 ClickHouse Mutation 深度解析
ClickHouse Mutation 深度解析





作者:金科_
链接:https://www.jianshu.com/p/8f428293594d
来源:简书
最近研究了一点ch的代码。
发现一个很有意思的词,mutation。
google这个词有突变的意思,但更多的相关文章翻译这个为"订正"。
上一篇文章分析了background_pool_size参数。
这个参数和后台异步工作线程池merge工作有关。
ClickHouse内核中异步merge、mutation工作由统一的工作线程池来完成,这个线程池的大小用户可以通过参数background_pool_size进行设置。线程池中的线程Task总体逻辑如下,可以看出这个异步Task主要做三块工作:清理残留文件,merge Data Parts 和 mutate Data Part。
其实在20.12版本,clickhouse把后台的merge\ttl\mutation都抽象成了job。
MergeTree Mutation功能介绍
ClickHouse内核中的MergeTree存储一旦生成一个Data Part,这个Data Part就不可再更改了。所以从MergeTree存储内核层面,ClickHouse就不擅长做数据更新删除操作。但是绝大部分用户场景中,难免会出现需要手动订正、修复数据的场景。所以ClickHouse为用户设计了一套离线异步机制来支持低频的Mutation(改、删)操作。
Mutation命令执行
ALTER TABLE [db.]table DELETE WHERE filter_expr;
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr;ClickHouse的方言把Delete和Update操作也加入到了Alter Table的范畴中,它并不支持裸的Delete或者Update操作。当用户执行一个如上的Mutation操作获得返回时,ClickHouse内核其实只做了两件事情:
检查Mutation操作是否合法;
保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
两者的主体逻辑分别在MutationsInterpreter::validate函数和StorageMergeTree::mutate函数中。
总结一下:什么操作会触发mutation呢?
答案:alter (alter update 或 alter delete)
我们看看这个后台异步的线程任务调度是怎么玩儿的:
BlockIO InterpreterAlterQuery::execute()
{
BlockIO res;
const auto & alter = query_ptr->as<ASTAlterQuery &>();
...
if (!mutation_commands.empty())
{
//看这里!!
MutationsInterpreter(table, metadata_snapshot, mutation_commands, context, false).validate();
table->mutate(mutation_commands, context);
}startMutation
Int64 StorageMergeTree::startMutation(const MutationCommands & commands, String & mutation_file_name)
{
/// Choose any disk, because when we load mutations we search them at each disk
/// where storage can be placed. See loadMutations().
auto disk = getStoragePolicy()->getAnyDisk();
Int64 version;
{
std::lock_guard lock(currently_processing_in_background_mutex);
MergeTreeMutationEntry entry(commands, disk, relative_data_path, insert_increment.get());
version = increment.get();
entry.commit(version);
mutation_file_name = entry.file_name;
auto insertion = current_mutations_by_id.emplace(mutation_file_name, std::move(entry));
current_mutations_by_version.emplace(version, insertion.first->second);
LOG_INFO(log, "Added mutation: {}", mutation_file_name);
}
//触发异步任务
background_executor.triggerTask();
return version;
}异步任务执行
void IBackgroundJobExecutor::jobExecutingTask()
try
{
auto job_and_pool = getBackgroundJob();
if (job_and_pool) /// If we have job, then try to assign into background pool
{
auto & pool_config = pools_configs[job_and_pool->pool_type];
/// If corresponding pool is not full increment metric and assign new job
if (incrementMetricIfLessThanMax(CurrentMetrics::values[pool_config.tasks_metric], pool_config.max_pool_size))
{
try /// this try required because we have to manually decrement metric
{
pools[job_and_pool->pool_type].scheduleOrThrowOnError([this, pool_config, job{std::move(job_and_pool->job)}] ()
{
try /// We don't want exceptions in background pool
{
job();
/// Job done, decrement metric and reset no_work counter
CurrentMetrics::values[pool_config.tasks_metric]--;
/// Job done, new empty space in pool, schedule background task
runTaskWithoutDelay();
}
catch (...)
{
tryLogCurrentException(__PRETTY_FUNCTION__);
CurrentMetrics::values[pool_config.tasks_metric]--;
scheduleTask(/* with_backoff = */ true);
}
});
/// We've scheduled task in the background pool and when it will finish we will be triggered again. But this task can be
/// extremely long and we may have a lot of other small tasks to do, so we schedule ourselves here.
runTaskWithoutDelay();
}
catch (...)
{
/// With our Pool settings scheduleOrThrowOnError shouldn't throw exceptions, but for safety catch added here
tryLogCurrentException(__PRETTY_FUNCTION__);
CurrentMetrics::values[pool_config.tasks_metric]--;
scheduleTask(/* with_backoff = */ true);
}
}
else /// Pool is full and we have some work to do
{
scheduleTask(/* with_backoff = */ false);
}
}
else /// Nothing to do, no jobs
{
scheduleTask(/* with_backoff = */ true);
}
}可以看到异步任务线程池中的任务执行已经抽象成了job,从后台中load出job进而调度执行。
那么,这些job都是什么呢?接着看:
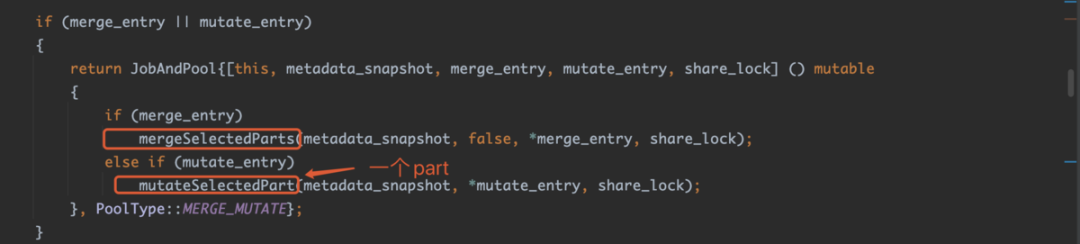
std::optional<JobAndPool> StorageMergeTree::getDataProcessingJob()
{
if (shutdown_called)
return {};
if (merger_mutator.merges_blocker.isCancelled())
return {};
auto metadata_snapshot = getInMemoryMetadataPtr();
std::shared_ptr<MergeMutateSelectedEntry> merge_entry, mutate_entry;
auto share_lock = lockForShare(RWLockImpl::NO_QUERY, getSettings()->lock_acquire_timeout_for_background_operations);
merge_entry = selectPartsToMerge(metadata_snapshot, false, {}, false, nullptr, share_lock);
if (!merge_entry)
mutate_entry = selectPartsToMutate(metadata_snapshot, nullptr, share_lock);
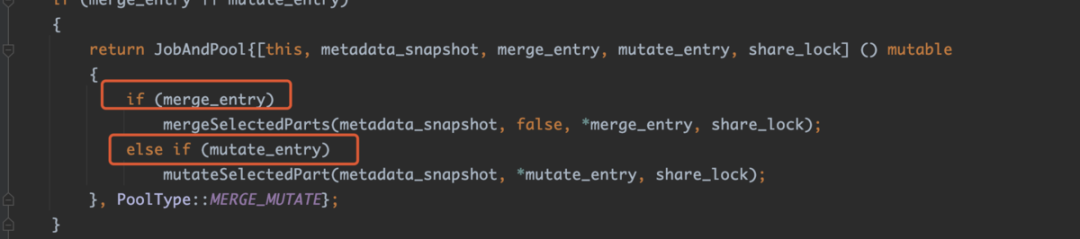
if (merge_entry || mutate_entry)
{
return JobAndPool{[this, metadata_snapshot, merge_entry, mutate_entry, share_lock] () mutable
{
if (merge_entry)
mergeSelectedParts(metadata_snapshot, false, *merge_entry, share_lock);
else if (mutate_entry)
mutateSelectedPart(metadata_snapshot, *mutate_entry, share_lock);
}, PoolType::MERGE_MUTATE};
}
else if (auto lock = time_after_previous_cleanup.compareAndRestartDeferred(1))
{
return JobAndPool{[this, share_lock] ()
{
/// All use relative_data_path which changes during rename
/// so execute under share lock.
clearOldPartsFromFilesystem();
clearOldTemporaryDirectories();
clearOldWriteAheadLogs();
clearOldMutations();
clearEmptyParts();
}, PoolType::MERGE_MUTATE};
}
return {};
}可以看到job有三种类型,一个是常规merge,一个是mutation,一个是清理。
需要清理的残留文件分为三部分:过期的Data Part,临时文件夹,过期的Mutation命令文件。如下方代码所示,MergeTree Data Part的生命周期包含多个阶段,创建一个Data Part的时候分两阶段执行Temporary->Precommitted->Commited,淘汰一个Data Part的时候也可能会先经过一个Outdated状态,再到Deleting状态。在Outdated状态下的Data Part仍然是可查的。异步Task在收集Outdated Data Part的时候会根据它的shared_ptr计数来判断当前是否有查询Context引用它,没有的话才进行删除。清理临时文件的逻辑较为简单,在数据文件夹中遍历搜索"tmp_"开头的文件夹,并判断创建时长是否超过temporary_directories_lifetime。临时文件夹主要在ClickHouse的两阶段提交过程可能造成残留。最后是清理数据已经全部订正完成的过期Mutation命令文件。
enum class State
{
Temporary, /// the part is generating now, it is not in data_parts list
PreCommitted, /// the part is in data_parts, but not used for SELECTs
Committed, /// active data part, used by current and upcoming SELECTs
Outdated, /// not active data part, but could be used by only current SELECTs, could be deleted after SELECTs finishes
Deleting, /// not active data part with identity refcounter, it is deleting right now by a cleaner
DeleteOnDestroy, /// part was moved to another disk and should be deleted in own destructor
};接着说mutation, 既然是异步任务执行,靠的是current_mutations_by_version这个变量,参考如下代码,特别需要注意的是:
current_mutations_by_version是一个map。当这个map不为空的时候,后台mutaion任务被调度到后,就会执行。
std::multimap<Int64, MergeTreeMutationEntry &> current_mutations_by_version;
std::shared_ptr<StorageMergeTree::MergeMutateSelectedEntry> StorageMergeTree::selectPartsToMutate(const StorageMetadataPtr & metadata_snapshot, String */* disable_reason */, TableLockHolder & /* table_lock_holder */)
{
std::lock_guard lock(currently_processing_in_background_mutex);
size_t max_ast_elements = global_context.getSettingsRef().max_expanded_ast_elements;
FutureMergedMutatedPart future_part;
if (storage_settings.get()->assign_part_uuids)
future_part.uuid = UUIDHelpers::generateV4();
MutationCommands commands;
CurrentlyMergingPartsTaggerPtr tagger;
if (current_mutations_by_version.empty())
return {};
auto mutations_end_it = current_mutations_by_version.end();
for (const auto & part : getDataPartsVector())
{
if (currently_merging_mutating_parts.count(part))
continue;
auto mutations_begin_it = current_mutations_by_version.upper_bound(part->info.getDataVersion());
if (mutations_begin_it == mutations_end_it)
continue;
size_t max_source_part_size = merger_mutator.getMaxSourcePartSizeForMutation();
if (max_source_part_size < part->getBytesOnDisk())
{
LOG_DEBUG(log, "Current max source part size for mutation is {} but part size {}. Will not mutate part {}. "
"Max size depends not only on available space, but also on settings "
"'number_of_free_entries_in_pool_to_execute_mutation' and 'background_pool_size'",
max_source_part_size, part->getBytesOnDisk(), part->name);
continue;
}
size_t current_ast_elements = 0;
for (auto it = mutations_begin_it; it != mutations_end_it; ++it)
{
size_t commands_size = 0;
MutationCommands commands_for_size_validation;
for (const auto & command : it->second.commands)
{
if (command.type != MutationCommand::Type::DROP_COLUMN
&& command.type != MutationCommand::Type::DROP_INDEX
&& command.type != MutationCommand::Type::RENAME_COLUMN)
{
commands_for_size_validation.push_back(command);
}
else
{
commands_size += command.ast->size();
}
}
if (!commands_for_size_validation.empty())
{
MutationsInterpreter interpreter(
shared_from_this(), metadata_snapshot, commands_for_size_validation, global_context, false);
commands_size += interpreter.evaluateCommandsSize();
}
if (current_ast_elements + commands_size >= max_ast_elements)
break;
current_ast_elements += commands_size;
commands.insert(commands.end(), it->second.commands.begin(), it->second.commands.end());
}
auto new_part_info = part->info;
new_part_info.mutation = current_mutations_by_version.rbegin()->first;
future_part.parts.push_back(part);
future_part.part_info = new_part_info;
future_part.name = part->getNewName(new_part_info);
future_part.type = part->getType();
tagger = std::make_unique<CurrentlyMergingPartsTagger>(future_part, MergeTreeDataMergerMutator::estimateNeededDiskSpace({part}), *this, metadata_snapshot, true);
return std::make_shared<MergeMutateSelectedEntry>(future_part, std::move(tagger), commands);
}
return {};
}Merge逻辑
StorageMergeTree::merge函数是MergeTree异步Merge的核心逻辑,Data Part Merge的工作除了通过后台工作线程自动完成,用户还可以通过Optimize命令来手动触发。自动触发的场景中,系统会根据后台空闲线程的数据来启发式地决定本次Merge最大可以处理的数据量大小,max_bytes_to_merge_at_min_space_in_pool和max_bytes_to_merge_at_max_space_in_pool参数分别决定当空闲线程数最大时可处理的数据量上限以及只剩下一个空闲线程时可处理的数据量上限。当用户的写入量非常大的时候,应该适当调整工作线程池的大小和这两个参数。当用户手动触发merge时,系统则是根据disk剩余容量来决定可处理的最大数据量。
Mutation逻辑
系统每次都只会订正一个Data Part,但是会聚合多个mutation任务批量完成,这点实现非常的棒。因为在用户真实业务场景中一次数据订正逻辑中可能会包含多个Mutation命令,把这多个mutation操作聚合到一起订正效率上就非常高。系统每次选择一个排序键最小的并且需要订正Data Part进行操作,本意上就是把数据从前往后进行依次订正。
Mutation功能是MergeTree表引擎最新推出一大功能,实现完备度上还有一下两点需要去优化:
1.mutation没有实时可见能力。这里的实时可见并不是指在存储上立即原地更新,而是给用户提供一种途径可以立即看到数据订正后的最终视图确保订正无误。类比在使用CollapsingMergeTree、SummingMergeTree等高级MergeTree引擎时,数据还没有完全merge到一个Data Part之前,存储层并没有一个数据的最终视图。但是用户可以通过Final查询模式,在计算引擎层实时聚合出数据的最终视图。这个原理对mutation实时可见也同样适用,在实时查询中通过FilterBlockInputStream和ExpressionBlockInputStream完成用户的mutation操作,给用户提供一个最终视图。
2.mutation和merge相互独立执行。看完本文前面的分析,大家应该也注意到了目前Data Part的merge和mutation是相互独立执行的,Data Part在同一时刻只能是在merge或者mutation操作中。对于MergeTree这种存储彻底Immutable的设计,数据频繁merge、mutation会引入巨大的IO负载。实时上merge和mutation操作是可以合并到一起去考虑的,这样可以省去数据一次读写盘的开销。对数据写入压力很大又有频繁mutation的场景,会有很大帮助。
对于第2点,这里我们不禁又回想起clickhouse官方文档对于参数background_pool_size的说明:

这里提到了额外的两个参数:
number_of_free_entries_in_pool_to_execute_mutation
number_of_free_entries_in_pool_to_lower_max_size_of_merge
M(UInt64, number_of_free_entries_in_pool_to_lower_max_size_of_merge, 8, "When there is less than specified number of free entries in pool (or replicated queue), start to lower maximum size of merge to process (or to put in queue). This is to allow small merges to process - not filling the pool with long running merges.", 0) \
M(UInt64, number_of_free_entries_in_pool_to_execute_mutation, 10, "When there is less than specified number of free entries in pool, do not execute part mutations. This is to leave free threads for regular merges and avoid \"Too many parts\"", 0) \这两个参数怎么讲?和background_pool_size有什么关联,其实很简单,刚才提到因为后台的merge和mutation是一个线程池来调度的,所以参数number_of_free_entries_in_pool_to_execute_mutation的大概意思,是预留出足够的线程数量去做mutation,如果线程buffer不够,则不执行,这个会尽可能规避too many parts的现象。(侧面说明目前merge工作不繁重,这个值调到合适的水准,会让系统后台尽量优先做merge工作)
std::shared_ptr<StorageMergeTree::MergeMutateSelectedEntry> StorageMergeTree::selectPartsToMutate(const StorageMetadataPtr & metadata_snapshot, String */* disable_reason */, TableLockHolder & /* table_lock_holder */)
{
...
for (const auto & part : getDataPartsVector())
{
if (currently_merging_mutating_parts.count(part))
continue;
auto mutations_begin_it = current_mutations_by_version.upper_bound(part->info.getDataVersion());
if (mutations_begin_it == mutations_end_it)
continue;
//这个函数做了判断
size_t max_source_part_size = merger_mutator.getMaxSourcePartSizeForMutation();
if (max_source_part_size < part->getBytesOnDisk())
{
LOG_DEBUG(log, "Current max source part size for mutation is {} but part size {}. Will not mutate part {}. "
"Max size depends not only on available space, but also on settings "
"'number_of_free_entries_in_pool_to_execute_mutation' and 'background_pool_size'",
max_source_part_size, part->getBytesOnDisk(), part->name);
continue;
}
...
tagger = std::make_unique<CurrentlyMergingPartsTagger>(future_part, MergeTreeDataMergerMutator::estimateNeededDiskSpace({part}), *this, metadata_snapshot, true);
return std::make_shared<MergeMutateSelectedEntry>(future_part, std::move(tagger), commands);
}
return {};
}UInt64 MergeTreeDataMergerMutator::getMaxSourcePartSizeForMutation() const
{
const auto data_settings = data.getSettings();
size_t busy_threads_in_pool = CurrentMetrics::values[CurrentMetrics::BackgroundPoolTask].load(std::memory_order_relaxed);
/// DataPart can be store only at one disk. Get maximum reservable free space at all disks.
UInt64 disk_space = data.getStoragePolicy()->getMaxUnreservedFreeSpace();
/// Allow mutations only if there are enough threads, leave free threads for merges else
if (busy_threads_in_pool <= 1
|| background_pool_size - busy_threads_in_pool >= data_settings->number_of_free_entries_in_pool_to_execute_mutation)
return static_cast<UInt64>(disk_space / DISK_USAGE_COEFFICIENT_TO_RESERVE);
return 0;
}彩蛋
在本文的开头提到:
保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
我们实操看看效果:
xiejinke.local :) ALTER TABLE SignReplacingMergeTreeTest update name='王码子' where id = 15;
ALTER TABLE SignReplacingMergeTreeTest
UPDATE name = '王码子' WHERE id = 15
Query id: 292c6b52-e03d-40e7-8c74-a5750e9b0b54
Ok.
0 rows in set. Elapsed: 20.909 sec.
xiejinke.local :) ALTER TABLE SignReplacingMergeTreeTest update name='王码子333' where id = 15;
ALTER TABLE ReplacingMergeTreeTest
UPDATE name = '王码子333' WHERE id = 15
Query id: c16987b5-8273-44a5-9fd2-5ac68c60a20b
Ok.
0 rows in set. Elapsed: 49.775 sec.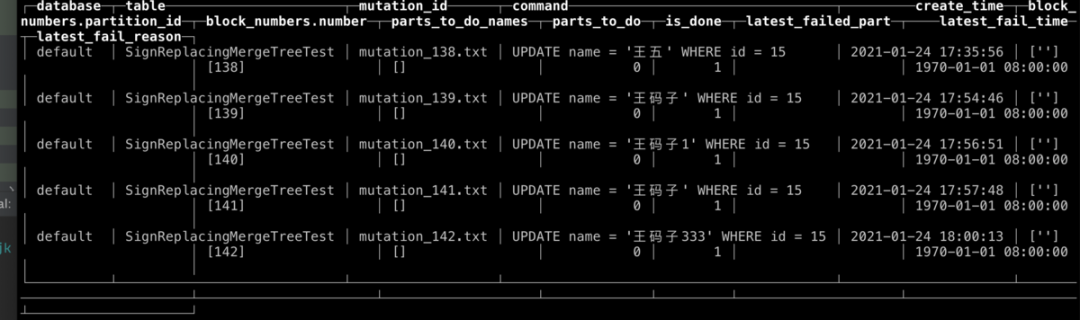
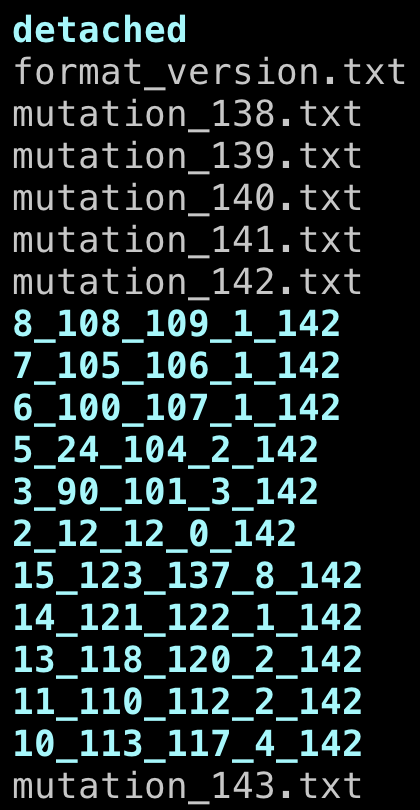
来看看文件:

参考文章:
阿里云:ClickHouse内核分析-MergeTree的Merge和Mutation机制
https://developer.aliyun.com/article/762090?spm=a2c6h.12873581.0.0.29cc802f1GeMHc&groupCode=clickhouse
background_pool_size官方解释:
https://clickhouse.tech/docs/en/operations/settings/settings/#background_pool_size
学习资料
扫描关注“大数据猫”公众号
回复:"clickhouse",即可获得ClickHouse资料合集。



















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









