







一、CUDA 的核心作用与技术定位
PyTorch 和 TensorFlow 都是非常流行的深度学习框架,能够高效地利用 GPU 加速深度学习模型的训练过程,提高计算效率。如果在安装有 NVIDIA 显卡的设备运行,且需要 GPU 加速时,通常需要安装CUDA环境。
CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的一种并行计算平台和编程模型,它允许开发者使用 NVIDIA GPU 进行通用计算。深度学习模型(比如卷积神经网络 CNN 和循环神经网络 RNN )的训练和推理过程涉及大量的矩阵运算和并行计算任务,GPU 在处理这些任务时具有显著的速度优势,而 CUDA 为 GPU 加速提供了必要的软件基础,使得 PyTorch 和 TensorFlow 等框架能够调用 GPU 的计算资源。
二、CUDA 生态系统:深度学习的底层加速引擎
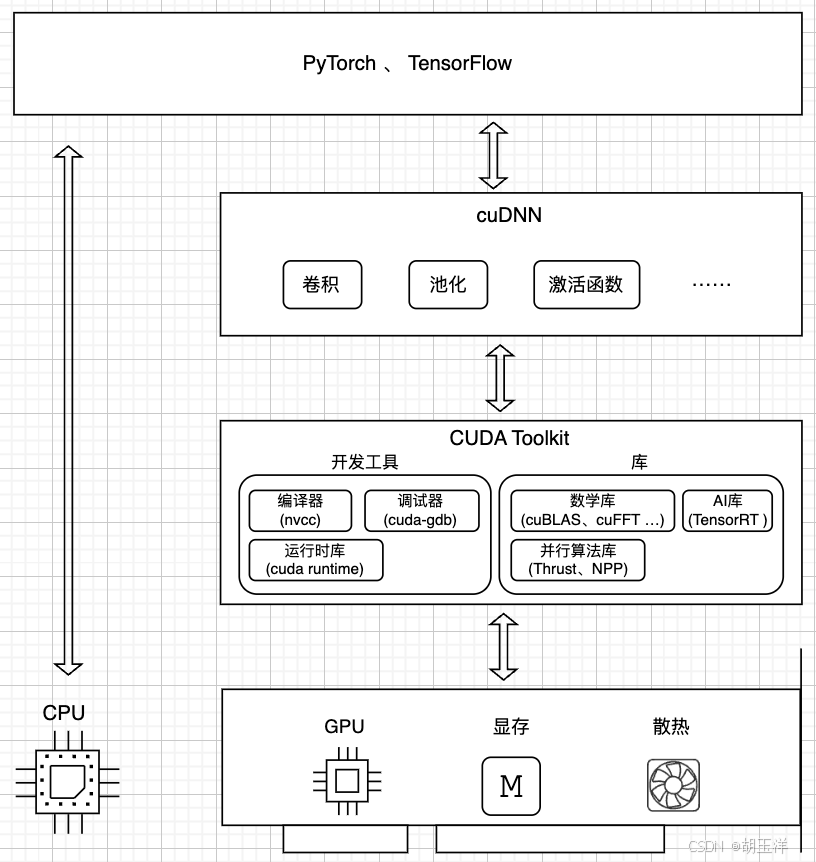
为了更直观地展示CUDA的层次结构,根据理解绘制了如下示意图:
-
上层框架:PyTorch 、 TensorFlow 等框架,通过简洁的 API 封装复杂操作,屏蔽了底层细节,让开发者聚焦模型设计,而底层算力释放则依赖下层技术。比如用PyTorch 定义一个神经网络的线性层只需一行代码:
import torch linear_layer = torch.nn.Linear(10, 2) -
中层加速:cuDNN(CUDA Deep Neural Network library)是基于 CUDA 构建的深度学习库,内置卷积、池化、激活函数等核心操作的优化实现。以图像识别为例,卷积层借助 cuDNN 优化的算法,加速特征提取计算。无论是卷积核与特征图的乘加,还是池化采样,cuDNN 均针对 GPU 架构深度优化,成为框架与算力间的 “性能引擎”。
-
底层工具:CUDA Toolkit 是英伟达 GPU 并行计算的基石,包含:
开发工具:nvcc 编译器将代码转为 GPU 指令;cuda-gdb 调试程序错误;运行时库提供基础交互能力。
功能库:数学库(如 cuBLAS 加速矩阵运算)、AI 库(TensorRT 优化推理)、并行算法库(Thrust 处理并行任务)。训练大规模模型时,cuBLAS 加速矩阵乘法,让计算又快又稳。 -
硬件核心:GPU 专为并行计算设计,架构含大量计算单元(流处理器),适配深度学习的矩阵、张量运算等。当然PyTorch、TensorFlow也可以直接调用CPU资源运算,比如PyTorch通过CPU执行线性层的计算:
x = torch.tensor([1, 2, 3],dtype=torch.float32, device='cpu') linear_layer = torch.nn.Linear(3, 1, device='cpu') output = linear_layer(x)
三、环境准备:运行 GPU 加速的必要条件
如果想在一台电脑上运行PyTorch,并通过英伟达显卡中的GPU来加速,需要的条件如下:
- 操作系统Windows、Linux均支持,macOS自2019年起不再支持NVIDIA GPU驱动,因此无法使用CUDA加速(无论从MacOS系统层面还是从NVIDIA驱动层面,都不再互相支持)。
- 支持CUDA的NVIDIA显卡(如 RTX 系列、GTX 系列、Titan 系列等)。
- 安装 NVIDIA 显卡驱动,显卡驱动是操作系统与 NVIDIA 显卡通信的核心软件,没有驱动,操作系统无法识别显卡,更无法调用 GPU 的计算能力。
- 安装CUDA Toolkit,CUDA 是 NVIDIA 开发的并行计算平台和编程模型,它允许开发者直接调用 GPU 的多个核心进行高性能计算(如矩阵运算、神经网络训练等),CUDA Toolkit中包含GPU变成所需的编译器(nvcc)、数学库(如cuBLAS)、调试工具等。
- 安装cuDNN,cuDNN 是基于 CUDA 构建的深度学习库,专注于卷积、循环神经网络等操作的加速,提供高度优化的算法实现(如卷积的 Winograd 算法),比通用 CUDA 代码快数倍。
- 安装PyTorch,用于实现深度学习等运算。
四、实战指南:CUDA 环境搭建全流程
-
本次用于实验的机器,操作系统为Windows10
-
显卡的型号为 NVIDIA 4060 TI 16G
-
安装 NVIDIA 显卡驱动
在英伟达官网(https://www.nvidia.cn/drivers/lookup/或https://www.nvidia.cn/geforce/drivers/)选择操作系统和显卡型号,下载,根据自己的需求进行自定义安装。
PS:在查找结果(下载)页,如果使用场景除了深度学习外,还经常玩游戏,可以选择GeForce Game Ready Driver。它能在满足深度学习需求的同时,在游戏中也能获得较好的体验,不过但在专业性能优化方面可能不如 NVIDIA Studio。
如果主要将显卡用于深度学习任务,如使用 PyTorch 进行模型训练和推理,更建议选择 NVIDIA Studio。它针对专业计算进行了优化,可能会提供更好的性能和稳定性,有助于提高深度学习工作的效率。而且 NVIDIA Studio 在专业软件的功能支持上可能更完善,能避免一些潜在的兼容性问题。 -
安装CUDA Toolkit
查看 NVIDIA 显卡驱动版本nvidia-smi:
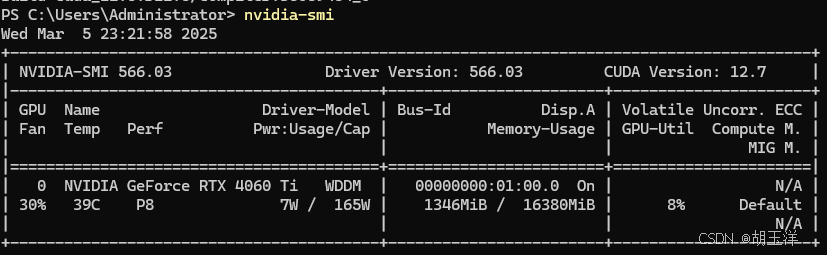 通过nvidia-smi命令查询到 NVIDIA 显卡驱动版本为 566.03。根据 NVIDIA 官方CUDA Toolkit 支持矩阵(https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html),该驱动支持的最高 CUDA 版本为 12.6:
通过nvidia-smi命令查询到 NVIDIA 显卡驱动版本为 566.03。根据 NVIDIA 官方CUDA Toolkit 支持矩阵(https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html),该驱动支持的最高 CUDA 版本为 12.6: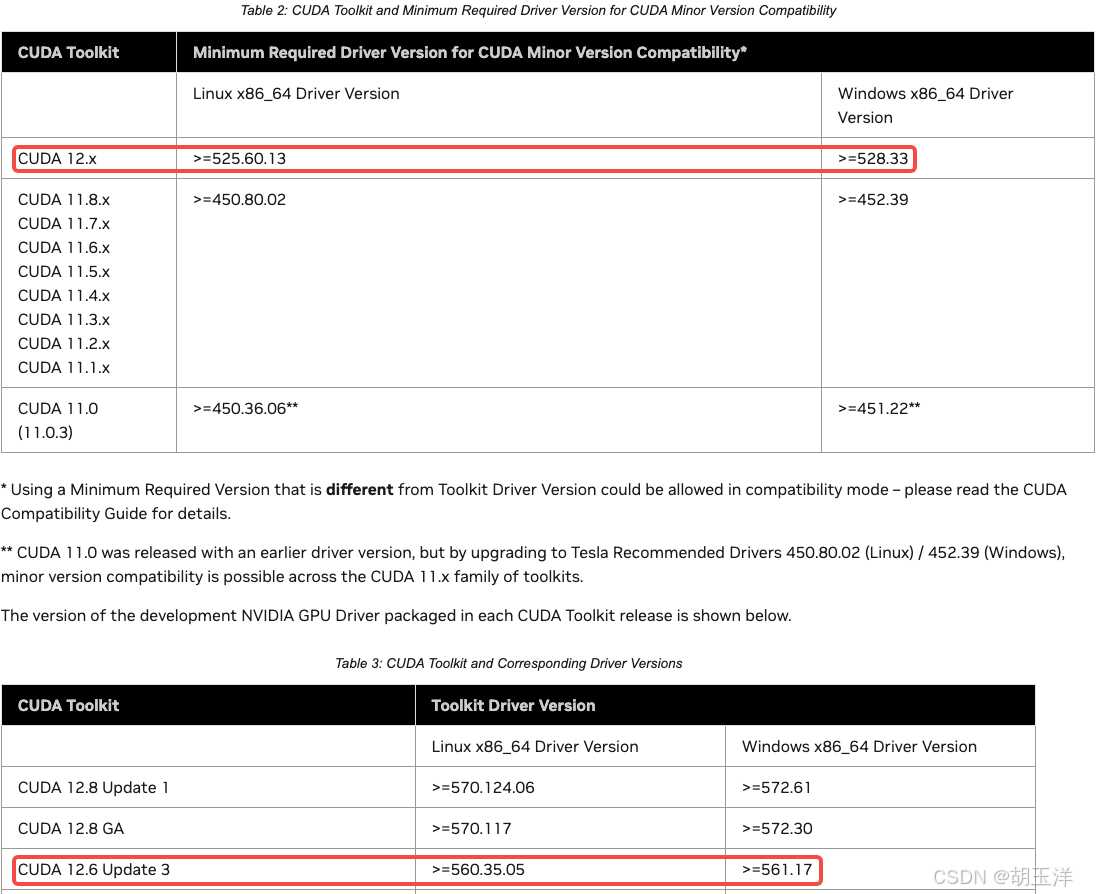
在CUDA工具包下载页面(https://developer.nvidia.com/cuda-toolkit-archive),选择对应的版本(这里选择CUDA Toolkit 12.6.3),然后在下载页面选择操作系统类型、架构、版本和安装包的类型(离线版和在线安装版):
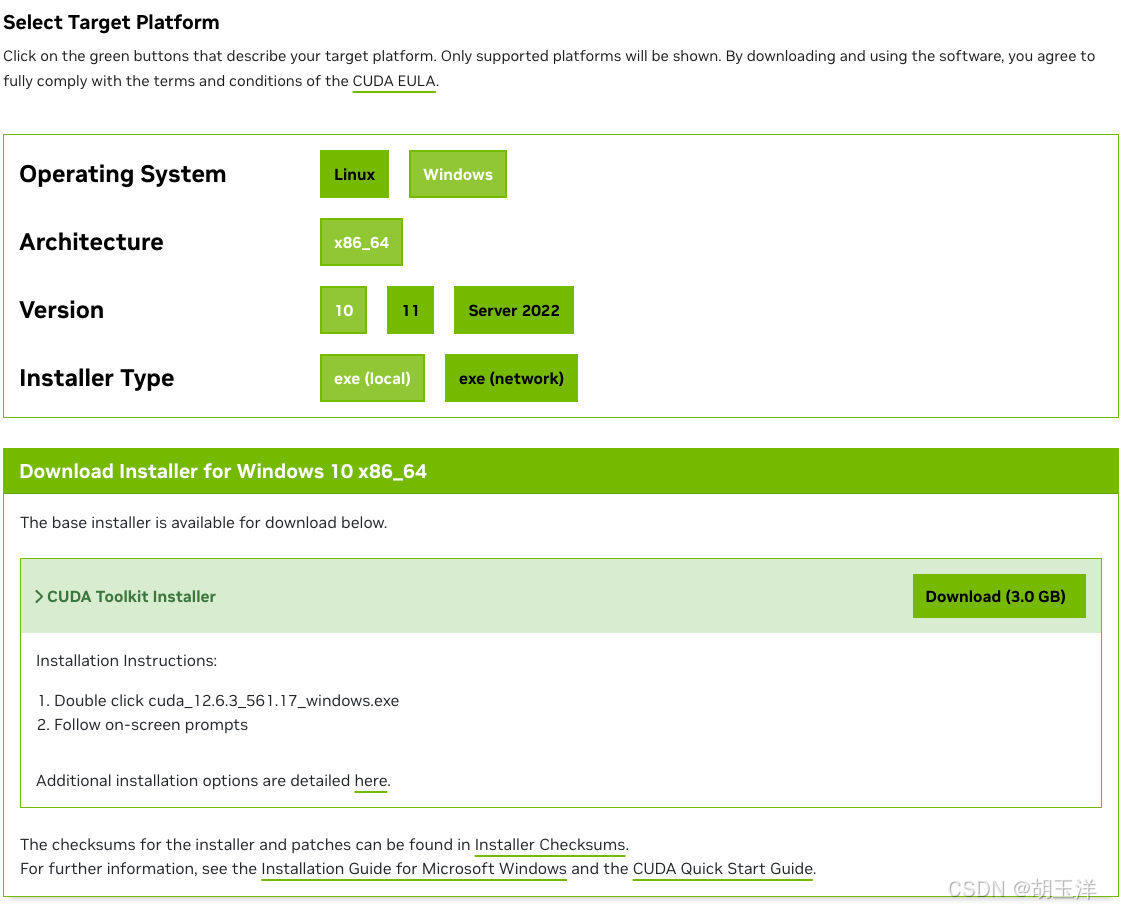
下载离线版本安装包,一步一步安装。
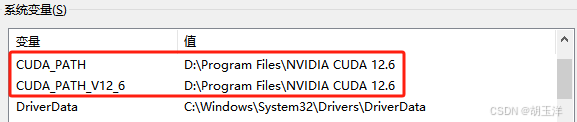
配置环境变量,在系统环境变量中查看是否有如下环境变量,如果没有就添加一下,环境变量的值为安装CUDA时的目录:
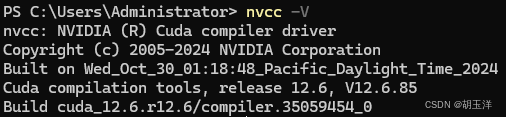
执行nvcc -V检查安装是否成功如果出现如下信息,则安装成功(上面nvidia-smi结果中显示的CUDA版本是驱动支持的最高版本,实际安装版本以nvcc -V结果为准):
-
安装cuDNN
cuDNN 与 CUDA 的版本对应关系可通过NVIDIA 官方文档(https://developer.nvidia.com/cudnn-archive)查询。2023年之前cuDNN的历史版本直接标明了对应的CUDA版本(https://developer.nvidia.com/rdp/cudnn-archive)。这里我下载的是cuDNN 9.6.0,同样选择操作系统类型、架构、版本,下载: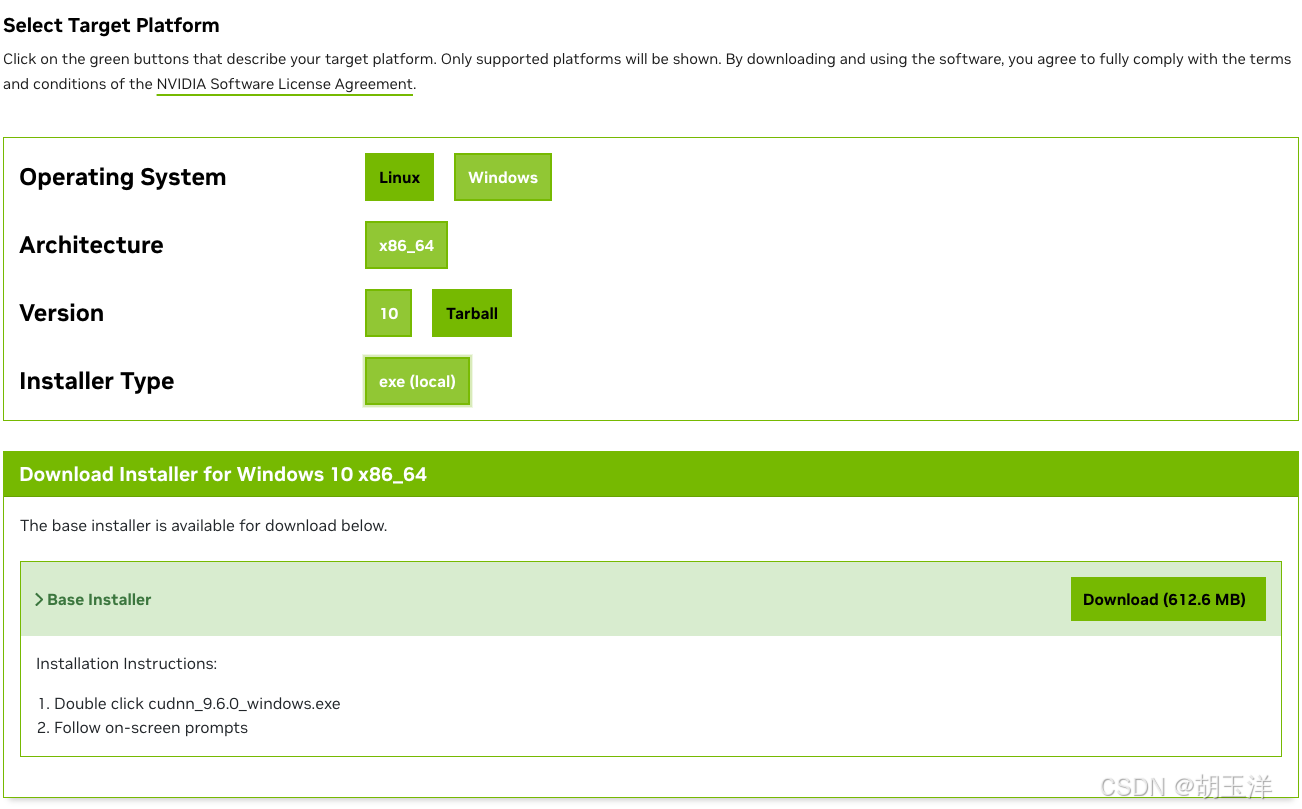
将下载后的压缩包(cudnn-windows-x86_64-9.6.0.74_cuda12-archive.zip)解压后,把lib、include、bin放到CUDA的安装目录下(也就是上面CUDA环境变量的值):
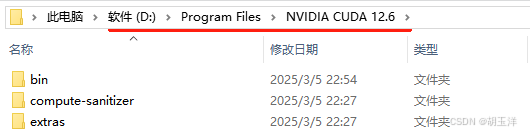
配置cuDNN环境变量,在【系统变量】-【Path】中为bin、libnvvp、lib、include4个文件夹添加环境变量:
检查安装是否成功
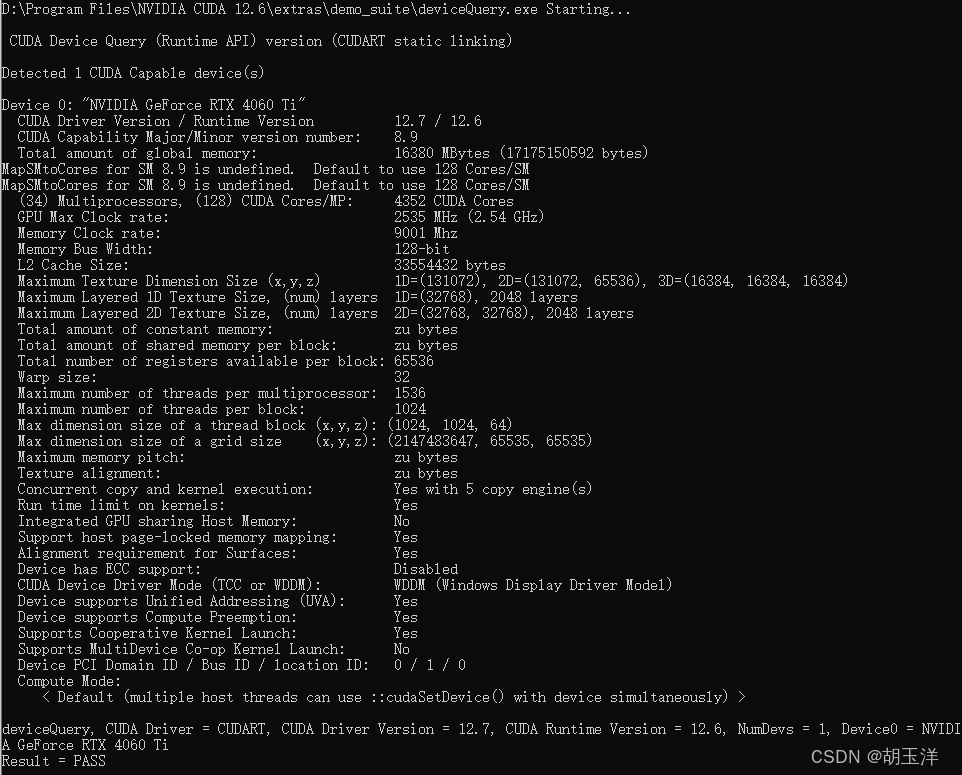
运行D:\Program Files\NVIDIA CUDA 12.6\extras\demo_suite\deviceQuery.exe,如果最下面出现“PASS”则成功:
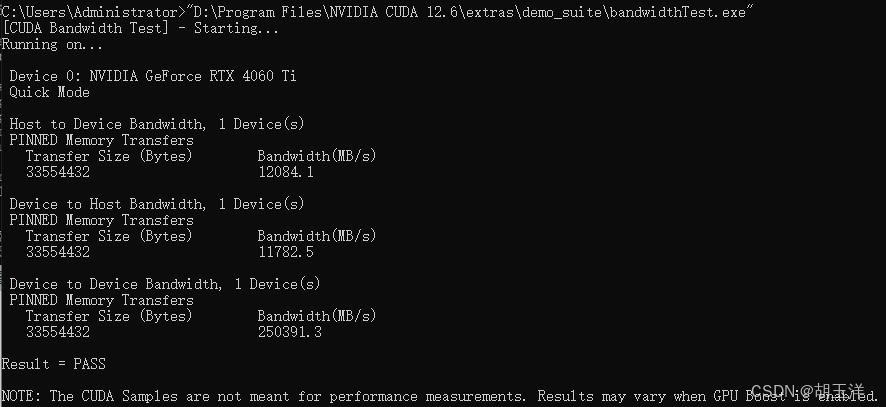
运行D:\Program Files\NVIDIA CUDA 12.6\extras\demo_suite\bandwidthTest.exe,如果最下面出现“PASS”则成功:
-
安装PyTorch,用于实现深度学习等运算可以在PyTorch官方文档(https://pytorch.org/get-started/locally/)中选择对应操作系统、安装方式、CUDA版本等,会自动生成安装命令
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126:
安装后,通过代码查看当前环境是否支持CUDA、CUDA版本、PyTorch版本等:import torch # 查看是否支持CUDA print(f"Support CUDA: {torch.cuda.is_available()}") # CUDA版本 print(f"Version of CUDA: {torch.version.cuda}") # 查看是否支持cuDNN print(f"Support cuDNN: {torch.backends.cudnn.is_available()}") # 查看cuDNN版本 print(f"Version of cuDNN: {torch.backends.cudnn.version()}") # 查看当前PyTorch版本 print(f"Version of PyTorch: {torch.__version__}")执行张量运算:
import torch # 创建两个整数一维张量 x=torch.tensor([1,2,3]) y=torch.tensor([4,5,6]) # 将张量移动到 GPU x=x.to("cuda") y=y.to("cuda") # 执行加法运算 z=torch.add(x,y) print(z)CPU和GPU性能对比:
import torch import time # 性能对比测试 def test_performance(device): x = torch.randn(10000, 10000, device=device) y = torch.randn(10000, 10000, device=device) start_time = time.time() z = torch.mm(x, y) if torch.cuda.is_available(): torch.cuda.synchronize() end_time = time.time() elapsed_time = (end_time - start_time) * 1000 print(f"Device: {device}, Time: {elapsed_time:.2f}ms") test_performance('cpu') test_performance('cuda') #输出 Device: cpu, Time: 2657.83ms Device: cuda, Time: 214.06ms
假如设备上安装的是除英伟达以外其他厂商的显卡,如 AMD、Intel、Apple的部分显卡产品,还能使用 PyTorch 和 TensorFlow 吗?答案是可以的,但在使用方式和性能表现上可能有所不同。比如 PyTorch 要操作 AMD 显卡,需要安装 ROCm 环境;在MacOS系统中,如果需要通过M1芯片中的GPU加速PyTorch,需要依赖MPS……
基于目前各个显卡厂商在深度学习领域的市场份额,NVIDIA还是占主导地位(大约90%),因此CUDA还是主流选择。
| 显卡类型 | 支持框架 | 加速方案 | 性能对比 |
|---|---|---|---|
| NVIDIA | PyTorch/TensorFlow | CUDA/cuDNN | ★★★★★ |
| AMD | PyTorch | ROCm | ★★★☆ |
| Intel | TensorFlow | oneAPI | ★★★☆ |
| Apple | PyTorch | MPS | ★★★☆ |
转载请注明出处《深度学习加速实战:从零搭建PyTorch+CUDA环境全攻略》 https://blog.csdn.net/huyuyang6688/article/details/146196462


















 7847
7847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









