang
sima yi
(2)取列
-F 指定分隔符,指定每一列结束标记(默认是空格,连续的空格,tab键)
$数字 取出某一列,
$0表示取整行的内容
$NF表示取最后一列的内容
[Tom@hadoop102 hadoop-3.1.3]$ awk '{print $1}' cut.txt
guan
liu
zhang
syn
zhuge
sima
ma
huang
xu
yuan
lv
chen
wei
ma
jiang
[Tom@hadoop102 hadoop-3.1.3]$ # column -t 表示列对齐
[Tom@hadoop102 hadoop-3.1.3]$ head -5 /etc/passwd |awk -F: '{print $1, $NF}'|column -t
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
[Tom@hadoop102 hadoop-3.1.3]$ head -5 /etc/passwd |awk -F: -vOFS=: '{print $1, $NF}'|column -t
root:/bin/bash
bin:/sbin/nologin
daemon:/sbin/nologin
adm:/sbin/nologin
lp:/sbin/nologin
例:取ip地址
[Tom@hadoop102 hadoop-3.1.3]$ ip a s ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:58:76:92 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.102/24 brd 192.168.10.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::7a43:7c71:c245:f91b/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[Tom@hadoop102 hadoop-3.1.3]$ ip a s ens33 | awk 'NR==3' | awk -F"[ /]+" '{print $3}'
192.168.10.102
[Tom@hadoop102 hadoop-3.1.3]$ ip a s ens33 | awk -F"[ /]+" 'NR==3{print $3}'
192.168.10.102
3.3 awk之模式匹配
| awk | -F"[ /]+" | ‘NR==3{print $3}’ |
|---|---|---|
| 命令 | 选项 | 条件(动作)‘pattern{action}’ |
可以作为awk的条件有:
比较符号:> < >= <= == !=
[Tom@hadoop102 hadoop-3.1.3]$ awk 'NR>=10{print $1}' cut.txt
yuan
lv
chen
wei
ma
jiang
正则表达式:~包含;!~不包含
[Tom@hadoop102 hadoop-3.1.3]$ # 找出第三列以2开头的行,并显示第1列,第3列和最后一列
[Tom@hadoop102 hadoop-3.1.3]$ awk -F: '$3~/^2/{print $1, $3, $NF}' /etc/passwd
daemon 2 /sbin/nologin
rpcuser 29 /sbin/nologin
mysql 27 /bin/false
[Tom@hadoop102 hadoop-3.1.3]$ # 找出第3列以1或2开头的行,并显示第1列,第3列和最后一列
[Tom@hadoop102 hadoop-3.1.3]$ awk -F: '$3~/^[12]/{print $1, $3, $NF}' /etc/passwd | column -t
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
systemd-network 192 /sbin/nologin
abrt 173 /sbin/nologin
rtkit 172 /sbin/nologin
pulse 171 /sbin/nologin
qemu 107 /sbin/nologin
usbmuxd 113 /sbin/nologin
rpcuser 29 /sbin/nologin
huxili 1000 /bin/bash
mysql 27 /bin/false
Tom 1001 /bin/bash
范围表达式
[Tom@hadoop102 hadoop-3.1.3]$ awk '/zhang/,/ma/{print $1}' cut.txt
zhang
syn
zhuge
sima
特殊条件:BEGIN和END
| 模式 | 含义 | 应用场景 |
|---|---|---|
| BEGIN{} | 里面的内容会在awk读取文件之前执行 | 1)进行简单统计,计算,不涉及读取文件 2)用来处理文件之前,添加表头 3)用来定义awk变量 |
| END{} | 里面的内容会在awk读取文件之后执行 | 1)awk进行统计,一般过程:先进行计算,最后END里面输出结果 2)awk使用数组,用来输出结果 |
例1:统计/etc/serivces 里面有多少个空行
[Tom@hadoop102 hadoop-3.1.3]$ #
[Tom@hadoop102 hadoop-3.1.3]$ awk '/^$/' /etc/services | wc -l
17
[Tom@hadoop102 hadoop-3.1.3]$ awk '/^$/{i++}END{print i}' /etc/services
17
例2:求和1+2+…+100
[Tom@hadoop102 hadoop-3.1.3]$ seq 100 | awk '{sum=sum+$1}END{print sum}'
5050
3.4 awk数组
| shell数组 | awk数组 | |
|---|---|---|
| 形式 | array[0] = mary array[1]=jack | array[0] = mary array[1]=jack |
| 使用 | echo ${array[0]} ${array[1]} | print array[0] array[1] |
| 批量输出数组内容 | for i in ${array[*]} do echo $i done | for (i in array) print array[i] |
[Tom@hadoop102 hadoop-3.1.3]$ awk 'BEGIN{a[0]=123;a[1]=you;print a[0],a[1]}'
123
[Tom@hadoop102 hadoop-3.1.3]$ # awk字母会被识别为变量,如果只是想使用字符串需要使用双引号引起来
[Tom@hadoop102 hadoop-3.1.3]$ awk 'BEGIN{a[0]=123;a[1]="you";print a[0],a[1]}'
123 you
例:处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和sohu面试题)
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
[root@hadoop102 hadoop-3.1.3]# awk -F"[./]+" '{array[$2]++}END{for(i in array)print i, array[i]}' url.txt
www 3
mp3 1
post 2
[root@hadoop102 hadoop-3.1.3]# # rnk中r表示逆序,n表示数字,k2表示第2列
[root@hadoop102 hadoop-3.1.3]# awk -F"[./]+" '{array[$2]++}END{for(i in array)print i, array[i]}' url.txt | sort -rnk2
www 3
post 2
mp3 1
3.5 awk循环与判断
例1:统计1+2+3+…+100的和
[root@hadoop102 hadoop-3.1.3]# awk 'BEGIN{for(i=1;i<=100;++i)sum+=i;print sum}'
5050
例2:统计磁盘空间使用率,如果大于50%,则提示磁盘空间不足,并显示磁盘分区,磁盘使用率,磁盘挂载点
[Tom@hadoop102 ~]$ df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 893M 0 893M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 11M 900M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 47G 26G 22G 55% /
/dev/sda1 976M 156M 754M 18% /boot
tmpfs 182M 8.0K 182M 1% /run/user/42
tmpfs 182M 0 182M 0% /run/user/1000
[Tom@hadoop102 ~]$ df -h | awk -F"[ %]+" 'NR>1{if($5>=50) print"disk not enough",$1,$5,$NF}'
disk not enough /dev/mapper/centos-root 55 /
注意:awk使用多个条件的时候,第1个条件可以放在’条件{动作}',第2个条件一般使用if
例3:统计这段语句中,单词中字符数小于6的单词,显示出来
[Tom@hadoop102 ~]$ echo I am math teacher welcome to math training class.|awk -F"[ .]" '{for(i=1;i<=NF;++i)if(length($i)<6) print $i}'
I
am
math
to
math
class
参考: https://www.bilibili.com/video/BV1Kg411g7bC?p=25&spm_id_from=pageDriver

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









