







就VC而言,汉字储存一般都是以国标码形式存放在电脑上的,要想查询一个汉字的unicode编码,可以在一个字符串前面加一个‘L,也相当于让该汉字以unicode编码形式存放。
unicode编码与utf-8编码之间的关系是什么,其实两者之间,个人感觉,utf-8编码是unicode编码的具体实现。两者之间的对应关系如下所示,可以看到。
- 当一个字符的unicode编码在0x0000 0000~0000 007F之间,utf-8编码以1个字节表示;
- 当一个字符的unicode编码在0x0000 0080~0000 07FF之间,utf-8编码以2个字节表示;
- 当一个字符的unicode编码在0x0800 0000~0000 FFFF之间,utf-8编码以3个字节表示;
- 当一个字符的unicode编码在0x0001 0000~0010 FFFF之间,utf-8编码以4个字节表示;
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx#include<iostream>
void GetUtf8(unsigned short uni)
{
unsigned char utf_8[3];
utf_8[0]=(0xe<<4) | ((uni & 0xf000)>>12);//相当于把二进制1110右移12位
utf_8[1]=(0x2<<6) | ((uni & 0x0fc0)>>6); //相当于把二进制10右移16位
utf_8[2]=(0x2<<6) | (uni & 0x003f); //相当于取二进制低6位
printf("UTF-8编码的第一个字节为0x%.2x\n",utf_8[0]);
printf("UTF-8编码的第一个字节为0x%.2x\n",utf_8[1]);
printf("UTF-8编码的第一个字节为0x%.2x\n",utf_8[2]);
}
void main()
{
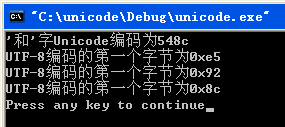
wchar_t str=L'和';
printf("'和'字Unicode编码为%.4x\n",(unsigned short)str);
GetUtf8((unsigned short)str);
}
程序运行的效果图如下:















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









