







 目录【问题背景】【解决方法1:计算空值占比、非空排序最小值,对结果进行映射】【解决方法2:将排序列单独选出来,filter空值后再排序】【解决方法3:进行两次排序,根据两次排序结果计算最终结果】【优缺点对比】【解决方法推荐】【问题背景】假如我们手头上有100w篇文章,想根据阅读量、点赞率对文章进行评分(阅读量>1000时,点赞率才有效)。这里拿5篇文章作为例子...
目录【问题背景】【解决方法1:计算空值占比、非空排序最小值,对结果进行映射】【解决方法2:将排序列单独选出来,filter空值后再排序】【解决方法3:进行两次排序,根据两次排序结果计算最终结果】【优缺点对比】【解决方法推荐】【问题背景】假如我们手头上有100w篇文章,想根据阅读量、点赞率对文章进行评分(阅读量>1000时,点赞率才有效)。这里拿5篇文章作为例子...
目录
【解决方法1:计算空值占比、非空排序最小值,对结果进行映射】
【解决方法2:将排序列单独选出来,filter空值后再排序】
【问题背景】
假如我们手头上有100w篇文章,想根据阅读量、点赞率对文章进行评分(阅读量>1000时,点赞率才有效)。这里拿5篇文章作为例子,构造一个三列的dataFrame:msg_id(文章ID), like_rate(点赞率), read_cnt(阅读量),取值为:
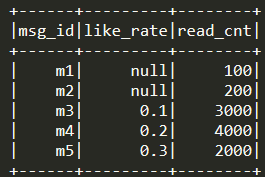
对like_rate进行percent_rank(),从文章m1到m5,
期望的结果是:null, null, 0.0, 0.5, 1.0
实际的结果是:0.0, 0.0, 0.5, 0.75, 1.0
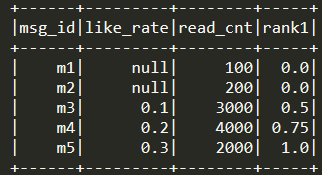
空值也参与到排序里面去了,得不到预期的结果。如果99%的文章的点赞率字段都为空,会使得有点赞率的文章的点赞率排序结果挤在[0.99, 1.0],没点赞率的文章得分全为0,不同点赞率的文章得分没有区分性。附上此例子代码:
package high_quality._history
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
object test {
def main(args: Array[String]) {
Logger.getRootLogger.setLevel(Level.ERROR)
val spark = SparkSession.builder().master("local[*]").getOrCreate()
import spark.implicits._
var df = Seq(("m1", 0.4, 100), ("m2", 0.5, 200), ("m3", 0.1, 3000), ("m4", 0.2, 4000), ("m5", 0.3, 2000))
.toDF("msg_id", "like_rate", "read_cnt")
.withColumn("like_rate", when($"read_cnt" > 1000, $"like_rate"))
.withColumn("rank1", percent_rank().over(Window.orderBy("like_rate")))
df.orderBy("msg_id").show()
}
}【解决方法1:计算空值占比、非空排序最小值,对结果进行映射】
看完上述例子,相信大家都能想到:将得分为0的文章,得分改为0.5;将得分>0的文章,通过 (x-0.99) / (1 - 0.99)的方式便能映射到[0, 1]区间上。
问题的关键就是要知道非空的数据量有多大,可以计算点赞率非空的数据的最小排序取值,也可以直接统计取值为空的数据量:
(1)计算点赞率非空数据的最小取值
df.persist()
// 计算点赞率非空数据的排序最小值
val min_rank_like_rate = df
.withColumn("tmp_rank", when($"rank1" > 0, $"rank1"))
.select(min("tmp_rank")).rdd.collect()(0)(0).toString.toDouble
// 取值缩放
df = df
.withColumn("rank2", when($"rank1" === 0, 0.5).
otherwise(($"rank1" - min_rank_like_rate) / (1 - min_rank_like_rate)))
df.show() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









